Phân tích hiệu năng truy vấn trong PostgreSQL là một bước quan trọng khi tối ưu hệ thống cơ sở dữ liệu. Khi một câu truy vấn chạy chậm, chúng ta cần hiểu PostgreSQL đang thực thi truy vấn đó như thế nào để xác định nguyên nhân và tìm ra cách cải thiện hiệu năng.
PostgreSQL cung cấp hai công cụ rất hữu ích cho mục đích này là EXPLAIN và EXPLAIN ANALYZE. Các công cụ này cho phép quan sát kế hoạch thực thi truy vấn (query execution plan), bao gồm cách PostgreSQL truy cập dữ liệu, số lượng dòng được xử lý và chi phí ước lượng của từng bước trong truy vấn.
Thông qua việc đọc và phân tích execution plan, lập trình viên và DBA có thể hiểu rõ cách PostgreSQL xử lý một câu truy vấn, xác định khi nào hệ thống đang quét toàn bảng, khi nào index được sử dụng, từ đó đưa ra các phương án tối ưu truy vấn hiệu quả hơn.
1. EXPLAIN trong PostgreSQL là gì
EXPLAIN được sử dụng để xem kế hoạch thực thi truy vấn (query plan) mà PostgreSQL dự định sử dụng.
Điểm quan trọng là: EXPLAIN chỉ hiển thị kế hoạch thực thi, nhưng không thực sự chạy truy vấn.
Ví dụ chạy Explain cho một câu truy vấn
EXPLAIN
SELECT * FROM customers
WHEREemail ='an.nguyen@email.com';
Kết quả Explain:
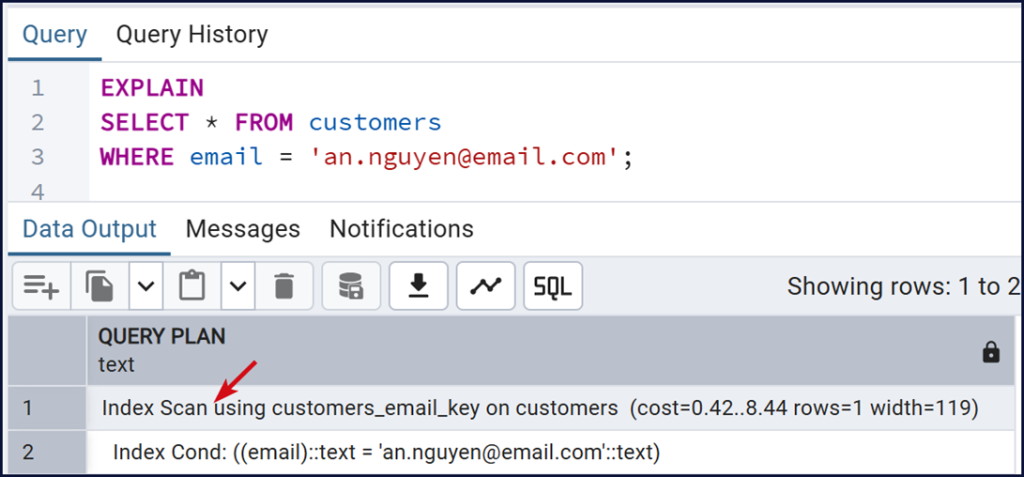
Ý nghĩa của kết quả Explain
– Index Scan using idx_customers_email
PostgreSQL đang sử dụng index idx_customers_email để tìm dữ liệu thay vì quét toàn bộ bảng.
– cost = 0.42..8.44 Đây là chi phí ước lượng của kế hoạch truy vấn.
- 0.42 : startup cost (chi phí bắt đầu)
- 8.44 : total cost (chi phí tổng)
Cost không phải thời gian thực tế, mà là giá trị nội bộ để PostgreSQL so sánh các kế hoạch truy vấn khác nhau.
rows = 1 PostgreSQL ước lượng rằng truy vấn sẽ trả về 1 dòng dữ liệu.
width = 127 Kích thước trung bình của mỗi dòng dữ liệu trả về (tính bằng byte).
2. EXPLAIN ANALYZE là gì
EXPLAIN ANALYZE vừa hiển thị query plan vừa thực thi truy vấn thật sự. Điều này cho phép so sánh:
- kế hoạch ước lượng
- kết quả thực tế
Chạy Explain Analyze một câu truy vấn
EXPLAIN ANALYZE
SELECT*FROMorders
WHEREorder_date >='2025-01-01';
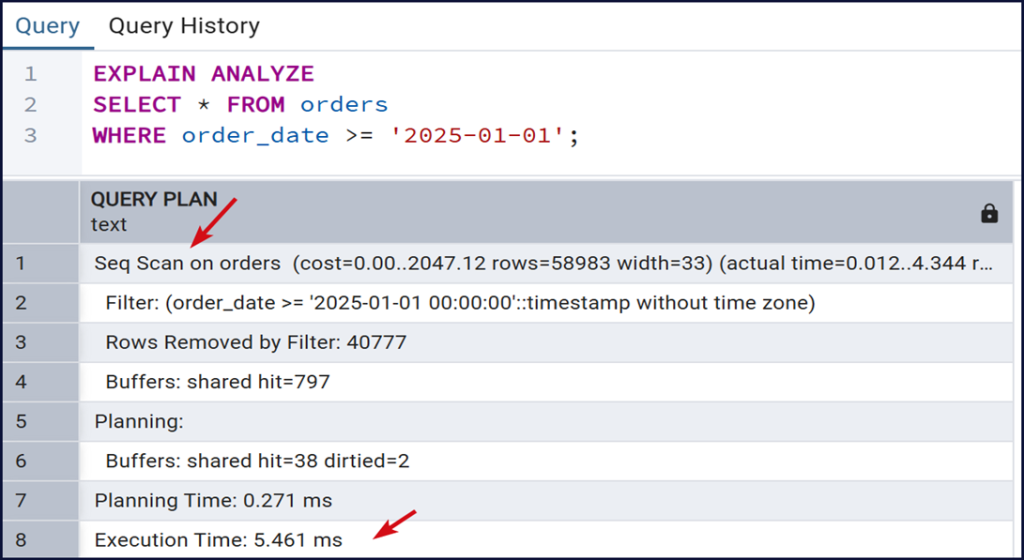
Kết quả Explain Analyze
EXPLAIN và EXPLAIN ANALYZE
Trong thực tế, EXPLAIN thường được dùng để xem query plan nhanh chóng, còn EXPLAIN ANALYZE được dùng khi cần đo thời gian thực thi thực tế của truy vấn.
Việc hiểu execution plan là một phần quan trọng trong quá trình phân tích hiệu năng truy vấn trong PostgreSQL. Khi đọc được query plan, chúng ta có thể biết PostgreSQL đang truy cập dữ liệu theo cách nào, từ đó xác định nguyên nhân khiến truy vấn chậm và đưa ra các phương án tối ưu phù hợp.
| Lệnh | Có chạy query | Mục đích |
| EXPLAIN | Không | Xem query plan |
| EXPLAIN ANALYZE | Có | Xem plan + đo thời gian thực |
3. Ý nghĩa các thông số trong EXPLAIN ANALYZE
Seq Scan (Sequential Scan)
Cho biết PostgreSQL đang quét tuần tự toàn bộ bảng để kiểm tra điều kiện lọc trên từng dòng.
cost:
Thông số Cost là chi phí ước lượng mà PostgreSQL sử dụng để chọn kế hoạch truy vấn.
- cost = 0.00..2047.12 → cost là chi phí ước lượng mà PostgreSQL dùng để quyết định query plan nào tốt nhất. Cú pháp: cost = start_cost .. total_cost
- 0.00 (startup cost) làchi phí để bắt đầu trả về dòng đầu tiên, với Seq Scan (quét toàn bảng) thì chi phí bắt đầu gần như bằng 0 vì PostgreSQL chỉ cần bắt đầu đọc bảng ngay.
- 2047.12 (total cost) → Chi phí tổng cộng để đọc hết toàn bộ dữ liệu theo kế hoạch này.
Cost được tính dựa trên nhiều yếu tố: số trang dữ liệu đọc từ disk, số dòng cần xử lý, CPU cost, random I/O cost
rows
rows là số dòng PostgreSQL ước lượng sẽ được xử lý hoặc trả về ở bước đó.
Sự khác biệt giữa estimated rows và actual rows giúp phát hiện khi statistics của database chưa chính xác.
width
width là kích thước trung bình của một dòng dữ liệu mà node đó trả về.
Thông tin này giúp PostgreSQL ước lượng lượng dữ liệu cần đọc và bộ nhớ cần sử dụng.
Planning Time
Planning Timelà thời gian PostgreSQL sử dụng để:
- phân tích cú pháp SQL
- rewrite query
- phân tích statistics
- chọn execution plan tốt nhất
Quá trình này có thể hiểu đơn giản là: SQL → Query Planner → Execution Plan
Execution Time
Execution Time là thời gian PostgreSQL thực sự chạy truy vấn, bao gồm:
- đọc dữ liệu từ bảng hoặc index
- lọc dữ liệu
- thực hiện join
- tạo result set
Đây là thông số quan trọng khi phân tích hiệu năng truy vấn.
4. Các phương pháp scan dữ liệu trong PostgreSQL
Khi thực thi truy vấn, PostgreSQL có nhiều cách để đọc dữ liệu từ bảng.
Sequential Scan (Seq Scan)
Sequential Scan là phương pháp quét toàn bộ bảng từ đầu đến cuối. Quy trình:
row1 → kiểm tra điều kiện
row2 → kiểm tra điều kiện
row3 → kiểm tra điều kiện
…
Seq Scan thường dùng khi:
- bảng nhỏ hoặc chi phí Seq Scan thấp
- không có index phù hợp
- truy vấn cần đọc phần lớn dữ liệu trong bảng
Chú ý: Seq Scan không phải lúc nào cũng xấu. Ví dụ:
SELECT * FROM orders;
thì dùng dùng index sẽ chậm hơn Seq Scan.
Index Scan
Index Scan sử dụng index để tìm vị trí dữ liệu cần thiết, sau đó đọc dữ liệu từ bảng. Mỗi row trùng khớp trong index sẽ dẫn đến một random read từ bảng. Index Scan thường dùng khi:
- điều kiện WHERE có tính chọn lọc cao
- cột có index
Bitmap Scan
Bitmap Scan gồm hai bước:
- Bitmap Index Scan: Tạo danh sách các vị trí dòng phù hợp từ index.
- Bitmap Heap Scan: Đọc dữ liệu từ bảng theo thứ tự vật lý để giảm random I/O.
Thường dùng khi :
- Query trả về nhiều rows (5-25% bảng)
- Kết hợp nhiều indexes với OR/AND
- Query với multiple WHERE conditions
5. Thuật toán Join
Nested Loop Join
Nested Loop là một thuật toán JOIN phổ biến trong PostgreSQL. Nó hoạt động giống hai vòng lặp lồng nhau:
FOR each row in outer_table (outer loop)
FOR each row in inner_table (inner loop)
IF join_condition matches THEN
return combined row
END IF
END FOR
END FOR
Đặc điểm:
- Outer table thường là bảng nhỏ, thường được scan trước
- Inner table: Bảng được scan nhiều lần, một lần cho mỗi row của outer table, nên có index trên join key
- Best case: Outer table nhỏ + Inner table có index trên join key
- Worst case: Cả 2 bảng đều lớn và không có index
Nested Loop rất hiệu quả khi:
- một bảng nhỏ
- bảng còn lại có index phù hợp
6. Parallel Query (Gather)
Trong một số trường hợp, PostgreSQL có thể sử dụng nhiều worker để xử lý truy vấn song song.
Tức là PostgreSQL sẽ chia việc quét dữ liệu cho nhiều worker để tăng tốc độ xử lý. Lúc này quan sát màn hình sẽ hơi phức tạp hơn một chút:
Ví dụ chạy EXPLAIN ANALYZE:
EXPLAIN ANALYZE
SELECT*FROMcustomers WHEREfirst_name ='Hoàng';
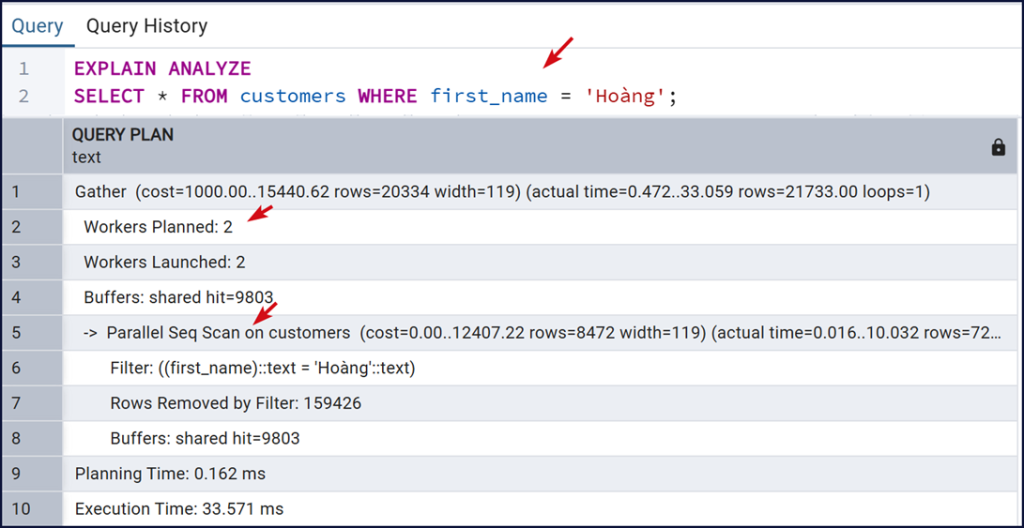
Màn hình cho thấy PostgreSQL chia thành 2 worker để quét toàn bộ bảng.
Trong quá trình học tập, bạn có thể tắt parallel scan bằng lệnh sau để các quan sát rõ hơn:
SET max_parallel_workers_per_gather = 0;
7. Phân tích truy vấn trước và sau khi tạo Index
B-Tree Index
Tạo index B-Tree first_name để tìm kiếm khách hàng theo tên nhanh hơn.
Chạy phân tích query trước khi tạo index
SET max_parallel_workers_per_gather = 0;
EXPLAIN ANALYZE
SELECT * FROM customers WHERE first_name = 'Hoàng';

Seq Scan on customers tức là PostgreSQL quét toàn bộ bảng. Còn nếu index được dùng nó sẽ hiện Bitmap Index Scan / Index Scan / Bitmap Heap Scan
Tạo B-Tree index
CREATE INDEX idx_customers_first_name
ON customers(first_name);
Chạy lại phân tích query sau khi tạo index
SET max_parallel_workers_per_gather = 0;
EXPLAIN ANALYZE
SELECT * FROM customers WHERE first_name = 'Hoàng';
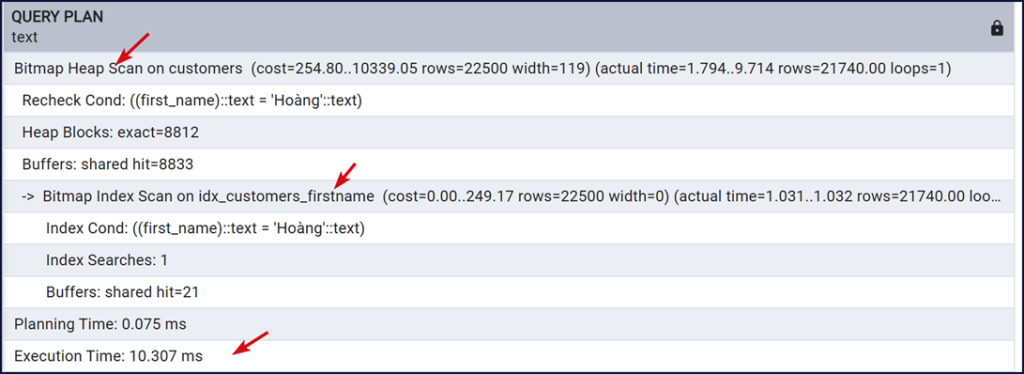
Màn hình cho thấy PostgreSQL dùng index chúng ta vừa mới tạo, phương pháp scan là Bitmap Heap Scan không dùng Seq Scan toàn bảng nữa. Execution Time cho thấy đã giảm đáng kể.
Hash Index
Loại index này chỉ hỗ trợ so sánh bằng (=) và thường được dùng cho các truy vấn tìm kiếm chính xác. Hash Index không hỗ trợ range scan.
Ví dụ: Hash index cho tìm số điện thoại (phone)
Chạy phân tích query trước khi tạo index
SET max_parallel_workers_per_gather = 0;
EXPLAIN ANALYZE
SELECT * FROM customers WHEREphone ='0901829112';
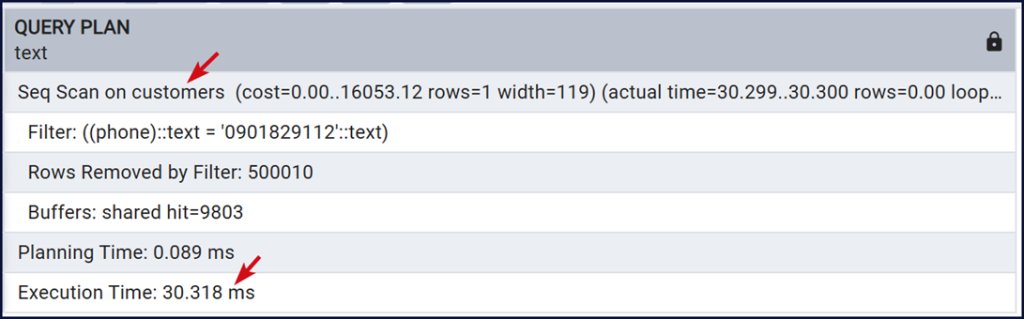
Seq Scan on customers tức là khi tìm kiếm, PostgreSQL sẽ quét toàn bộ bảng. Nếu index được dùng nó sẽ hiện Bitmap Index Scan / Index Scan / Bitmap Heap Scan.
Tạo Hash Index
CREATE INDEX idx_customers_phone_hash
ON customers USING HASH(phone);
Chạy lại phân tích query sau khi tạo index
SET max_parallel_workers_per_gather = 0;
EXPLAINANALYZE
SELECT * FROM customers WHEREphone = '0901829112';
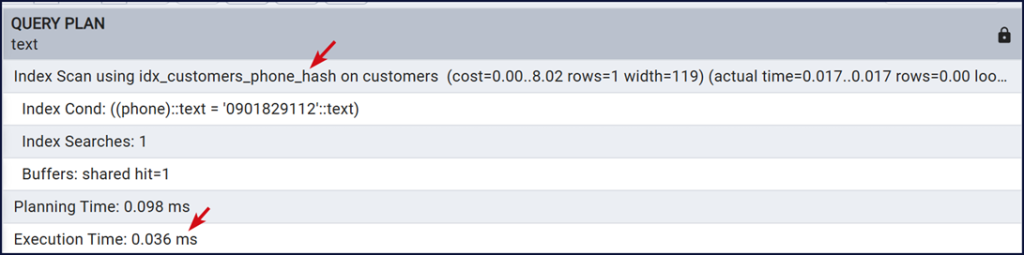
Màn hình cho thấy PostgreSQL dùng index chúng ta vừa mới tạo, phương pháp scan là Index Scan không dùng Seq Scan toàn bảng nữa. Execution Time cho thấy thời gian thực thi truy vấn đã giảm.
GIN (Generalized Inverted Index)
Chạy phân tích query trước khi tạo index
SET max_parallel_workers_per_gather = 0;
EXPLAIN ANALYZE
SELECT * FROM products
WHERE to_tsvector('simple', description) @@ to_tsquery('chụp & đêm');
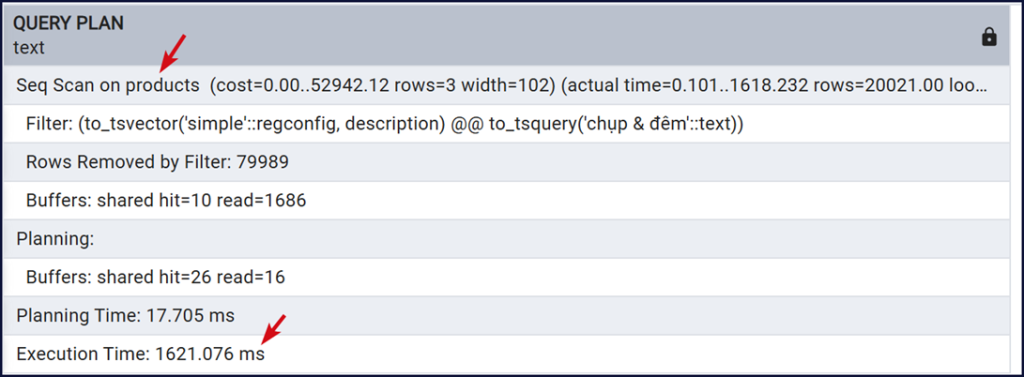
Seq Scan on products : Cho thấy PostgreSQL quét toàn bộ bảng. Còn nếu index được dùng nó sẽ hiện Bitmap Index Scan / Index Scan / Bitmap Heap Scan
Tạo GIN index
CREATE INDEX idx_products_description_gin
ON products USING GIN(to_tsvector('simple', description));
Chạy phân tích query sau khi tạo index
EXPLAIN ANALYZE
SELECT * FROM products
WHERE to_tsvector('simple', description) @@ to_tsquery('chụp & đêm');
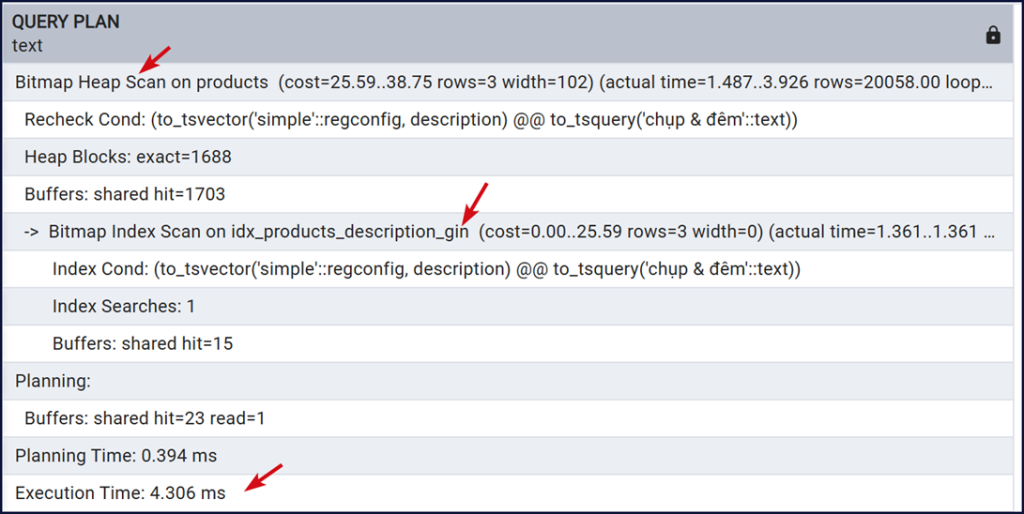
Màn hình cho thấy PostgreSQL dùng index chúng ta vừa mới tạo, phương pháp scan là Bitmap Index Scan không dùng Seq Scan toàn bảng nữa. Execution Time cho thấy thời gian thực thi truy vấn đã giảm.
Giải thích các hàm trong ví dụ:
SELECT * FROM products
WHERE to_tsvector('simple', description) @@ to_tsquery('chụp & đêm');
– to_tsvector(‘simple’, description) à Hàm này chuyển nội dung trong cột description thành chuỗi chỉ mục tìm kiếm (text search vector).
PostgreSQL sẽ:
- Chuẩn hóa từ ngữ (chuyển về dạng gốc, ví dụ “laptops” → “laptop”), Loại bỏ các từ vô nghĩa (stop words như the, a, an),
- Và tạo danh sách các “từ khóa” có thể tìm kiếm được.
- ‘english’ là từ điển ngôn ngữ dùng cho việc phân tích ngữ pháp, nếu dữ liệu không phải là tiếng anh sẽ không tối ưu à dùng simple thay cho english
– to_tsquery(‘chụp & đêm’) à Tạo một biểu thức truy vấn (text search query).
Ký hiệu & nghĩa là AND, tức là chỉ chọn những dòng có cả hai từ “chụp” và “đêm” trong phần mô tả. Một số toán tử khác:
| : OR
! : NOT
<-> : các từ phải nằm gần nhau
– @@ Là toán tử so khớp toàn văn, kiểm tra xem vector (nội dung đã chuẩn hóa) có phù hợp với truy vấn tìm kiếm hay không.Trả về giá trị true hoặc false.
GiST (Generalized Search Tree)
GiST index cho full-text search (linh hoạt hơn GIN)
Chạy phân tích query trước khi tạo index
SET max_parallel_workers_per_gather = 0;
EXPLAIN ANALYZE
SELECT * FROM products
WHERE to_tsvector('simple', product_name) @@ plainto_tsquery('simple', 'iphone');
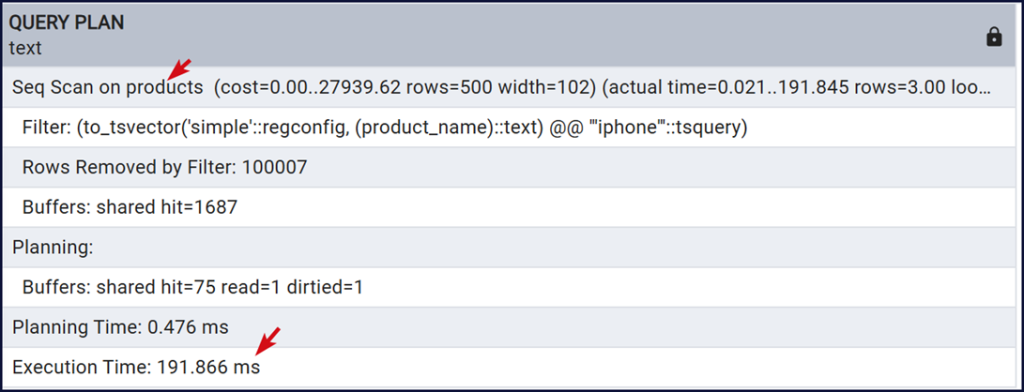
Seq Scan on products tức là quét toàn bộ bảng. Execution Time tương đối lớn vì PostgreSQL phải quét toàn bộ bảng.
Tạo GiST index
CREATE INDEX idx_products_name_gist
ON products USING GIST(to_tsvector('simple', product_name));
Chạy lại phân tích query sau khi tạo index
SET max_parallel_workers_per_gather = 0;
EXPLAIN ANALYZE
SELECT * FROM products
WHERE to_tsvector('simple', product_name) @@ plainto_tsquery('simple', 'iphone');
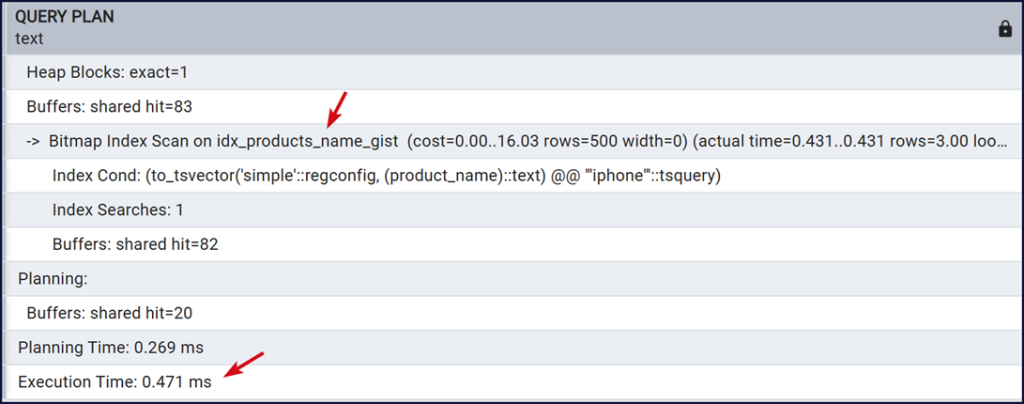
Màn hình cho thấy PostgreSQL dùng index chúng ta vừa mới tạo, phương pháp scan là Bitmap Index Scan không dùng Seq Scan toàn bảng nữa. Execution Time cho thấy thời gian thực thi đã giảm.
So sánh GIN vs GiST
| GIN | GiST | |
| structure | inverted index | tree index |
| search speed | rất nhanh | chậm hơn |
| index size | lớn | nhỏ |
| insert/update | chậm | nhanh |
| full-text search | tốt nhất | dùng được nhưng chậm |
| spatial data | không | tốt |
Partial Index
Index chỉ cho các đơn hàng Delivered
Chạy phân tích query trước khi tạo index
SET max_parallel_workers_per_gather = 0;
EXPLAIN ANALYZE
SELECT * FROM orders
WHERE status='Delivered' AND order_date >='2024-01-01';
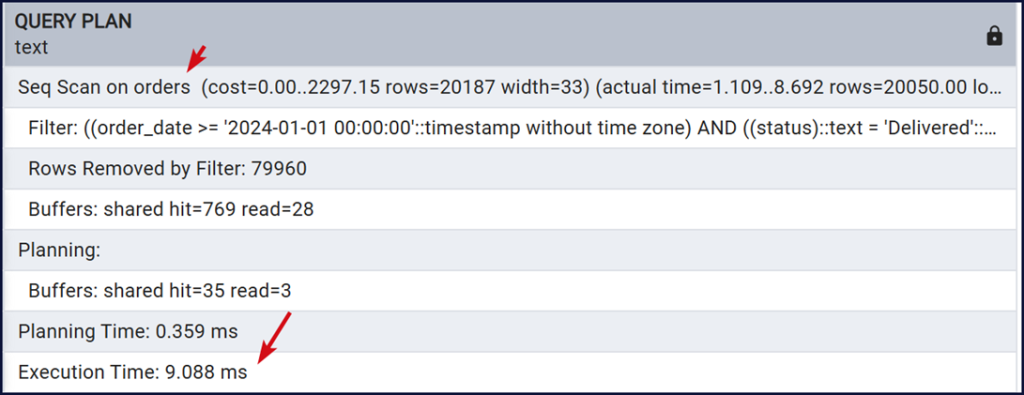
Seq Scan on orders nghĩa là PostgreSQL quét toàn bộ bảng để tìm các dòng thỏa điều kiện. Execution Time là thời gian thực thi thực tế của truy vấn.
Tạo partial index
CREATE INDEX idx_orders_delivered
ON orders(order_date)
WHERE status = 'Delivered';
Chạy lại phân tích query sau khi tạo index
SET max_parallel_workers_per_gather = 0;
EXPLAIN ANALYZE
SELECT * FROM orders
WHEREstatus ='Delivered' AND order_date >='2024-01-01';
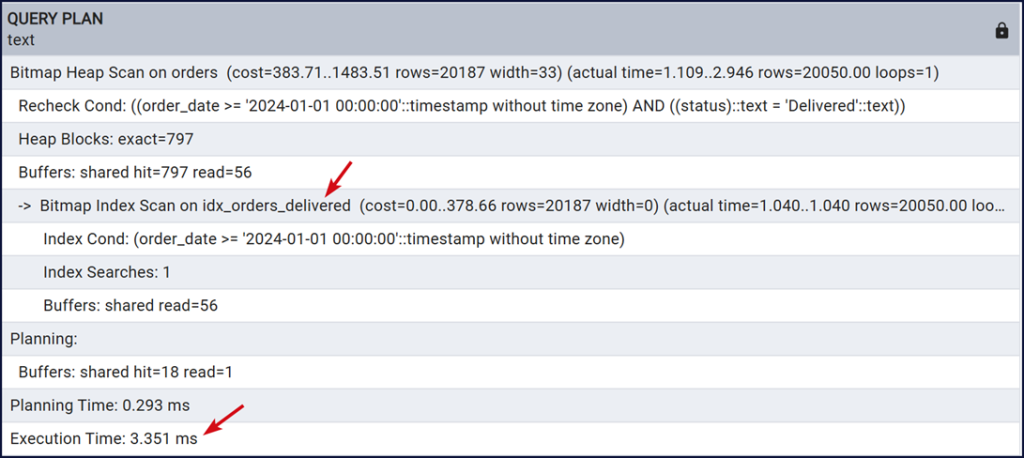
Nhìn thông số phân tích sau khi tạo index, cho thấy PostgreSQL dùng index vừa mới tạo, phương pháp scan là Bitmap Index Scan không dùng Seq Scan toàn bảng nữa. Execution Time cho thấy thời gian thực thi nhỏ hơn.
8. Khi nào PostgreSQL không dùng Index
Không phải lúc nào PostgreSQL cũng sử dụng index. Trong nhiều trường hợp, hệ thống vẫn chọn Seq Scan. Một số nguyên nhân phổ biến:
- bảng quá nhỏ
- truy vấn cần đọc nhiều dòng
- statistics chưa được cập nhật
- điều kiện truy vấn không chọn lọc
- index không phù hợp với điều kiện WHERE
Do đó, việc kiểm tra execution plan bằng EXPLAIN ANALYZE là rất quan trọng.
Kết luận
Phân tích hiệu năng truy vấn trong PostgreSQL là một kỹ năng quan trọng giúp chúng ta hiểu cách database thực thi các câu truy vấn và phát hiện các điểm nghẽn hiệu năng. Thông qua các công cụ như EXPLAIN và EXPLAIN ANALYZE, chúng ta có thể quan sát query plan, đánh giá chi phí thực thi và xác định khi nào cần tối ưu truy vấn hoặc tạo index.
Việc thường xuyên thực hiện phân tích hiệu năng truy vấn trong PostgreSQL giúp hệ thống database hoạt động hiệu quả hơn, giảm thời gian truy vấn và cải thiện khả năng xử lý dữ liệu trong các hệ thống có quy mô lớn.


