Phân phối đều và phân phối đa đỉnh trong thống kê là hai cách rất khác nhau để nhìn dữ liệu. Chúng thường xuất hiện ở những thời điểm quan trọng trong quá trình phân tích và xây dựng mô hình.
Một bên đại diện cho trạng thái “chưa biết gì thêm”. Bên còn lại cho thấy dữ liệu thực chất là sự pha trộn của nhiều nhóm khác nhau.
Hiểu rõ hai dạng phân phối này giúp bạn tránh được nhiều kết luận sai ngay từ bước đầu.
Phân phối đều (Uniform)
Phân phối đều là dạng phân phối đơn giản nhất. Mọi giá trị trong một khoảng xác định đều có khả năng xảy ra như nhau.
Phân phối này không có giá trị trung tâm. Nó cũng không có xu hướng nghiêng về bên nào. Vì vậy, phân phối đều không phản ánh một “điển hình” cụ thể trong dữ liệu.
Có thể gặp phân phối đều ở đâu?
Trong dữ liệu thật, bạn hiếm khi gặp phân phối đều. Vì con người, hệ thống và tự nhiên thường có xu hướng ưu tiên một số giá trị nhất định.
Phân phối đều lại thường xuất hiện trong quá trình xây dựng mô hình, lúc này chưa có dữ liệu.
Thứ nhất, phân phối đều được dùng nhiều trong mô phỏng ngẫu nhiên. Khi mô phỏng một hiện tượng, ta cần tạo ra các kịch bản một cách công bằng. Nếu chưa có lý do gì để tin rằng kịch bản này xảy ra nhiều hơn kịch bản khác, phân phối đều là lựa chọn tự nhiên nhất.
Thứ hai, phân phối đều dùng trong khởi tạo tham số của thuật toán. Khi một mô hình học máy bắt đầu học, các tham số ban đầu thường được gán các giá trị ngẫu nhiên. Ở thời điểm đó, mô hình chưa biết đặc trưng nào quan trọng hơn. Vì vậy, mọi giá trị được đối xử như nhau. Phân phối đều được dùng để tránh thiên lệch ngay từ đầu.
Thứ ba, phân phối đều thường được dùng như giả định ban đầu khi chưa có dữ liệu. Trong nhiều bài toán, ta chưa có quan sát cụ thể. Thay vì đoán mò, ta chọn phân phối đều để thể hiện rằng mình “chưa biết gì thêm”. Khi dữ liệu thật xuất hiện, giả định này sẽ dần được thay thế bằng một phân phối phản ánh đúng thực tế hơn.
Nói ngắn gọn, phân phối đều hiếm khi mô tả thế giới như nó vốn có. Nó thường xuất hiện trước khi dữ liệu xuất hiện, ở giai đoạn mà chúng ta chưa đủ thông tin.
Dùng phân phối đều khi nào?
Bạn nên nghĩ đến phân phối đều khi:
- bạn chỉ biết giới hạn trên và dưới của một đại lượng
- không có lý do gì để ưu tiên giá trị nào ở giữa
Code Python và đồ thị phân phối đều
import numpy as np
import matplotlib.pyplot as plt
samples = np.random.uniform(0, 10, size=20000)
plt.hist(samples, bins=40, density=True)
plt.title("Phân phối đều")
plt.xlabel("Giá trị")
plt.ylabel("Mật độ")
plt.show()
Phân phối đa đỉnh (Multimodal distribution)
Phân phối đa đỉnh là dạng phân phối trong đó đồ thị có nhiều hơn một đỉnh. Mỗi đỉnh thường tương ứng với một nhóm dữ liệu khác nhau.
Các đỉnh này không đơn thuần là nhiễu ngẫu nhiên. Chúng phản ánh những cấu trúc khác nhau bên trong dữ liệu.
Không giống các phân phối một đỉnh như phân phối chuẩn hay phân phối mũ, phân phối đa đỉnh không có một trung tâm duy nhất.
Trong nhiều trường hợp, giá trị trung bình nằm ở vị trí mà rất ít dữ liệu thực sự tồn tại. Khi đó, trung bình trở nên kém đại diện.
Có thể gặp phân phối đa đỉnh ở đâu?
Phân phối đa đỉnh xuất hiện rất thường xuyên khi dữ liệu đến từ nhiều quần thể khác nhau, nhưng lại được gộp chung thành một tập duy nhất.
Một ví dụ kinh điển là chiều cao con người. Khi gộp chiều cao của nam và nữ vào cùng một tập dữ liệu, histogram thường xuất hiện hai đỉnh rõ rệt. Mỗi đỉnh đại diện cho một nhóm, chứ không phải do đo sai hay nhiễu.
Trong AI và dữ liệu hành vi, phân phối đa đỉnh còn phổ biến hơn nữa:
- hành vi của người dùng mới và người dùng lâu năm
- dữ liệu trước và sau một thay đổi hệ thống
- các nhóm khách hàng khác nhau
- nhiều chế độ hoạt động của cùng một hệ thống
Bạn cũng có thể gặp phân phối đa đỉnh trong:
- thời gian phản hồi khi hệ thống có nhiều mức tải
- điểm số khi đề thi có nhiều mức độ khó
- dữ liệu cảm biến trong các trạng thái vận hành khác nhau
Trong những trường hợp này, việc gộp dữ liệu lại và cố mô hình hóa bằng một phân phối duy nhất thường dẫn đến hiểu sai bản chất của dữ liệu.
Dùng phân phối đa đỉnh khi nào?
Bạn nên nghĩ đến phân phối đa đỉnh khi:
- histogram có nhiều đỉnh rõ ràng
- giá trị trung bình không đại diện cho “điển hình”
- dữ liệu đến từ nhiều nguồn hoặc nhiều trạng thái
- việc tách dữ liệu theo nhóm làm hình dạng trở nên đơn giản hơn
Trong các tình huống này, tiếp tục phân tích trên tập dữ liệu gộp có thể che giấu những cấu trúc quan trọng. Thay vào đó, tách nhóm hoặc mô hình hóa bằng phân phối hỗn hợp sẽ hợp lý hơn.
Ví dụ dữ liệu
Hãy tưởng tượng bạn phân tích thời gian sử dụng ứng dụng của người dùng. Người dùng mới thường sử dụng trong thời gian ngắn. Người dùng lâu năm lại có xu hướng sử dụng lâu hơn.
Khi gộp hai nhóm này lại, histogram sẽ xuất hiện hai đỉnh rõ rệt. Nếu chỉ nhìn vào giá trị trung bình, bạn sẽ khó hiểu được hành vi thật sự của cả hai nhóm.
Khi tách dữ liệu theo nhóm người dùng, mỗi nhóm lại có hình dạng rõ ràng hơn. Việc phân tích cũng trở nên dễ dàng hơn.
Code Python và đồ thị
import numpy as np
import matplotlib.pyplot as plt
# Ví dụ: phân phối đa đỉnh bằng cách trộn hai nhóm dữ liệu
group_1 = np.random.normal(loc=30, scale=5, size=10000)
group_2 = np.random.normal(loc=60, scale=5, size=10000)
samples = np.concatenate([group_1, group_2])
plt.hist(samples, bins=50, density=True)
plt.title("Phân phối đa đỉnh")
plt.xlabel("Giá trị")
plt.ylabel("Mật độ")
plt.show()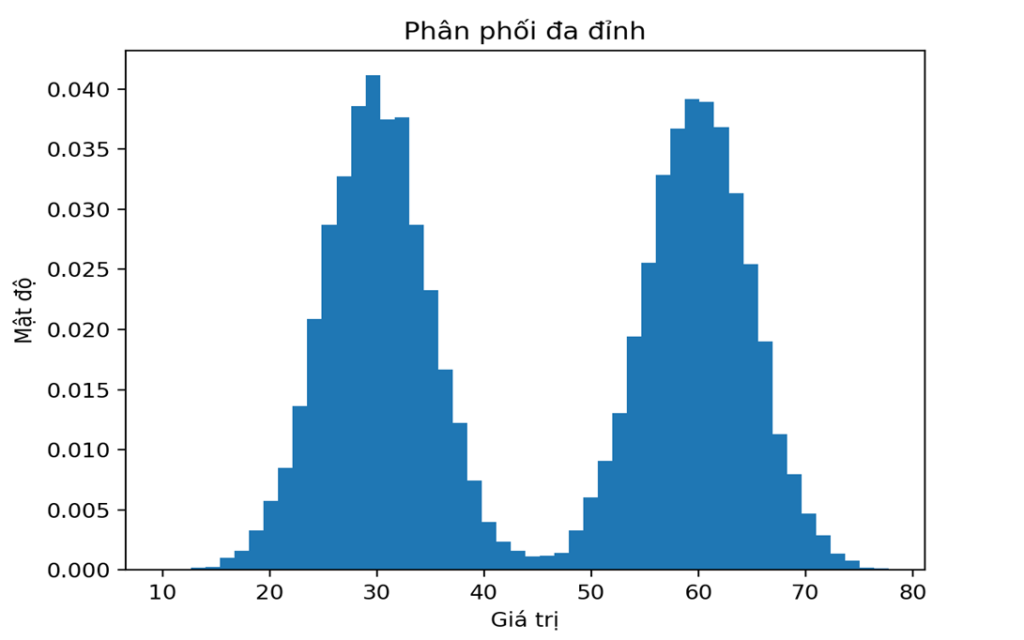
Đặc điểm thấy rõ trên biểu đồ:
- Có nhiều hơn một đỉnh
- Không có trung tâm duy nhất
- Trung bình nằm giữa các đỉnh
- Dữ liệu thực chất là sự trộn lẫn của nhiều nhóm
Kết luận
Phân phối đều và phân phối đa đỉnh đại diện cho hai tình huống rất khác nhau trong phân tích dữ liệu.
Phân phối đều thường xuất hiện khi chúng ta chưa có đủ thông tin. Ngược lại, phân phối đa đỉnh cho thấy dữ liệu thực chất đến từ nhiều nhóm khác nhau.
Hiểu được hai dạng phân phối này giúp bạn tránh việc gán nhầm ý nghĩa cho trung bình. Nó cũng giúp bạn biết khi nào nên giữ giả định đơn giản, và khi nào cần tách dữ liệu để nhìn rõ cấu trúc bên trong.
Trong bài tiếp theo, chúng ta sẽ tiếp tục nhìn vào hình dạng của dữ liệu. Trọng tâm sẽ là phân phối lệch trái và phân phối lệch phải.
Đây là hai dạng phân phối xuất hiện rất phổ biến trong dữ liệu thật. Chúng có ảnh hưởng mạnh đến cách ta diễn giải trung bình và rủi ro.


