Các khái niệm cơ bản trong RDBMS (Relational Database Management System) là nền tảng quan trọng để hiểu cách dữ liệu được tổ chức, lưu trữ và quản lý trong các hệ thống thông tin hiện đại.
Trong thực tế, phần lớn dữ liệu của doanh nghiệp được lưu trữ trong các hệ quản trị cơ sở dữ liệu quan hệ như PostgreSQL, MySQL, SQL Server. Vì vậy, trước tiên chúng ta cần hiểu rõ các khái niệm cơ bản trong RDBMS.
Cụ thể, trong bài này, chúng ta sẽ tìm hiểu những thành phần nền tảng của mô hình dữ liệu quan hệ, bao gồm:
- bảng (table), hàng (row) và cột (column)
- schema và database
- khóa chính (primary key) và khóa ngoại (foreign key)
- các ràng buộc dữ liệu (constraints)
- mối quan hệ giữa các bảng trong cơ sở dữ liệu
Những khái niệm này giúp dữ liệu được tổ chức rõ ràng, nhất quán và sẵn sàng cho việc truy vấn cũng như phân tích dữ liệu sau này.
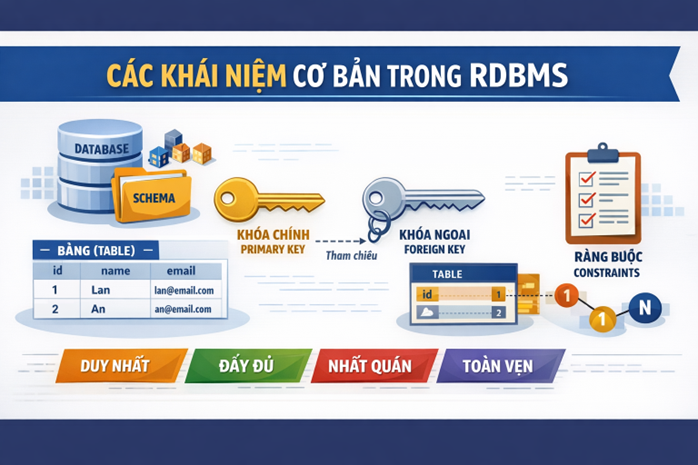
1. BẢNG – HÀNG – CỘT – SCHEMA – DATABASE
1.1 Bảng (table) – trung tâm của RDBMS
Bảng (table) là cấu trúc dữ liệu quan trọng nhất. Mọi thứ gần như đều xoay quanh bảng.
- Bảng tổ chức dữ liệu theo hàng và cột, về hình thức giống như một sheet trong Excel, nhưng có quy tắc chặt chẽ hơn.
- Mỗi bảng thường đại diện cho một thực thể trong thế giới thực: khach_hang, san_pham, don_hang, nhan_vien…
Hình ảnh của một bảng (khach_hang) như sau:
| id | ho_ten | tuoi | |
| 1 | Nguyễn A | nguyena@email.com | 25 |
| 2 | Trần B | tranb@email.com | 30 |
a. Hàng – một đối tượng cụ thể
Mỗi hàng trong bảng (còn gọi là bản ghi, row, record) đại diện cho một đối tượng cụ thể thuộc thực thể đó. Ví dụ: Trong bảng khách hàng, mỗi hàng là một khách hàng cụ thể với đủ thông tin: id, ho_ten, email, tuoi…
b. Cột (column/field/attribute) – thuộc tính của thực thể
Mỗi cột (còn gọi là column , field , attribute) là một thuộc tính của thực thể. Mỗi cột có kiểu dữ liệu cụ thể như INT, VARCHAR, DATE… Kiểu dữ liệu dùng để quy định rõ nó được phép lưu gì. Ví dụ bảng khách hàng có các cột: id, ho_ten, email, tuoi
c. Xem nhẹ lệnh tạo bảng (sẽ học sau)
CREATE TABLE khach_hang (
id INT PRIMARY KEY,
ho_ten VARCHAR(100),
email VARCHAR(100),
tuoi INT
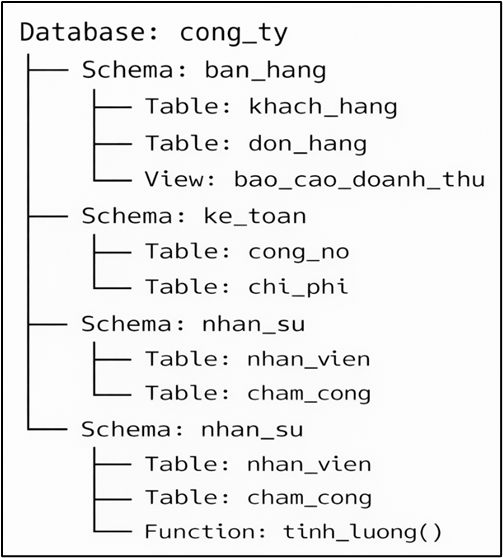
);1.2 Schema – “khu” chức năng bên trong một database
Nếu database là một tòa nhà lớn, thì schema giống như các tầng hoặc các phòng ban trong tòa nhà đó.
Schema là gì
- Schema là “container logic” trong database.
- Nó tổ chức các đối tượng như table, view, function theo nhóm chức năng.
- Một database có thể có nhiều schema.
Ví dụ database CongTy có 3 schema: BanHang, KeToan, NhanSu. Điều này giúp: tách biệt chức năng, giảm lộn xộn, phân quyền dễ hơn…
Lệnh tạo schema
CREATE SCHEMA ban_hang;
CREATE SCHEMA ke_toan;
CREATE SCHEMA nhan_su;Code full tạo table, view trong schema
CREATE TABLE ban_hang.khach_hang (
id SERIAL PRIMARY KEY,
ho_ten VARCHAR(100) NOT NULL,
email VARCHAR(100) UNIQUE,
dien_thoai VARCHAR(20),
ngay_tao TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE ban_hang.don_hang (
id SERIAL PRIMARY KEY,
khach_hang_id INT NOT NULL,
ngay_dat DATE DEFAULT CURRENT_DATE,
tong_tien DECIMAL(12,2) DEFAULT 0
);
CREATE VIEW ban_hang.bao_cao_doanh_thu AS
SELECT
ngay_dat,
SUM(tong_tien) AS tong_doanh_thu
FROM ban_hang.don_hang
GROUP BY ngay_dat;
CREATE TABLE ke_toan.cong_no (
id SERIAL PRIMARY KEY,
khach_hang_id INT,
so_tien DECIMAL(12,2),
ngay_phat_sinh DATE DEFAULT CURRENT_DATE
);
CREATE TABLE ke_toan.chi_phi (
id SERIAL PRIMARY KEY,
mo_ta TEXT,
so_tien DECIMAL(12,2),
ngay_chi DATE DEFAULT CURRENT_DATE
);
CREATE TABLE nhan_su.nhan_vien (
id SERIAL PRIMARY KEY,
ho_ten VARCHAR(100) NOT NULL,
phong_ban VARCHAR(50),
luong_co_ban DECIMAL(12,2),
ngay_vao_lam DATE
);
CREATE TABLE nhan_su.cham_cong (
id SERIAL PRIMARY KEY,
nhan_vien_id INT,
ngay_lam DATE,
so_gio_lam INT
);Schema “public” trong PostgreSQL
Trong PostgreSQL, schema mặc định là public. Nếu bạn không chỉ định schema khi tạo bảng, PostgreSQL sẽ tự đặt bảng vào public.
Cách chỉ định schema thường gặp:
- Gọi rõ tên schema khi tạo:
CREATE TABLE schema_name.customers (…) - Hoặc khi truy vấn cũng có thể dùng dạng: schema_name.table_name
-- Tạo bảng mà không chỉ định schema
CREATE TABLE products (
id INT PRIMARY KEY,
name VARCHAR(100)
);
-- Truy vấn bảng
SELECT * FROM products; -- OK
SELECT * FROM public.products; -- OK (tương đương)1.3 Database – container vật lý lớn nhất
- Trong PostgreSQL, có thể tạo nhiều database để làm nhà kho chứa dữ liệu.
- Mỗi database có 1 tên duy nhất, trong mỗi database chứa rất nhiều thứ như tables, schema, view, index, function, trigger, extension…
- Nói tóm tắt, database chứa dữ liệu (data) và thông tin mô tả dữ liệu (metadata)
- Các database độc lập nhau: có thể tách file lưu trữ, cấu hình, và trong PostgreSQL thường gắn với các cơ chế quản lý riêng.
- Xem nhẹ lệnh tạo database:
CREATE DATABASE cong_ty;2. KHÓA CHÍNH, KHÓA NGOẠI VÀ RÀNG BUỘC:
Khi lưu dữ liệu, vấn đề thường gặp là:
- nhập trùng,
- giá trị nhập lại bỏ sót các cột quan trọng,
- dữ liệu “mồ côi” (ví dụ như đơn hàng không có khách hàng),
- cập nhật lệch nhau.
RDBMS giải quyết việc này bằng 2 nhóm công cụ:
- Khóa (keys) để định danh và liên kết
- Ràng buộc (constraints) để bắt dữ liệu tuân thủ luật
2.1 Khóa chính (Primary Key)
Primary key là một hoặc nhiều cột dùng để định danh duy nhất mỗi dòng trong bảng. Ví dụ: Mỗi người có một CCCD duy nhất. Trong bảng khách hàng, id thường đóng vai trò đó.
Đặc điểm của khóa chính:
- Không được NULL (bỏ trống, rỗng)
- Giá trị phải duy nhất, không được trùng
- Mỗi bảng chỉ có một khóa chính
- Có thể là 1 cột hoặc nhiều cột kết hợp
Ví dụ tạo bảng:
CREATE TABLE khach_hang(
ma_kh INT PRIMARY KEY,
ho_ten VARCHAR(100),
email VARCHAR(100) UNIQUE
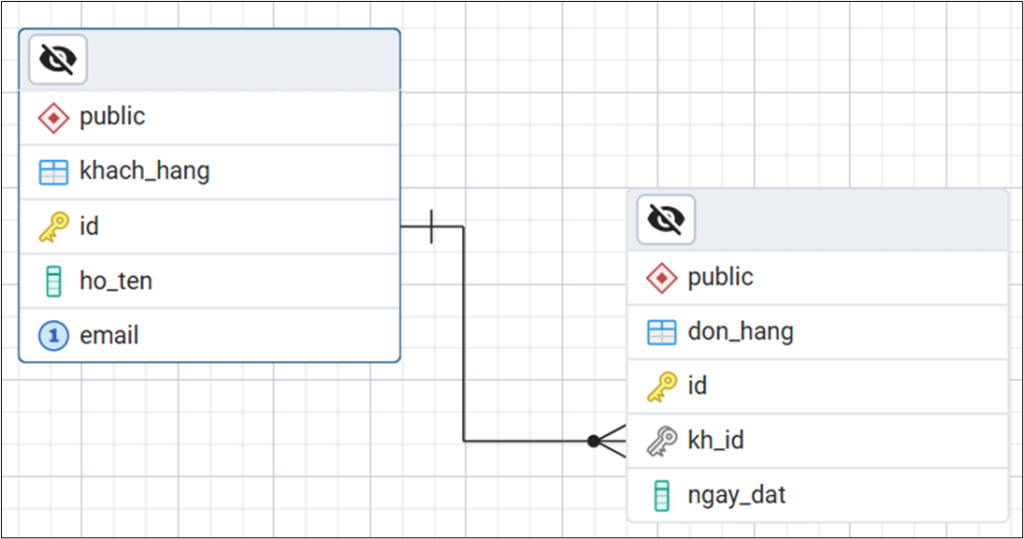
);2.2 Khóa ngoại (Foreign Key)
- Khóa ngoại là cột tham chiếu tới khóa chính của bảng khác.
- Sử dụng để thiết lập mối quan hệ giữa các bảng, đảm bảo tính toàn vẹn dữ liệu.
- Một bảng có thể có nhiều khóa ngoại => thiết lập nhiều mối quan hệ với nhiều bảng khác
CREATE TABLE khach_hang (
id INT PRIMARY KEY,
ho_ten VARCHAR(100),
email VARCHAR(100) UNIQUE
);
CREATE TABLE don_hang (
id INT PRIMARY KEY,
kh_id INT,
ngay_dat DATE,
FOREIGN KEY (kh_id) REFERENCES khach_hang(id)
);Ý nghĩa thực tế: Bạn không thể tạo một đơn hàng với kh_id không tồn tại trong bảng khách hàng
3. Constraints – “luật giao thông” của dữ liệu
Ràng buộc giúp dữ liệu đi đúng làn, đúng luật. Dưới đây là các loại rất hay dùng.
3.1. NOT NULL
Khi khai báo một cột là NOT NULL (không được trống), tức là khi thêm dòng dữ liệu mới, bắt buộc phải nhập dữ liệu cho cột đó.
Mục đích: đảm bảo cột không được để trống.
Thường dùng NOT NULL với các cột (trường) dữ liệu quan trọng như họ tên, email…
CREATE TABLE nhan_vien (
id INT PRIMARY KEY,
ho_ten VARCHAR(100) NOT NULL,
email VARCHAR(100) NOT NULL,
luong DECIMAL(10,2)
);Giải thích: với cấu trúc bảng như trên, khi bạn thêm 1 nhân viên mới vào bảng NhanVien thì phải khai báo:
- Mã nhân viên (id) vì là khóa chính
- Họ tên (ho_ten) vì NOT NULL
- Email (email) vì NOT NULL
- và có thể bỏ trống Lương
3.2. DEFAULT
Mục đích của ràng buộc DEFAULT cho cột là để gán giá trị mặc định khi không nhập dữ liệu cho cột.
DEFAULT sẽ giúp:
- giảm thao tác nhập liệu, giá trị nào xuất hiện nhiều nhất trong cột thường được khai báo trong default.
- đảm bảo cột không bị giá trị trống vô nghĩa,
- tạo dữ liệu nhất quán hơn.
CREATE TABLE san_pham (
id INT PRIMARY KEY,
ten_sp VARCHAR(100) NOT NULL,
gia DECIMAL(10,2) DEFAULT 0,
trang_thai VARCHAR(20) DEFAULT 'Còn hàng',
ngay_tao TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);Giải thích: Khi thêm sản phẩm mới vào bảng san_pham, nếu không điền dữ liệu cho:
- Giá (gia) thì Gia = 0
- Trạng thái (trang_thai) thì trang_thai = ‘Còn hàng’
- Ngày tạo (ngay_tao) thì ngay_tao = thời điểm hiện tại ở định dạng timestamp
3.3. UNIQUE
Ràng buộc UNIQUE nhằm đảm bảo các giá trị trong cột không bị trùng lặp.
- Một bảng có thể có nhiều cột UNIQUE
- UNIQUE có thể áp dụng trên 1 cột hoặc nhiều cột
- Khác với Primary Key, có thể chứa NULL
UNIQUE trên 1 cột
CREATE TABLE nhan_vien (
id INT PRIMARY KEY,
ho_ten VARCHAR(100) NOT NULL,
email VARCHAR(100) UNIQUE, --Email không trùng lặp
cccd VARCHAR(12) UNIQUE, -- CCCD không trùng lặp
so_dien_thoai VARCHAR(15) UNIQUE -- SĐT không trùng lặp
);UNIQUE trên nhiều cột
CREATE TABLE hoc_sinh (
id INT PRIMARY KEY,
ho_ten VARCHAR(100),
lop VARCHAR(10),
so_bao_danh INT,
UNIQUE (lop, so_bao_danh)
);Ý nghĩa: trong cùng một lớp, số báo danh không được trùng.
3.4. FOREIGN KEY
Khi có quan hệ, câu hỏi hay gặp là:
- Nếu xóa khách hàng, các đơn hàng đi đâu?
- Nếu sửa mã khách hàng, các đơn hàng cập nhật theo không?
Foreign key duy trì tính nhất quán dữ liệu giữa các bảng có mối quan hệ, ngăn chặn xóa/sửa dữ liệu gây mất liên kết
CREATE TABLE don_hang (
id INT PRIMARY KEY,
kh_id INT NOT NULL,
ngay_dat DATE DEFAULT CURRENT_DATE,
tong_tien DECIMAL(12,2) DEFAULT 0,
FOREIGN KEY (kh_id) REFERENCES khach_hang(id)
ON DELETE RESTRICT
ON UPDATE CASCADE
);Giải thích:Mã khách hàng (kh_id) tham chiếu đến id trong bảng khach_hang
=> Do đó: khi thêm đơn hàng vào bảng don_hang, thì giá trị của kh_id cần phải tồn tại trong bảng khach_hang. Không thể thêm đơn hàng mới với kh_id khôngtồn tại trong bảng khach_hang
3.5. Auto Increment (Tự động tăng)
Tự động sinh giá trị số nguyên tăng dần cho mỗi bản ghi mới. Auto Increment thường được dùng cho khóa chính (primary key). Trong PostgreSQL có 2 cách thực hiện: SERIAL (cũ) và IDENTITY (mới)
Sử dụng SERIAL (cách cũ)
CREATE TABLE san_pham (
id SERIAL PRIMARY KEY,
ten_sp VARCHAR(100) NOT NULL,
gia DECIMAL(10,2)
);
CREATE TABLE don_hang (
id SERIAL PRIMARY KEY,
kh_id INT,
ngay_dat DATE DEFAULT CURRENT_DATE
);Sử dụng IDENTITY (cách mới, SQL chuẩn)
CREATE TABLE san_pham (
id INT GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
ten_sp VARCHAR(100) NOT NULL,
gia DECIMAL(10,2)
);
CREATE TABLE don_hang (
id INT GENERATED BY DEFAULT AS IDENTITY,
kh_id INT,
ngay_dat DATE DEFAULT CURRENT_DATE
);4. MỐI QUAN HỆ TRONG CƠ SỞ DỮ LIỆU
Trong cơ sở dữ liệu có 3 mối quan hệ cơ bản là 1-1, 1-n, n-n
4.1. One-to-One (1-1)
Một bản ghi trong bảng A chỉ liên kết với đúng một bản ghi trong bảng B, và ngược lại. Ví dụ:
Nhân viên và Thẻ nhân viên: Mỗi nhân viên có 1 thẻ nhân viên duy nhất, mỗi thẻ chỉ thuộc về 1 nhân viên.
Người dùng và Giỏ hàng: Mỗi người dùng có 1 giỏ hàng duy nhất, và mỗi giỏ hàng chỉ thuộc về 1 người dùng.
4.2. One-to-Many (1-n)
Một bản ghi trong bảng A có thể liên kết với nhiều bản ghi trong bảng B, nhưng mỗi bản ghi trong bảng B chỉ liên kết với một bản ghi trong bảng A
Ví dụ: Khách hàng và Đơn hàng: Một khách hàng có thể có nhiều đơn hàng, nhưng mỗi đơn hàng chỉ thuộc về một khách hàng duy nhất
4.3. Many-to-Many (n-n)
Một bản ghi trong bảng A có thể liên kết với nhiều bản ghi trong bảng B, và ngược lại.
Lưu ý: Mối quan hệ này khi đưa vào CSDL vật lý thì cần phải sử dụng một bảng trung gian để thực hiện
Ví dụ: Đơn hàng và Sản phẩm: Một đơn hàng có thể có nhiều sản phẩm, và mỗi sản phẩm cũng có thể thuộc (nằm trong) nhiều đơn hàng khác nhau
Sinh viên và Môn học: Một sinh viên có thể học nhiều môn, và mỗi môn học có nhiều sinh viên học.
KẾT LUẬN
Thông qua bài học các khái niệm cơ bản trong RDBMS, chúng ta đã làm quen với những thành phần nền tảng của cơ sở dữ liệu quan hệ như bảng, hàng, cột, schema, database, khóa chính, khóa ngoại và các ràng buộc dữ liệu.
Những khái niệm này giúp hệ quản trị cơ sở dữ liệu đảm bảo rằng dữ liệu không tồn tại một cách “tự do”, mà luôn được quản lý theo những quy tắc rõ ràng nhằm đảm bảo:
- Tính duy nhất (không trùng lặp dữ liệu)
- Tính đầy đủ (không bỏ sót thông tin quan trọng)
- Tính nhất quán (dữ liệu giữa các bảng không mâu thuẫn)
- Tính toàn vẹn (không tồn tại dữ liệu mồ côi)
Việc hiểu rõ các khái niệm cơ bản trong RDBMS là bước chuẩn bị quan trọng trước khi tiếp tục học các kỹ thuật làm việc với dữ liệu như:
- truy vấn dữ liệu bằng SQL
- làm sạch dữ liệu (data cleaning)
- phân tích dữ liệu (data analysis)
- xây dựng pipeline dữ liệu
Nói cách khác, các khái niệm cơ bản trong RDBMS chính là nền móng của toàn bộ hệ thống dữ liệu. Khi nắm vững phần này, việc học SQL và các kỹ thuật phân tích dữ liệu phía sau sẽ trở nên rõ ràng và dễ tiếp cận hơn rất nhiều.


