Window Functions trong PostgreSQL là một trong những tính năng mạnh mẽ nhất của hệ quản trị cơ sở dữ liệu PostgreSQL, đặc biệt khi làm việc với các bài toán phân tích dữ liệu. Nếu bạn đang sử dụng SQL để phân tích doanh thu, xếp hạng dữ liệu, tính tổng tích lũy hoặc xử lý chuỗi thời gian, thì việc hiểu và sử dụng thành thạo Window Functions sẽ giúp bạn viết các truy vấn hiệu quả và linh hoạt hơn rất nhiều.

Khác với các hàm tổng hợp truyền thống như SUM(), COUNT() hay AVG() thường được sử dụng cùng GROUP BY, Window Functions cho phép thực hiện các phép tính trên một tập các dòng dữ liệu liên quan nhưng không làm mất đi các dòng dữ liệu ban đầu. Điều này rất quan trọng trong các tình huống phân tích, nơi chúng ta vừa cần kết quả tính toán vừa cần giữ lại toàn bộ dữ liệu chi tiết.
Trong bài viết này, chúng ta sẽ cùng tìm hiểu chi tiết về Window Functions trong PostgreSQL, cách chúng hoạt động, cú pháp cơ bản, cũng như một số hàm phổ biến thường được sử dụng trong thực tế.
Window Functions trong PostgreSQL là gì?
Window Functions trong PostgreSQL là các hàm cho phép thực hiện tính toán trên một nhóm các dòng dữ liệu liên quan đến dòng hiện tại, nhưng vẫn giữ nguyên từng dòng trong kết quả truy vấn.
Nói một cách đơn giản hơn, mỗi dòng dữ liệu sẽ có một “cửa sổ” (window) bao gồm nhiều dòng khác. Hàm window sẽ thực hiện phép tính trên cửa sổ đó và trả kết quả cho từng dòng riêng lẻ.
Điểm khác biệt quan trọng giữa Window Functions và GROUP BY là:
- GROUP BY sẽ gộp nhiều dòng thành một dòng kết quả
- Window Functions giữ nguyên tất cả các dòng dữ liệu
Ví dụ giả sử ta có bảng dữ liệu nhân viên:
| employee | department | salary |
| A | IT | 1000 |
| B | IT | 1500 |
| C | HR | 1200 |
Nếu sử dụng GROUP BY department, ta chỉ nhận được tổng lương theo phòng ban. Nhưng với Window Functions, ta có thể hiển thị tổng lương phòng ban ngay trên từng dòng nhân viên, giúp việc phân tích trở nên chi tiết và trực quan hơn.
Cú pháp cơ bản của Window Functions trong PostgreSQL
Cú pháp chung của một window function trong PostgreSQL thường có dạng:
function_name(expression)
OVER(
PARTITIONBYcolumn
ORDERBYcolumn
)
Trong đó, phần OVER() đóng vai trò cực kỳ quan trọng vì nó xác định phạm vi dữ liệu mà hàm sẽ thực hiện tính toán.
OVER()
OVER() là thành phần bắt buộc của window function. Nó xác định cửa sổ dữ liệu mà hàm sẽ áp dụng. Nếu không có OVER(), PostgreSQL sẽ xem hàm đó như một hàm tổng hợp thông thường.
Bên trong OVER() có thể bao gồm các thành phần như:
- PARTITION BY
- ORDER BY
- ROWS BETWEEN
Những thành phần này giúp định nghĩa cách dữ liệu được chia nhóm và cách cửa sổ dữ liệu được hình thành.
PARTITION BY
PARTITION BY dùng để chia dữ liệu thành nhiều nhóm nhỏ gọi là partition. Mỗi partition sẽ được xử lý độc lập. Điểm quan trọng là mặc dù dữ liệu được chia nhóm để tính toán, nhưng các dòng dữ liệu vẫn được giữ nguyên trong kết quả.
Giả sử chúng ta có bảng dữ liệu sales như sau:
| id | employee | department | sale_date | revenue |
| 1 | Alice | IT | 2024-01-01 | 500 |
| 2 | Bob | IT | 2024-01-02 | 700 |
| 3 | Charlie | IT | 2024-01-03 | 700 |
| 4 | David | HR | 2024-01-01 | 400 |
| 5 | Eva | HR | 2024-01-02 | 600 |
| 6 | Frank | HR | 2024-01-03 | 600 |
| 7 | Grace | Marketing | 2024-01-01 | 450 |
| 8 | Helen | Marketing | 2024-01-02 | 650 |
| 9 | Ian | Marketing | 2024-01-03 | 800 |
| 10 | Alice | IT | 2024-01-04 | 550 |
| 11 | Bob | IT | 2024-01-05 | 720 |
| 12 | Eva | HR | 2024-01-04 | 620 |
| 13 | David | HR | 2024-01-05 | 500 |
| 14 | Helen | Marketing | 2024-01-04 | 700 |
| 15 | Ian | Marketing | 2024-01-05 | 850 |
CREATE TABLE sales (
id SERIAL PRIMARY KEY,
employee VARCHAR(50), -- tên nhân viên
department VARCHAR(50), -- bộ phận
sale_date DATE,
revenue INT --doanh số bán hàng
);
INSERT INTO sales (employee, department, sale_date, revenue) VALUES
('Alice', 'IT', '2024-01-01', 500),
('Bob', 'IT', '2024-01-02', 700),
('Charlie', 'IT', '2024-01-03', 700),
('David', 'HR', '2024-01-01', 400),
('Eva', 'HR', '2024-01-02', 600),
('Frank', 'HR', '2024-01-03', 600),
('Grace', 'Marketing', '2024-01-01', 450),
('Helen', 'Marketing', '2024-01-02', 650),
('Ian', 'Marketing', '2024-01-03', 800),
('Alice', 'IT', '2024-01-04', 550),
('Bob', 'IT', '2024-01-05', 720),
('Eva', 'HR', '2024-01-04', 620),
('David', 'HR', '2024-01-05', 500),
('Helen', 'Marketing', '2024-01-04', 700),
('Ian', 'Marketing', '2024-01-05', 850);Ví dụ 1:
SELECT
employee,
department,
revenue,
SUM(revenue) OVER (PARTITION BY department) AS total_department_revenue
FROM sales;
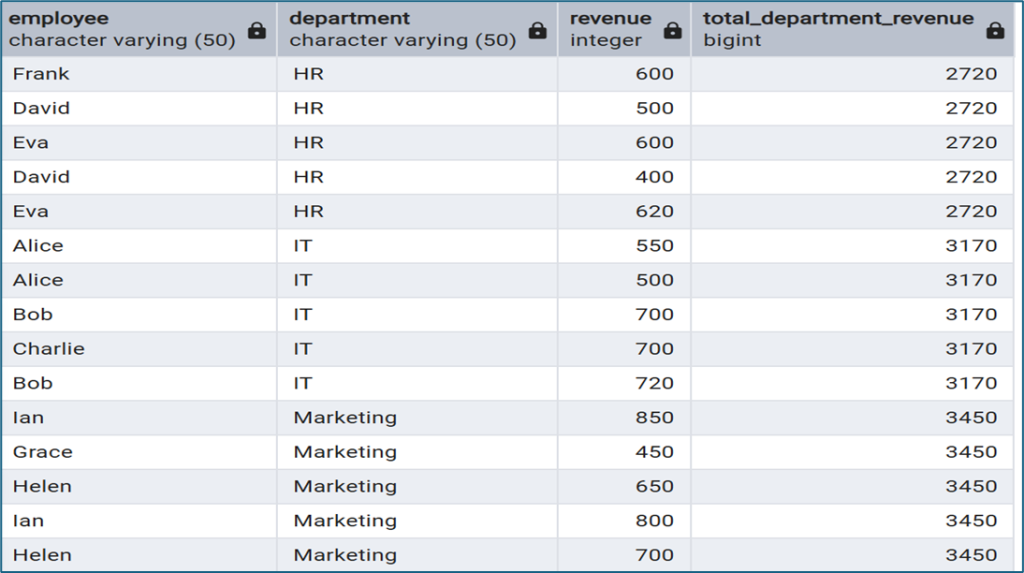
Trong ví dụ này:
- Dữ liệu được chia theo department
- Tổng doanh thu sẽ được tính riêng cho từng phòng ban
- Kết quả tổng sẽ xuất hiện trên từng dòng nhân viên trong cùng phòng ban
Điều này giúp chúng ta dễ dàng so sánh doanh thu cá nhân với tổng doanh thu của phòng ban.
ORDER BY trong Window Functions
ORDER BY bên trong OVER() xác định thứ tự của các dòng trong mỗi partition.
Thứ tự này đặc biệt quan trọng khi sử dụng các hàm như:
- ROW_NUMBER()
- RANK()
- LAG()
- LEAD()
- Running totals
Ví dụ:
SELECT
employee,
revenue,
ROW_NUMBER() OVER (ORDER BY revenue DESC) AS rank
FROM sales;
Ở đây, dữ liệu được sắp xếp theo revenue giảm dần và mỗi dòng sẽ được gán một số thứ tự tương ứng.
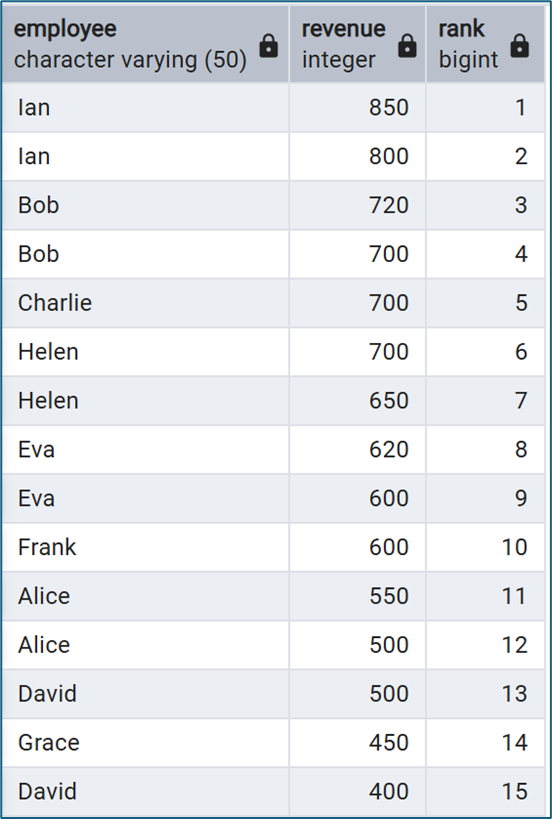
Các Window Functions phổ biến trong PostgreSQL
ROW_NUMBER()
ROW_NUMBER() là một trong những window function đơn giản và phổ biến nhất. Hàm này đánh số thứ tự cho từng dòng dựa trên thứ tự được xác định bởi ORDER BY. Ví dụ:
SELECT
employee,
revenue,
ROW_NUMBER() OVER (ORDER BY revenue DESC) AS rank
FROM sales;
Kết quả sẽ hiển thị thứ hạng của từng giao dịch dựa trên doanh thu, từ cao xuống thấp.
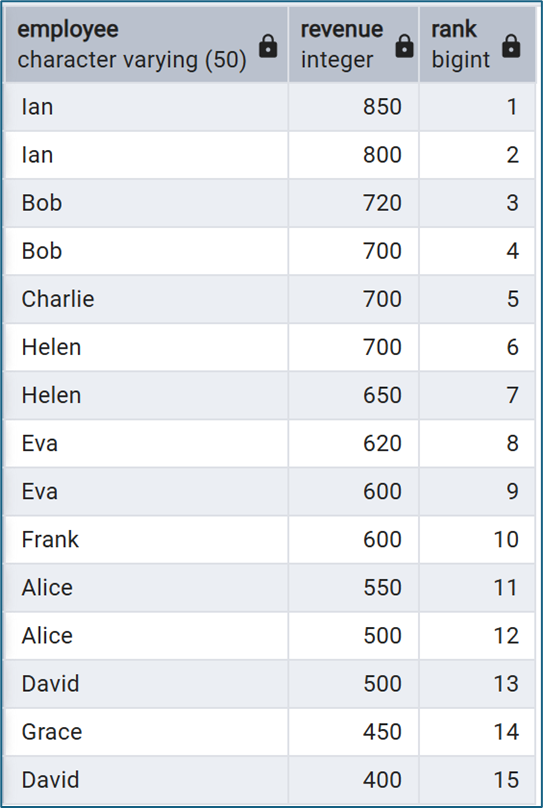
Hàm này thường được sử dụng trong các bài toán như:
- Lấy top N bản ghi
- Phân trang dữ liệu
- Xếp hạng dữ liệu
Top nhân viên trong mỗi phòng ban
SELECT
employee,
department,
revenue,
ROW_NUMBER() OVER (
PARTITION BY department
ORDER BY revenue DESC
) AS rank
FROM sales;
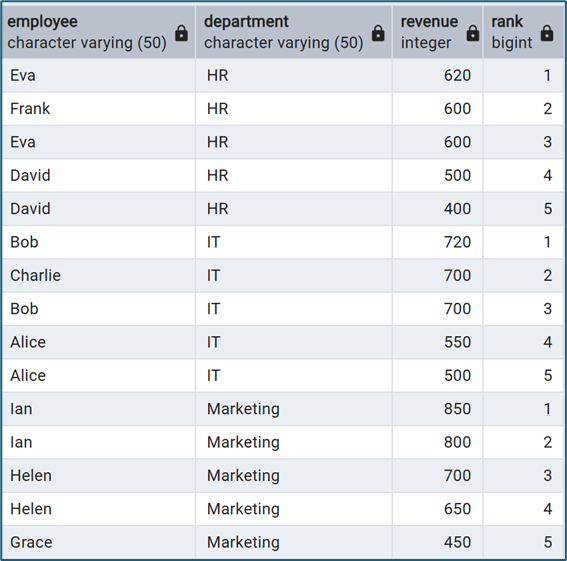
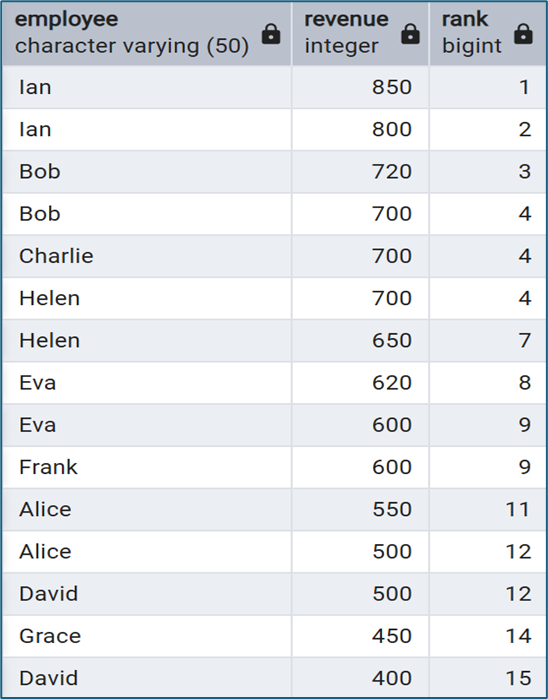
RANK()
RANK() cũng được dùng để xếp hạng dữ liệu nhưng khác với ROW_NUMBER(), hàm này cho phép các giá trị giống nhau có cùng thứ hạng. Ví dụ:
| revenue | rank |
| 700 | 1 |
| 700 | 1 |
| 600 | 3 |
Ta thấy rằng nếu hai dòng có cùng doanh thu, chúng sẽ có cùng thứ hạng và thứ hạng tiếp theo sẽ bị bỏ qua.
SELECT
employee,
revenue,
RANK() OVER (ORDER BY revenue DESC) AS rank
FROM sales;
DENSE_RANK()
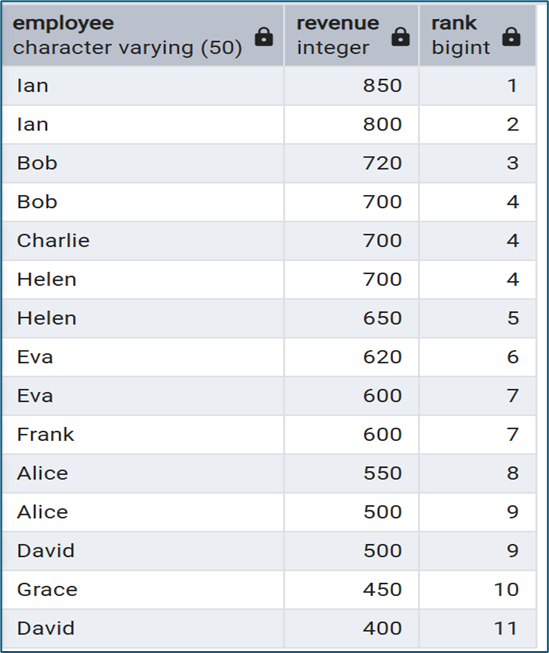
DENSE_RANK() hoạt động tương tự RANK() nhưng không bỏ qua thứ hạng. Ví dụ:
| revenue | dense_rank |
| 700 | 1 |
| 700 | 1 |
| 600 | 2 |
Hàm này thường được sử dụng khi cần xếp hạng liên tục mà không có khoảng trống trong thứ tự.
SELECT
employee,
revenue,
DENSE_RANK() OVER (ORDER BY revenue DESC) AS rank
FROM sales;
LAG()
LAG() là một window function cực kỳ hữu ích khi làm việc với dữ liệu theo thời gian. Hàm này cho phép lấy giá trị của dòng trước đó trong cùng một cửa sổ dữ liệu. Ví dụ:
SELECT
employee,
revenue,
LAG(revenue) OVER (ORDER BY id) AS previous_revenue
FROM sales;
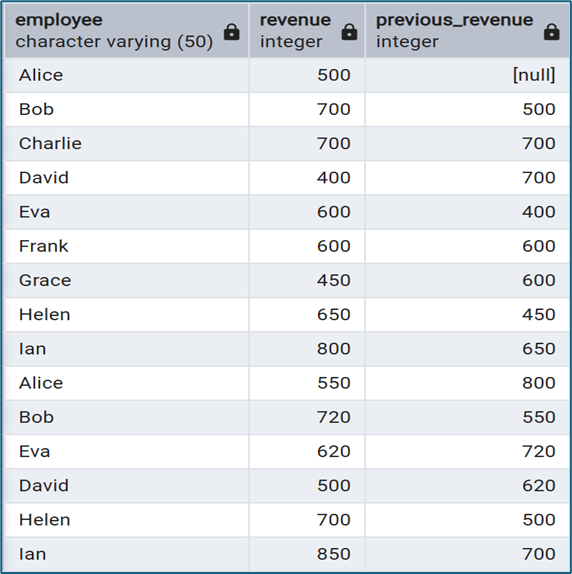
Với truy vấn này, mỗi dòng sẽ hiển thị thêm doanh thu của dòng trước đó. Điều này rất hữu ích khi phân tích:
- Tăng trưởng doanh thu
- So sánh dữ liệu giữa các thời điểm
- Phân tích chuỗi thời gian
Doanh thu hôm nay vs hôm qua của cùng nhân viên
SELECT
employee,
revenue,
LAG(revenue) OVER ( PARTITION BY employee ORDER BY sale_date ) AS previous_revenue
FROM sales;
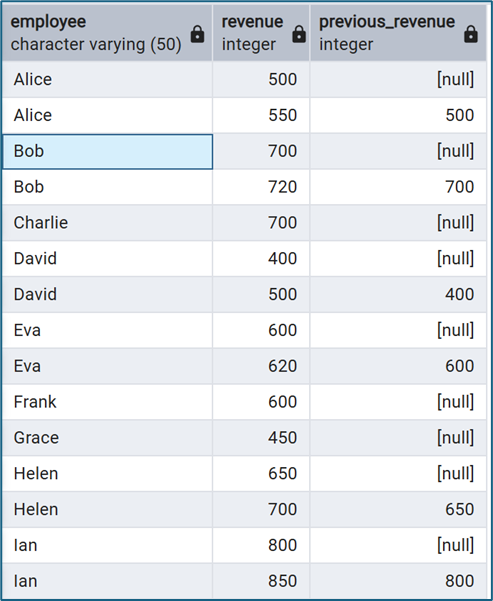
LEAD()
LEAD() là hàm ngược lại với LAG(). Thay vì lấy giá trị của dòng trước, nó lấy giá trị của dòng tiếp theo. Ví dụ:
SELECT
employee,
revenue,
LEAD(revenue) OVER (ORDER BY id) AS next_revenue
FROM sales;
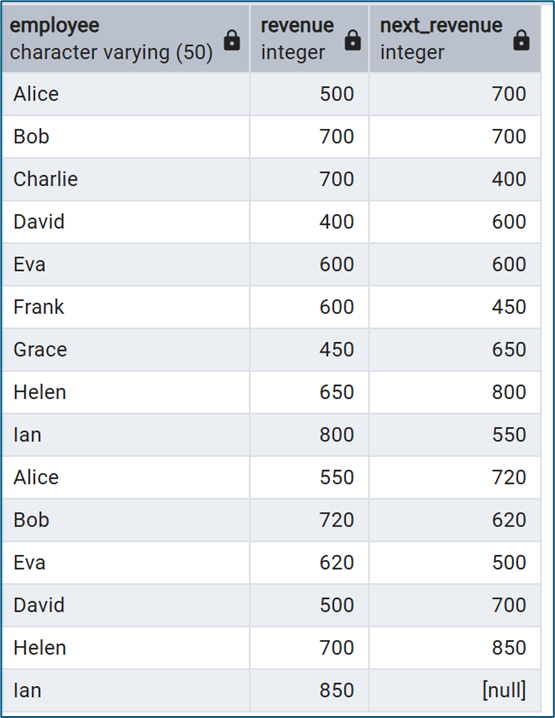
Hàm này thường được sử dụng trong các bài toán như:
- Dự đoán xu hướng
- So sánh dữ liệu giữa các mốc thời gian
Ví dụ thực tế: Running Total
Một ứng dụng phổ biến của Window Functions trong PostgreSQL là tính tổng tích lũy (running total). Ví dụ:
SELECT
sale_date,
revenue,
SUM(revenue) OVER (ORDER BY sale_date) AS cumulative_revenue
FROM sales;
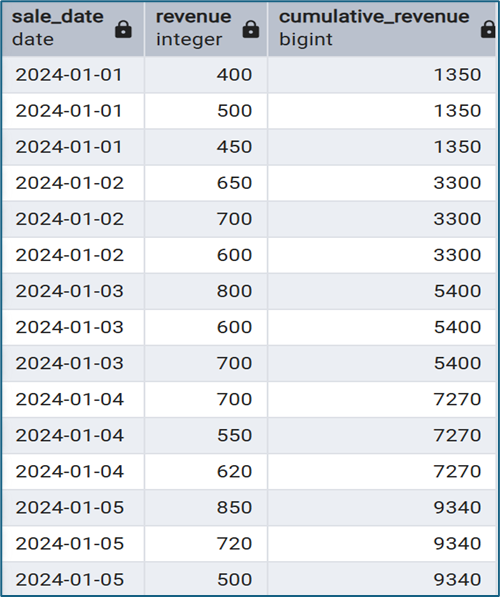
Kết quả sẽ cho thấy tổng doanh thu tích lũy theo thời gian.
Ví dụ:
| date | revenue | cumulative_revenue |
| 01-01 | 100 | 100 |
| 02-01 | 150 | 250 |
| 03-01 | 200 | 450 |
Running total thường được sử dụng trong:
- Phân tích doanh thu
- Theo dõi tăng trưởng
- Báo cáo kinh doanh
Doanh thu tích lũy của từng phòng ban
SELECT
sale_date,
department,
revenue,
SUM(revenue) OVER ( PARTITION BY department ORDER BY sale_date ) AS cumulative_revenue
FROM sales;
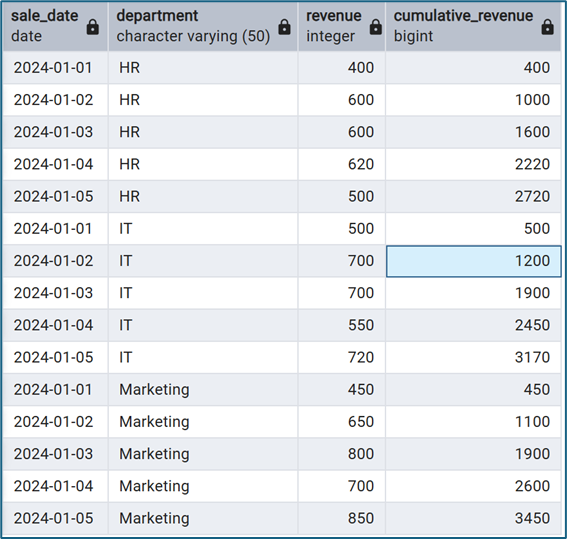
Ứng dụng của Window Functions trong phân tích dữ liệu
Trong thực tế, Window Functions trong PostgreSQL được sử dụng rất nhiều trong các hệ thống phân tích dữ liệu và Business Intelligence.
Một số ứng dụng phổ biến bao gồm:
- Xếp hạng khách hàng theo doanh thu
- Tính tổng tích lũy theo thời gian
- So sánh dữ liệu giữa các dòng
- Phân tích chuỗi thời gian
- Tạo các đặc trưng dữ liệu cho machine learning
Nhờ khả năng tính toán trên từng dòng mà vẫn giữ nguyên dữ liệu chi tiết, Window Functions trở thành công cụ không thể thiếu đối với các Data Analyst, Data Engineer và Data Scientist.
Bài tập thực hành
Sau khi đã làm quen với các Window Functions trong PostgreSQL như ROW_NUMBER(), RANK(), LAG(), LEAD() và SUM() OVER(), chúng ta hãy thử áp dụng các hàm này vào một vài tình huống thực tế. Dưới đây là một số bài tập nhỏ để bạn luyện tập thêm với bảng sales đã tạo ở trên.
Bài tập 1: Xếp hạng doanh thu theo phòng ban
Hãy viết truy vấn SQL để xếp hạng doanh thu của từng nhân viên trong mỗi phòng ban, từ cao xuống thấp. Gợi ý:
- Sử dụng RANK() hoặc ROW_NUMBER()
- Kết hợp với PARTITION BY department
Bài tập 2: Tìm nhân viên có doanh thu cao nhất mỗi phòng ban
Từ kết quả xếp hạng ở bài trên, hãy tìm nhân viên có doanh thu cao nhất trong từng phòng ban. Gợi ý:
- Sử dụng ROW_NUMBER()
- Lọc kết quả với rank = 1
Bài tập 3: So sánh doanh thu với ngày trước đó
Hãy tính doanh thu của ngày trước đó cho mỗi nhân viên để so sánh sự thay đổi theo thời gian. Gợi ý:
- Sử dụng LAG()
- Partition theo employee
- Sắp xếp theo sale_date
Bài tập 4: Tính doanh thu tích lũy theo thời gian
Hãy viết truy vấn để tính tổng doanh thu tích lũy theo ngày. Gợi ý:
- Sử dụng SUM(revenue) OVER
- ORDER BY sale_date
Bài tập 5: Tính tỷ lệ đóng góp doanh thu của mỗi nhân viên
Hãy tính tỷ lệ đóng góp doanh thu của từng dòng dữ liệu so với tổng doanh thu của phòng ban. Gợi ý:
revenue / SUM(revenue) OVER (PARTITION BY department)
Kết luận
Window Functions trong PostgreSQL là một công cụ cực kỳ mạnh mẽ khi làm việc với dữ liệu phân tích bằng SQL. Thay vì phải viết các truy vấn phức tạp hoặc sử dụng nhiều subquery, Window Functions cho phép chúng ta thực hiện các phép tính nâng cao ngay trên từng dòng dữ liệu một cách trực quan và hiệu quả.
Những hàm như ROW_NUMBER(), RANK(), LAG(), LEAD() hay SUM() OVER() giúp giải quyết rất nhiều bài toán thực tế trong phân tích dữ liệu, từ xếp hạng, tính tổng tích lũy cho đến xử lý dữ liệu theo thời gian.
Nếu bạn đang làm việc với SQL trong lĩnh vực phân tích dữ liệu, việc hiểu rõ và thành thạo Window Functions trong PostgreSQL sẽ giúp bạn nâng cao đáng kể khả năng viết truy vấn và khai thác dữ liệu một cách hiệu quả hơn.


