Tổng quan về Khoa học dữ liệu là bước khởi đầu quan trọng giúp sinh viên ngành lập trình và AI hiểu được bức tranh toàn cảnh trước khi đi sâu vào kỹ thuật cụ thể. Trong thời đại dữ liệu bùng nổ, việc nắm được nền tảng lý thuyết, vai trò của dữ liệu và cách tổ chức dữ liệu trong hệ quản trị cơ sở dữ liệu là điều kiện tiên quyết để phát triển năng lực phân tích và xây dựng hệ thống thông minh.
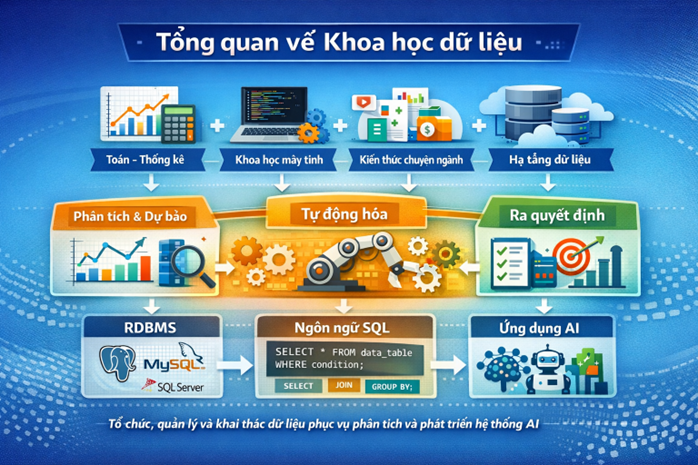
1. Khoa học dữ liệu là gì?
Khoa học dữ liệu (Data Science) là một lĩnh vực liên ngành, bao gồm bốn trụ cột chính:
• Toán – thống kê: giúp đo lường, suy luận, kiểm định và xây dựng mô hình dự đoán.
• Khoa học máy tính: giúp xây dựng thuật toán, xử lý dữ liệu lớn, tối ưu hiệu năng và triển khai hệ thống.
• Kiến thức chuyên ngành: giúp hiểu ý nghĩa dữ liệu trong bối cảnh thực tế (y tế, tài chính, logistics…).
• Hạ tầng và tổ chức dữ liệu (Data Infrastructure): bao gồm cơ sở dữ liệu, hệ thống lưu trữ và quản lý dữ liệu – nơi dữ liệu được lưu trữ, tổ chức và truy vấn một cách có hệ thống.
2. Vai trò của khoa học dữ liệu trong thực tế
Trong thời đại dữ liệu, tổ chức nào khai thác dữ liệu tốt hơn sẽ có lợi thế cạnh tranh lớn hơn. Khoa học dữ liệu giúp biến dữ liệu thành cơ sở khoa học cho quyết định và chiến lược. Có thể tóm lược vai trò của KHDL thành bốn nhóm chính:
(1) Hỗ trợ ra quyết định dựa trên dữ liệu (Data-driven decision making)
Thay vì dựa vào cảm tính, doanh nghiệp và tổ chức có thể:
- Phân tích dữ liệu để lựa chọn chiến lược phù hợp
- Dự đoán xu hướng thị trường
- Hiểu hành vi và nhu cầu khách hàng
- Đánh giá hiệu quả hoạt động và tối ưu chi phí
Khoa học dữ liệu giúp chuyển từ “ra quyết định theo kinh nghiệm” sang “ra quyết định dựa trên bằng chứng”.
(2) Khám phá mô hình và tri thức ẩn trong dữ liệu
Dữ liệu thô thường không tự thể hiện ý nghĩa rõ ràng. Thông qua phân tích và mô hình hóa, ta có thể phát hiện:
- Các mẫu (patterns) lặp lại (Ví dụ: khách hàng thường mua kèm sản phẩm A với sản phẩm B…)
- Xu hướng theo thời gian (Ví dụ: doanh thu tăng mạnh vào cuối năm; lượng truy cập giảm dần sau khi thay đổi giao diện website///)
- Mối quan hệ giữa các biến (Ví dụ: thời gian giao hàng càng lâu thì tỷ lệ khách hàng quay lại càng thấp…)
- Những yếu tố có ảnh hưởng mạnh đến kết quả (ví dụ: yếu tố làm giảm doanh thu, gây lỗi sản phẩm…)
Đây là bước chuyển từ “có dữ liệu” sang “hiểu dữ liệu”.
(2) Phát hiện mô hình và xu hướng ẩn
Dữ liệu lớn thường “không tự nói ra điều gì”, nhưng trong đó có thể tồn tại:
- các mẫu lặp lại,
- xu hướng theo thời gian,
- yếu tố ảnh hưởng mạnh đến kết quả (ví dụ: yếu tố làm doanh thu giảm, hay yếu tố gây lỗi sản phẩm…).
(3) Tự động hóa và tối ưu hóa hệ thống
Khi đã xây dựng được mô hình phù hợp, hệ thống có thể:
- Tự động dự đoán (nhu cầu, rủi ro, hành vi người dùng…)
- Tối ưu phân bổ nguồn lực, tức là dùng dữ liệu và mô hình để quyết định phân bổ tiền, nhân sự, thời gian, hàng hóa… sao cho hiệu quả nhất.
- Giảm sai sót và tăng hiệu suất vận hành, tức là dùng dữ liệu để giảm lỗi do con người hoặc quy trình thủ công, đồng thời làm hệ thống chạy hiệu quả hơn.
Ở mức cao hơn, các mô hình có thể được tích hợp trực tiếp vào sản phẩm hoặc hệ thống sản xuất, tạo ra các quyết định tự động theo thời gian thực.
(4) Thúc đẩy nghiên cứu và đổi mới sáng tạo
Khoa học dữ liệu là nền tảng cho:
- Nghiên cứu khoa học hiện đại (y sinh, khí hậu, vật liệu, AI…)
- Phát triển sản phẩm và dịch vụ mới
- Cải tiến công nghệ dựa trên phân tích dữ liệu thực nghiệm
Trong bối cảnh AI phát triển mạnh, dữ liệu chính là “nguyên liệu” cho các mô hình thông minh.
3. Ứng dụng khoa học dữ liệu trong các lĩnh vực
Một số ứng dụng của khoa học dữ liệu trong các lĩnh vực chính:
- Y tế: hỗ trợ chẩn đoán, cá nhân hóa điều trị, theo dõi dịch bệnh, tối ưu quy trình bệnh viện…
- Tài chính: đánh giá rủi ro, phát hiện gian lận, tự động hóa quyết định giao dịch…
- Thương mại điện tử & Marketing: gợi ý sản phẩm, phân nhóm khách hàng, dự đoán xu hướng, định giá động…
- Giao thông & logistics: tối ưu tuyến đường, quản lý chuỗi cung ứng, phát hiện hỏng hóc sớm…
- Năng lượng & môi trường: dự báo khí hậu, cân bằng cung cầu điện, dự đoán sản lượng năng lượng tái tạo…
- Giáo dục: cá nhân hóa học tập, chấm bài – phản hồi tự động…
- Nông nghiệp: tối ưu tưới/bón, giám sát sâu bệnh, dự đoán sản lượng…
- An ninh & pháp luật: giám sát an ninh, phát hiện thông tin giả, phân tích bằng chứng số…
- Sản xuất: dự đoán bảo trì, kiểm soát chất lượng…
Điều rút ra: dữ liệu ở đâu thì khoa học dữ liệu có đất dụng võ ở đó.
4. Các loại dữ liệu
Có hai loại dữ liệu chính : dữ liệu có cấu trúc và dữ liệu không có cấu trúc.
Dữ liệu có cấu trúc (Structured Data)
Là các loại dữ liệu có đặt tính sau:
- có schema rõ ràng (tức có tên, kiểu dữ liệu, ràng buộc… được định nghĩa trước)
- có dạng bảng hàng/cột ổn định,
Ví dụ:
- Dữ liệu trong các file CSV có header,
- Dữ liệu trong các file Excel có cột hàng rõ ràng,
- Dữ liệu JSON có cấu trúc ổn định
Dữ liệu không có cấu trúc (Unstructured Data)
Là dữ liệu:
- không theo schema cố định,
- “tự do” về định dạng,
Ví dụ:
- văn bản tự do (email, tài liệu, bài báo),
- hình ảnh, video, âm thanh,
- bài đăng mạng xã hội,
- log hệ thống (nhiều khi là bán cấu trúc).
Điểm mấu chốt: dữ liệu không có cấu trúc chiếm phần lớn ngoài đời thực, nhưng để phân tích được thường phải trích xuất đặc trưng bằng NLP/Computer Vision… rồi mới đưa về dạng có cấu trúc.
5. Cơ sở dữ liệu quan hệ (RDB) và hệ quản trị CSDL quan hệ (RDBMS)
Cơ sở dữ liệu quan hệ (RDB) là gì?
RDB là dữ liệu được tổ chức theo mô hình quan hệ:
- dữ liệu nằm trong bảng,
- mỗi bảng có hàng (record/tuple) và cột (field/attribute),
- các bảng liên kết nhau qua khóa:
- Primary Key: định danh duy nhất mỗi dòng
- Foreign Key: tham chiếu sang bảng khác để tạo quan hệ
Ví dụ trực quan:
- bảng customers(id, name, phone)
- bảng orders(id, customer_id, date)
Trong đó orders.customer_id tham chiếu customers.id.
RDBMS là gì?
RDBMS (Relational Database Management System) là phần mềm quản trị CSDL quan hệ, cung cấp:
- tạo/quản lý cấu trúc (bảng, khóa, chỉ mục),
- thêm/sửa/xóa dữ liệu,
- đảm bảo toàn vẹn & nhất quán (ACID),
- phân quyền và bảo mật…
Ví dụ các RDBMS phổ biến: PostgreSQL, MySQL, Oracle, SQL Server…
Lưu ý quan trọng (hay bị nhầm): pgAdmin, DataGrip, phpMyAdmin… là công cụ giao diện/IDE, không phải RDBMS. Chúng giống như “bảng điều khiển” giúp thao tác dễ hơn.
Một số RDMMS phổ biến:
- PostgreSQL: là hệ quản trị dữ liệu mã nguồn mở, rất mạnh, hỗ trợ nhiều kiểu dữ liệu, thường dùng trong phân tích dữ liệu, thường dùng trong các hệ thống cần độ tin cậy cao.
- MySQL: là hệ quản trị dữ liệu nguồn mở, miễn phí, dễ cài đặt, tốc độ nhanh, thường dùng trong hệ thống web vừa/nhỏ.
- Oracle Database: là hệ quản trị thương mại mạnh, bảo mật tốt, giá thành cao, dùng ở tập đoàn lớn/ngân hàng/chính phủ.
- Microsoft SQL Server: mạnh trong hệ sinh thái của Microsoft (Windows/.NET/Azure).
- Google BigQuery: kho dữ liệu đám mây (cloud data warehouse), tối ưu cho phân tích dữ liệu cực lớn theo mô hình serverless.
6. Mô hình Client–Server trong hệ quản trị CSDL
Các hệ quản trị CSDL hoạt động theo mô hình client–server.
Người dùng không thao tác trực tiếp vào database, mà thông qua các công cụ trung gian như:
- pgAdmin (PostgreSQL)
- DataGrip (PostgreSQL)
- phpMyAdmin (MySql)
- Workbench (MySql).
Các công cụ này gửi câu lệnh đến SQL đến RDBMS để thực thi.
7. Giới thiệu về ngôn ngữ SQL
a. SQL là gì?
SQL (Structured Query Language) là ngôn ngữ dùng để làm việc, tương tác với hệ quản trị cơ sở dữ liệu quan hệ (RDBMS). Ngôn ngữ SQL gồm nhiều lệnh, chia thành nhiều nhóm:
- DDL (Data Definition Language): là nhóm lệnh để làm việc cấu trúc bảng (CREATE, ALTER, DROP…)
- DML (Data Manipulation Language): là nhóm lệnh để thao tác với dữ liệu (INSERT, UPDATE, DELETE…)
- DQL (Data Query Language): là nhóm lệnh dùng để truy vấn dữ liệu trong database (SELECT + WHERE, JOIN, GROUP BY…)
- DCL (Data Control Language): là nhóm lệnh dùng để phân quyền trong database (GRANT, REVOKE…)
- TCL (Transaction Control Language): là nhóm lệnh dùng để điều khiển giao dịch (COMMIT, ROLLBACK…)
Nói cách khác: SQL là “ngôn ngữ làm việc với dữ liệu” trong database.
b. SQL giúp làm gì trong database
Truy vấn và lọc dữ liệu:
SQL giúp Bạn lấy dữ liệu từ một hoặc nhiều bảng,lọc theo điều kiện,sắp xếp,giới hạn số dòng để xem nhanh.
Tiền xử lý dữ liệu (data preprocessing)
SQL hỗ trợ nhiều thao tác tiền xử lý quan trọng: xử lý giá trị NULL, loại bỏ trùng lặp, chuẩn hóa định dạng, chuyển kiểu dữ liệu, tạo cột mới, phân loại…Đây chính là những thao tác trong công tác tiền xử lý dữ liệu.
Tiền xử lý có thể thực hiện bằng Python, nhưng thực tế tiền xử lý ngay trong database thường nhanh và gọn hơn, vì database tối ưu cho xử lý dữ liệu lớn.
Thống kê và tổng hợp:
SQL có các hàm tổng hợp như COUNT, SUM, AVG, MIN, MAX… và các kỹ thuật GROUP BY, HAVING, window functions … giúp phân tích thống kê mô tả và xu hướng rất hiệu quả.
Khám phá dữ liệu :
SQL giúp đếm số bản ghi, giá trung bình, phân bố…


Tạo features (feature engineering):
SQL có thể giúp tạo các feature (cột, đặc tính) mới. Ví dụ: tạo cột nhóm tuổi để dùng cho phân tích/mô hình.
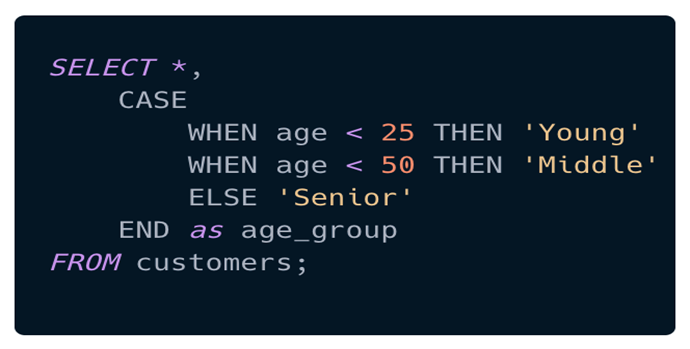


c. SQL được sử dụng từ rất nhiều nơi
SQL thường là “điểm nối” giữa hệ thống dữ liệu và các công cụ phân tích:
- Với Python:
- pandas có read_sql()
- SQLAlchemy hỗ trợ kết nối và truy vấn
- Jupyter có thể chạy SQL trực tiếp (tùy môi trường)
- Với R:
- DBI, dplyr kết nối database
- RStudio hỗ trợ viết đoạn SQL trong workflow
- Với BI Tools:
- Tableau, Power BI, Looker, Metabase, Superset…
- Hầu hết BI đều dựa vào SQL để lấy dữ liệu và dựng dashboard
Tất cả các ngôn ngữ lập trình (như PHP, NodeJS, .NET, Java, Python, R…), các công cụ phân tích đề cần đến SQL để tương tác với database.
Bở vậy việc thành thạo SQL là kỹ năng thiết yếu cho bất kỳ chuyên gia KHDL nào.
8. Cài đặt PostgreSQL
a Cài PostgreSQL
1. Tải bộ cài PostgreSQL
- Vào https://www.postgresql.org/download/
- Chọn hệ điều hành để tải postgresql phù hợp
- Nhắp link Download the installer trong trang web hiện ra để đến trang download (xem hình dưới)
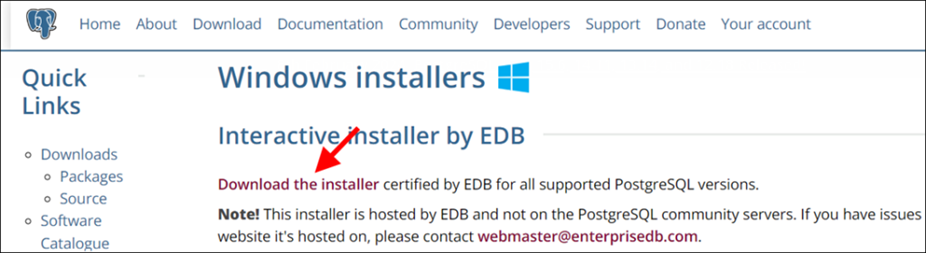
- Giờ thì nhắp chọn version tương ứng với hệ điều hành trên máy của mình. Tất nhiên nên chọn version mới nhất để dùng.
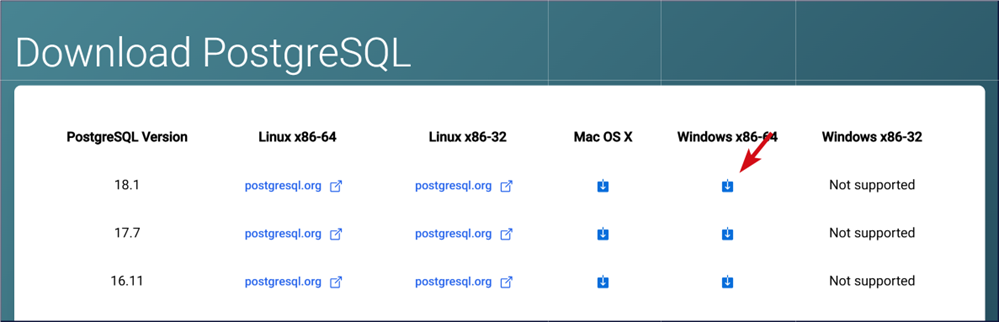
Đợi xíu để quá trình download kết thúc. File tải về khoảng 300-400MB
2. Cài đặt PostgreSQL
Trước khi cài cần nhớ 3 thứ quan trọng:
- cổng mặc định thường là 5432
- user mặc định thường là postgres
- mật khẩu do mình đặt (cần phải nhớ để dùng sau, ví dụ đặt là 123)
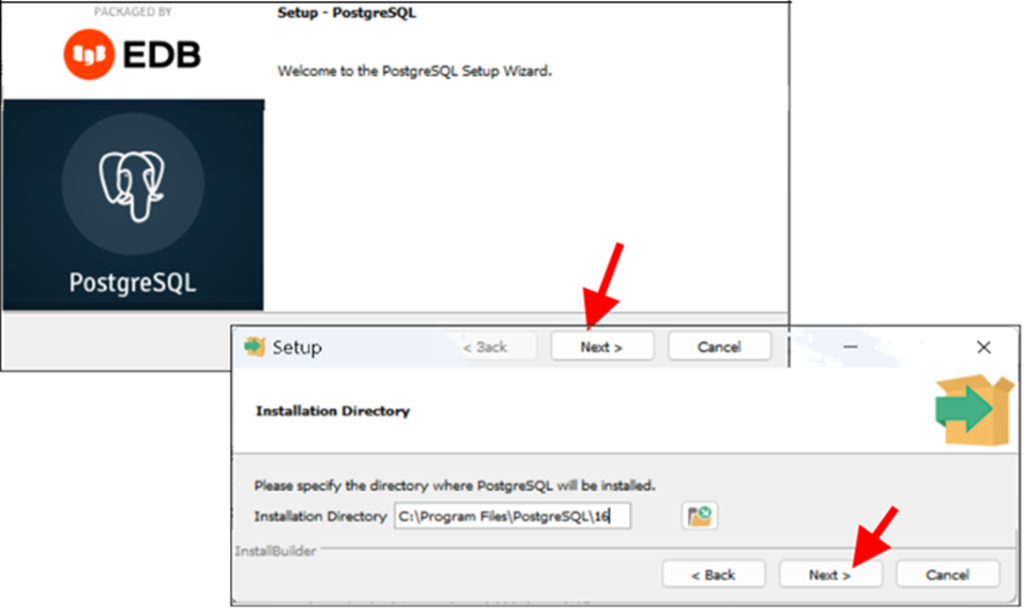
– Bắt đầu cài đặt: Chạy file vừa mới download về rồi nhắp Next rồi chọn folder cài đặt (cứ để nguyên cũng được) và nhắp Next
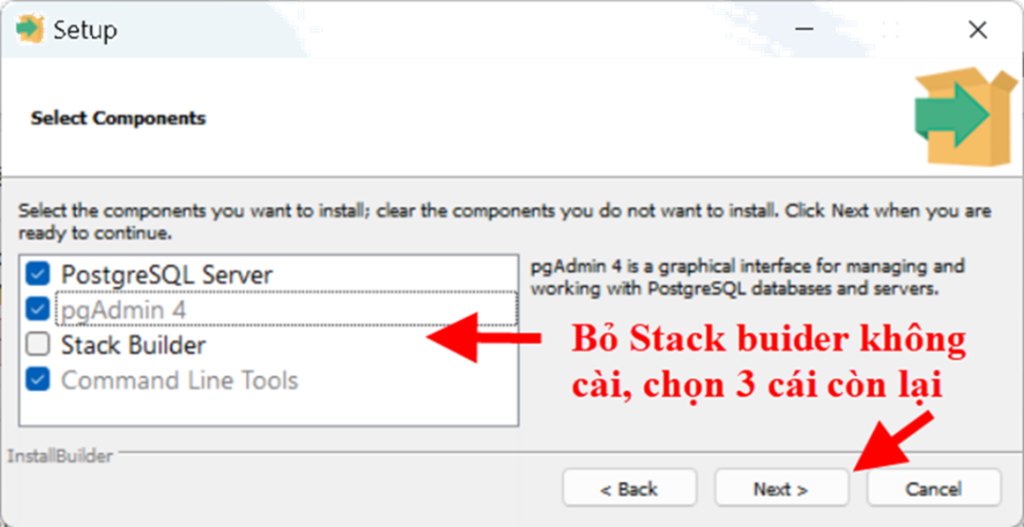
– Tiếp theo là chọn các gói cùng cài với PostgreSQL. Bỏ đi Stack Buider vì nó không quan trọng lắm, sau này cần thì cài thêm. Còn pgAdmin4 và Command line Tools là 2 công cụ quản trị PostgreSQL đừng bỏ nhé vì chúng ta sẽ dùng.
– Việc tiếp theo là chọn folder chứa database của bạn (để nguyên nếu không muốn thay đổi), rồi nhắp Next
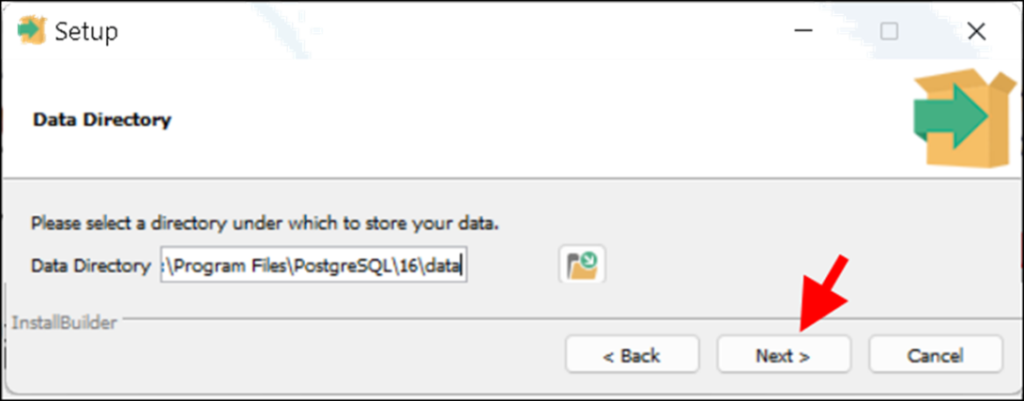
– Màn hình tiếp theo bạn nhập mật khẩu cho user quản trị (user postgres) . Mật khẩu nhập tùy ý (ví dụ 123). Nhập 2 lần giống nhau nhé. Xong rồi nhắp Next
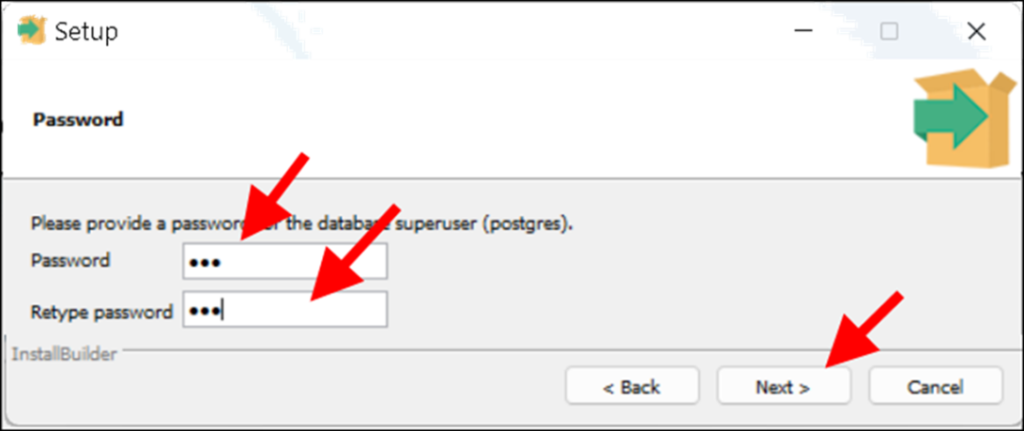
– Chỉ định port hoạt động cho PostgreSQL, cứ để mặc định là 5432 rồi nhắp Next
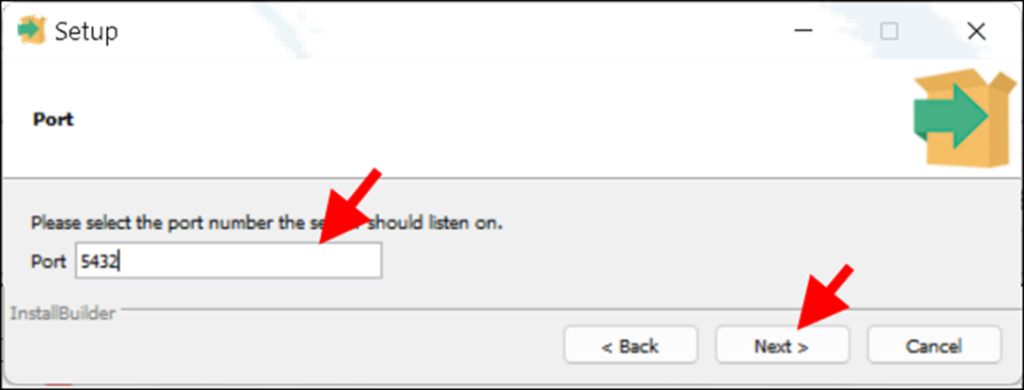
– Màn hình tiếp sau là chọn quốc gia. Chọn Vietnamese rồi nhắp Next
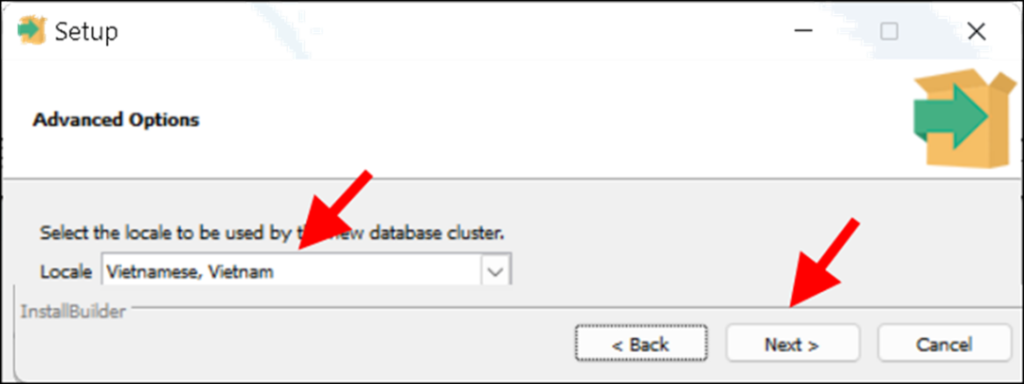
– Bạn sẽ thấy màn hình hiện lại các thông tin vừa nhập. Xem lại coi có cần sửa gì không, nếu cần thì thì nhắp Back. Xem xong rồi thì nhắp Next
– Giờ thì nhắp nút Next để thực thi cài đặt PostgrSQL vào máy.
Khi xong thì nhắp Finish để kết thúc. Vậy là đã có PostgreSQL trong máy rồi.
3. Sau khi cài xong, kiểm tra:
- dịch vụ PostgreSQL đã chạy chưa,
- có đăng nhập được vào database không.
b. Cài công cụ tương tác với PostgreSQL
Bạn có thể chọn 1 trong 2 hướng:
- pgAdmin: miễn phí, đi kèm hệ PostgreSQL, đủ dùng cho học tập.
- DataGrip: mạnh, đẹp, tiện khi làm nhiều hệ CSDL (nhưng thường là trả phí/educational license).
Nếu trong lúc cài PostgreSQL, bạn đã chọn pgAdmin thì giờ đã có dùng, không cần cài thêm
9. Tổng kết:
Qua bài học Tổng quan về Khoa học dữ liệu, chúng ta cần nắm được bốn ý xương sống:
- Khoa học dữ liệu là quá trình biến dữ liệu thành tri thức để ra quyết định, không chỉ đơn thuần là Machine Learning.
- Dữ liệu gồm hai loại chính: có cấu trúc và không có cấu trúc – điều này quyết định công cụ lưu trữ và xử lý.
- RDB/RDBMS là nền tảng quản lý dữ liệu có cấu trúc, và PostgreSQL là môi trường thực hành phù hợp cho môn học.
- SQL là kỹ năng cốt lõi để khai thác dữ liệu trong database.
Hiểu đúng Tổng quan về Khoa học dữ liệu sẽ giúp sinh viên nhìn rõ bức tranh tổng thể trước khi đi sâu vào kỹ thuật truy vấn, thiết kế cơ sở dữ liệu và các mô hình phân tích nâng cao trong những bài học tiếp theo.


