Trực quan hóa dữ liệu trong lập trình AI là bước nền tảng giúp người học biến dữ liệu thô thành các biểu đồ trực quan, dễ quan sát và dễ phân tích. Thông qua trực quan hóa, chúng ta có thể hiểu phân phối dữ liệu, phát hiện xu hướng, nhận diện outlier, quan sát mối quan hệ giữa các biến và phát hiện những vấn đề như missing values hoặc dữ liệu bất thường.
Trong quá trình xây dựng mô hình AI, trực quan hóa dữ liệu không chỉ dùng để trình bày kết quả mà còn hỗ trợ mạnh mẽ cho bước khám phá dữ liệu, lựa chọn đặc trưng, đánh giá mô hình và phát hiện overfitting hoặc underfitting. Các biểu đồ như histogram, box plot, scatter plot, heatmap, line chart, pair plot và confusion matrix giúp người học hiểu rõ hơn bản chất dữ liệu trước khi đưa dữ liệu vào mô hình.
Vì vậy, nắm vững trực quan hóa dữ liệu trong lập trình AI là một bước quan trọng để học tốt phân tích dữ liệu, machine learning và các ứng dụng AI thực tế.
1. Trực quan hóa dữ liệu trong lập trình AI là gì
Trực quan hóa dữ liệu là quá trình biến dữ liệu thành hình ảnh. Những con số được ánh xạ thành vị trí, màu sắc, kích thước hoặc hình dạng, từ đó giúp não bộ dễ dàng nhận diện và hiểu được thông tin ẩn bên trong.
Nếu ví von một cách trực quan:
Máy tính đọc dữ liệu dưới dạng 0 và 1, còn con người đọc dữ liệu thông qua hình ảnh. Trực quan hóa dữ liệu chính là “trình biên dịch” giữa hai thế giới đó.
2. Vai trò của trực quan hóa dữ liệu trong lập trình AI
Trong lập trình AI, trực quan hóa dữ liệu giữ vai trò rất quan trọng vì nó giúp người học hiểu dữ liệu trước khi xây dựng mô hình. Thông qua biểu đồ, chúng ta có thể nhận ra cách phân phối của dữ liệu, những xu hướng của dữ liệu, các cụm dữ liệu, quan sát được mối quan hệ giữa các biến và các điểm dữ liệu bất thường. Nhờ đó, việc lựa chọn các đặc trưng, việc chọn mô hình phù hợp và đánh giá kết quả trở nên chính xác và hiệu quả hơn. Nói cách khác, trực quan hóa dữ liệu là bước giúp biến dữ liệu thô thành thông tin có ý nghĩa trong quá trình phát triển AI.
3. Từ dữ liệu đến hành động: Hành trình DIKW
Để thấy rõ vai trò của trực quan hóa, ta có thể nhìn vào mô hình DIKW – một mô hình kinh điển trong khoa học dữ liệu:
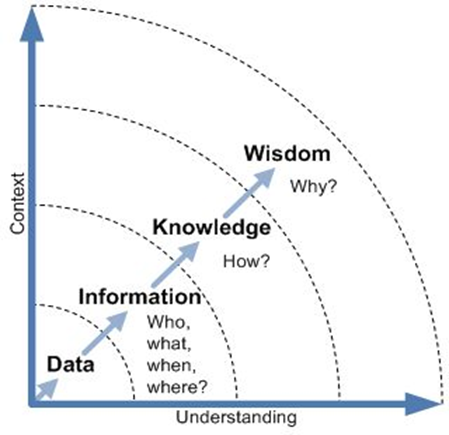
- Data (Dữ liệu): các con số thô, chưa có ý nghĩa
- Information (Thông tin): dữ liệu đã được tổ chức
- Knowledge (Tri thức): hiểu được quy luật
- Wisdom (Hành động): đưa ra quyết định
Trực quan hóa không đơn thuần chỉ là “trang trí dữ liệu”. Nó là công cụ giúp ta bước từ Information sang Knowledge – từ việc “biết” sang “hiểu”, biến dữ liệu thành tri thức.
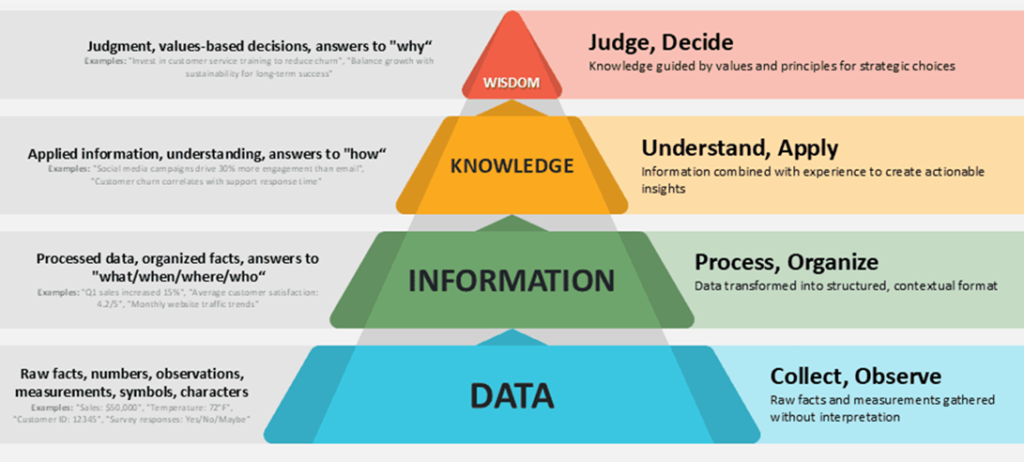
4. Hai cách nhìn dữ liệu: Reporting và Analysis
Trong thực tế, dữ liệu thường được sử dụng theo hai mục đích chính.
- Reporting (báo cáo). Đây là cách sử dụng dữ liệu để:
- Trả lời câu hỏi: “Chuyện gì đã xảy ra?”
- Công cụ sử dụng: Excel, Power BI, Tableau
- Mục tiêu: theo dõi KPI, tổng hợp số liệu, báo cáo cho quản lý
- Analysis (phân tích – EDA). Đây mới là nơi trực quan hóa thực sự phát huy sức mạnh. Phân tích dữ liệu giúp :
- Trả lời câu hỏi: “Tại sao nó xảy ra?”
- Công cụ: Python, Jupyter Notebook. Google Colab
- Mục tiêu: tìm quy luật, phát hiện lỗi, tối ưu mô hình AI
Trong AI, EDA (Exploratory Data Analysis) là bước không thể thiếu trước khi xây dựng mô hình. Nếu bỏ qua bước này, bạn đang “dạy” mô hình học từ dữ liệu mà chính bạn còn chưa hiểu.
5. Số liệu có thể đánh lừa chúng ta
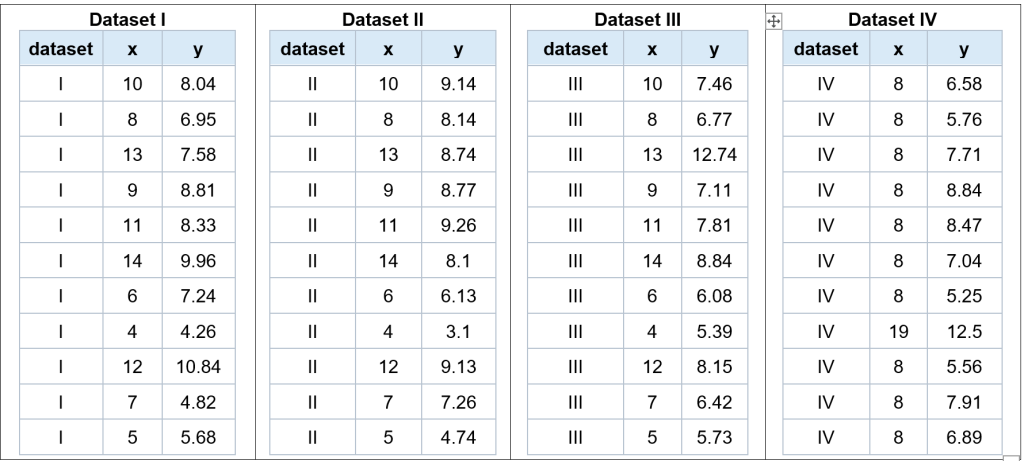
Một ví dụ rất nổi tiếng trong thống kê là Anscombe’s Quartet — gồm bốn bộ dữ liệu có các chỉ số thống kê gần như giống nhau: cùng giá trị trung bình, cùng phương sai và cùng hệ số tương quan.
Nếu chỉ nhìn vào các con số này, ta rất dễ cho rằng bốn bộ dữ liệu có bản chất tương tự nhau. Tuy nhiên, khi biểu diễn chúng bằng biểu đồ, ta sẽ thấy mỗi bộ dữ liệu lại có hình dạng hoàn toàn khác nhau: có bộ thể hiện quan hệ tuyến tính rõ ràng, có bộ mang dạng phi tuyến, có bộ bị ảnh hưởng mạnh bởi điểm ngoại lai.
Điều đó cho thấy một bài học quan trọng: nếu không trực quan hóa dữ liệu, chúng ta rất dễ hiểu sai bản chất thực sự của nó.
Anscombe’s Quartet là tập hợp bốn bộ dữ liệu do nhà thống kê Francis Anscombe giới thiệu vào năm 1973 nhằm minh họa rằng các thống kê mô tả giống nhau chưa chắc phản ánh cùng một cấu trúc dữ liệu.
1. Tính mean và variance (phương sai)
import pandas as pd
df = pd.read_csv('anscombe.csv')
print(df.groupby('dataset').mean()) # Mean theo từng dataset
print(df.groupby('dataset').var()) # Variance theo từng dataset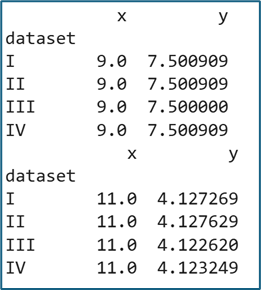
Ta thấy: Mean(x) ≈ 9, Mean(y) ≈ 7.5, phương sai gần như giống nhau
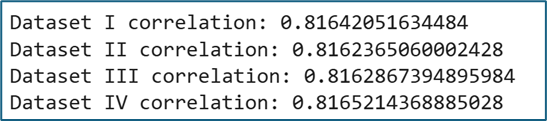
2. Xem tương quan correlation
for name, group in df.groupby('dataset'):
corr = group['x'].corr(group['y'])
print(f"Dataset {name} correlation:", corr)Kết quả như nhau:
3. Xem phân phối của các bộ dữ liệu:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('anscombe.csv')
sns.lmplot(x='x', y='y', col='dataset', data=df, ci=None)
plt.show()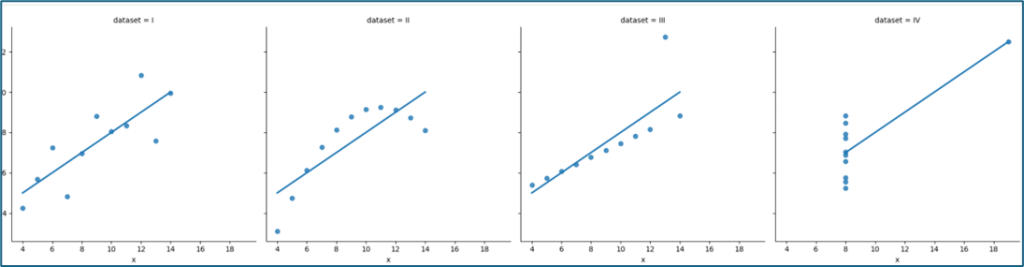
Nhận xét từng hình:
- Dataset I: Phân bố tuyến tính rõ ràng, dữ liệu “đẹp”, phù hợp hồi quy
- Dataset II: Dạng cong (phi tuyến), hồi quy tuyến tính là không phù hợp
- Dataset III: Gần tuyến tính. nhưng có 1 outlier rất lớn, điểm này làm lệch đường hồi quy
- Dataset IV: Hầu hết điểm có x giống nhau. Chỉ 1 điểm kéo toàn bộ đường hồi quy. Tương quan bị “lừa”
Kết luận: Mặc dù các bộ dữ liệu có cùng mean, variance (phương sai) và correlation, nhưng phân bố dữ liệu hoàn toàn khác nhau khi trực quan hóa. Điều này cho thấy các thống kê mô tả không đủ để phản ánh bản chất dữ liệu. Việc trực quan hóa là cần thiết để phát hiện các đặc điểm như quan hệ phi tuyến hoặc sự tồn tại của outliers.
Kết quả cho thấy việc chỉ dựa vào các thống kê mô tả là không đủ để hiểu dữ liệu. Do đó, con người đóng vai trò quan trọng trong quá trình phân tích dữ liệu thông qua việc trực quan hóa và diễn giải kết quả, từ đó lựa chọn mô hình và phương pháp phù hợp.
6. Khám phá những gì dữ liệu đang ẩn chứa
Exploratory Data Analysis (EDA) không chỉ là việc vẽ biểu đồ để trình bày dữ liệu. Đây là quá trình khám phá các đặc điểm, quy luật và cấu trúc ẩn bên trong dữ liệu.
Khi thực hiện EDA, chúng ta thường quan tâm đến ba yếu tố quan trọng:
- Mẫu (pattern): dữ liệu có tuân theo một quy luật nào hay không?
- Xu hướng (trend): dữ liệu có xu hướng tăng, giảm, tuyến tính hay phi tuyến?
- Cụm (Clusters): dữ liệu có tự hình thành các nhóm riêng biệt hay không?
Những quan sát này không chỉ giúp mô tả dữ liệu mà còn ảnh hưởng trực tiếp đến việc lựa chọn mô hình phù hợp trong AI. Ví dụ:
- Dữ liệu có quan hệ tuyến tính thì phù hợp với Linear Regression
- Dữ liệu có quan hệ phi tuyến thì cần các mô hình linh hoạt hơn như Decision Tree, Random Forest hoặc Neural Network.
- Dữ liệu có xu hướng phân thành các nhóm, có thể áp dụng các thuật toán phân cụm như K-Means ở môn Máy học cơ bản.
Qua đó, EDA đóng vai trò quan trọng trong việc hiểu dữ liệu trước khi xây dựng mô hình, giúp chúng ta chọn đúng phương pháp thay vì áp dụng thuật toán một cách máy móc.
7. Garbage In – Garbage Out
Một trong những nguyên lý quan trọng nhất trong khoa học dữ liệu là: “Garbage In, Garbage Out” – dữ liệu đầu vào sai → kết quả sai. Chỉ cần một vài điểm dữ liệu lỗi, toàn bộ mô hình có thể bị ảnh hưởng nghiêm trọng. Một outlier cũng có thể “bẻ cong” đường hồi quy.
Do đó, trước khi phân tích hay huấn luyện mô hình, ta phải làm sạch dữ liệu.
8. Trực quan hóa hỗ trợ làm sạch dữ liệu
Trực quan hóa không chỉ giúp hiểu dữ liệu, mà còn giúp phát hiện lỗi nhanh hơn bất kỳ câu lệnh SQL nào. Hai vấn đề phổ biến nhất là:
Phát hiện giá trị thiếu (Missing Values)
Sử dụng heatmap để phát hiện những vùng dữ liệu bị khuyết. Vì heatmap biến dữ liệu thành tín màu sắc, nên mắt người có thể phát hiện rất nhanh các vùng bất thường.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.DataFrame({
'Age': [23, 25, None, 30, 28],
'Salary': [500, None, 700, 800, None],
'Score': [8.5, 7.0, 9.0, None, 8.0]
})
# Vẽ heatmap missing values
sns.heatmap(df.isnull(), cmap='viridis', cbar=False)
plt.title("Missing Values Heatmap")
plt.show()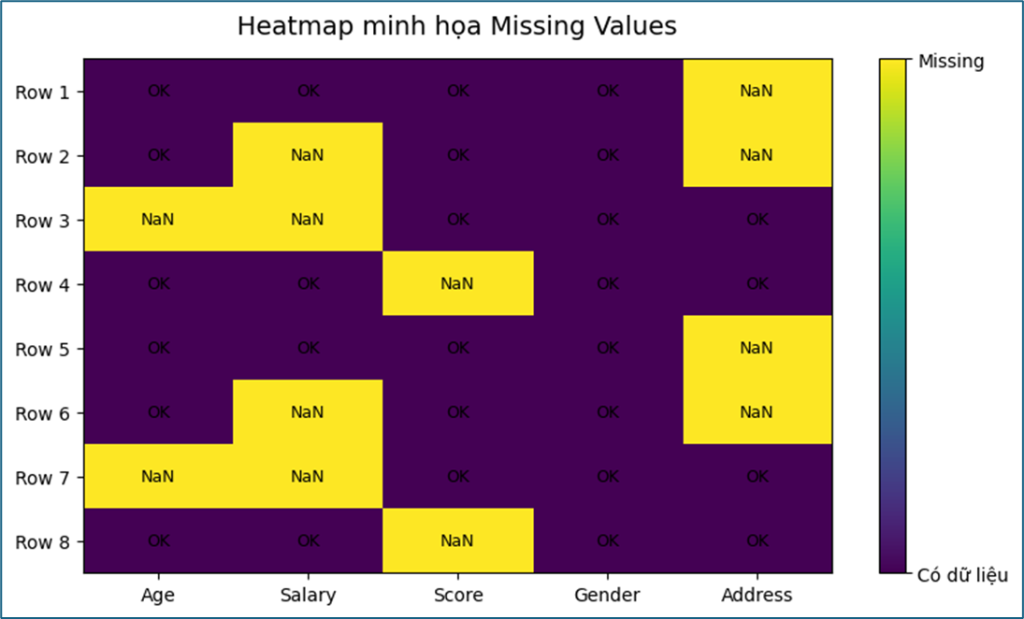
Điều này đặc biệt quan trọng khi làm việc với dữ liệu lớn.
Phát hiện giá trị ngoại lai (outliers)
Trực quan cũng giúp chúng ta phát hiện các giá trị ngoại lai rất tốt. Outlier có thể là:
- Nhiễu (noise) → nên loại bỏ
- Hiện tượng bất thường (anomaly) → cần phân tích sâu
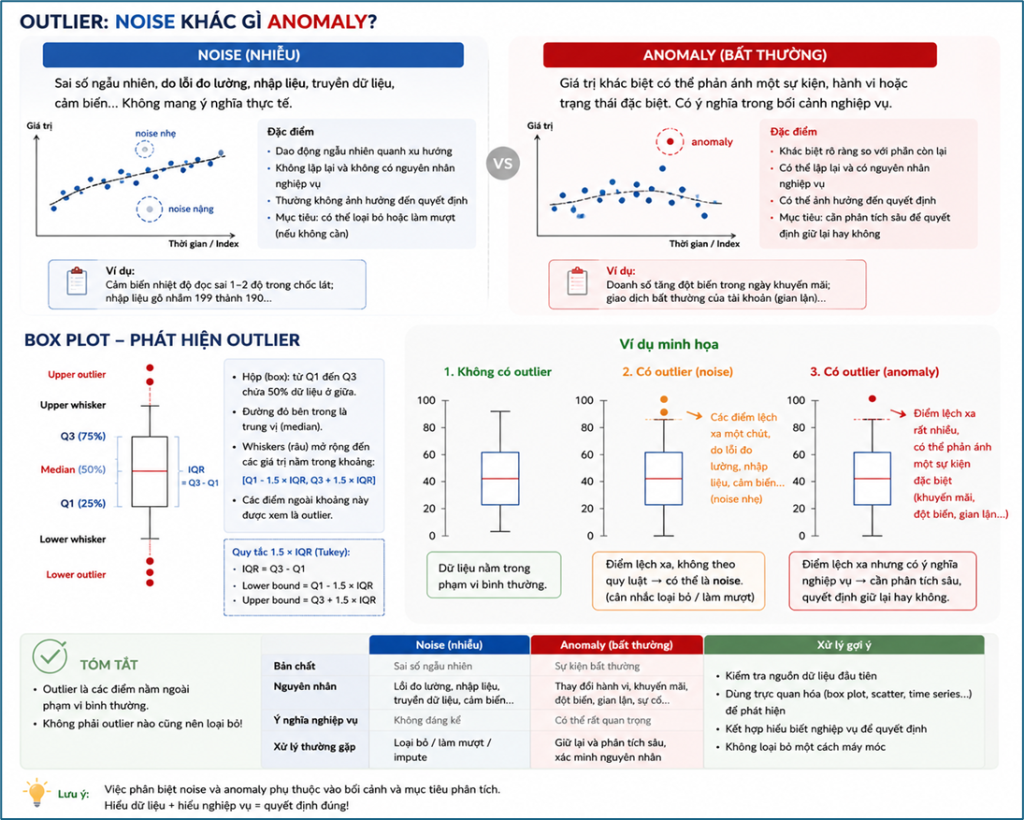
Biểu đồ hiệu quả nhất trong trường hợp này là box plot, giúp nhanh chóng xác định những điểm nằm ngoài phạm vi bình thường.
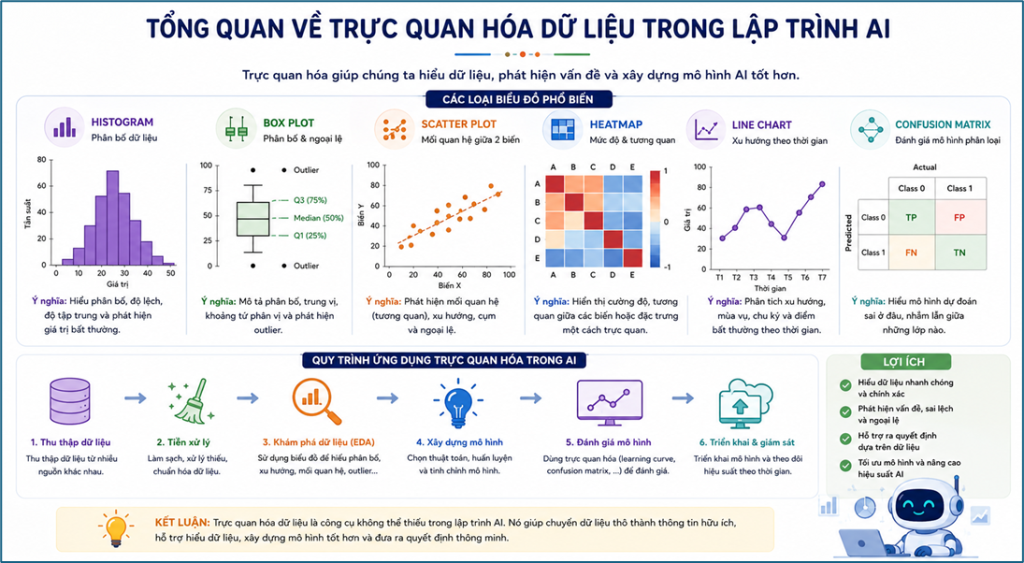
9. Các loại biểu đồ quan trọng trong AI
Có một số loại biểu đồ mà bất kỳ ai học và làm AI cũng nên nắm vững. Mỗi loại biểu đồ giúp chúng ta nhìn dữ liệu theo một góc khác nhau, từ phân phối, mối quan hệ giữa các biến cho đến cấu trúc nhóm và xu hướng theo thời gian.
Histogram – Hiểu phân phối của dữ liệu
Histogram giúp quan sát cách dữ liệu được phân bố. Thông qua biểu đồ này, ta có thể nhận biết:
- dữ liệu có gần với phân phối chuẩn (Gaussian) hay không,
- dữ liệu có lệch trái hoặc lệch phải hay không,
- dữ liệu tập trung hay phân tán,
- có dấu hiệu bất thường trong phân phối hay không.
Đây là biểu đồ rất hữu ích trong bước đầu khám phá dữ liệu, vì nhiều mô hình và phương pháp thống kê phụ thuộc vào đặc điểm phân phối của biến.
Box Plot – Phát hiện giá trị bất thường
Box Plot giúp tóm tắt nhanh phân bố của dữ liệu và đặc biệt hữu ích trong việc phát hiện outlier. Biểu đồ này cho biết:
- Median (trung vị),
- Q1 và Q3,
- khoảng tứ phân vị (IQR),
- các giá trị bất thường nằm ngoài phạm vi thông thường.
Nhờ đó, người phân tích có thể nhanh chóng phát hiện các điểm dữ liệu bất thường trước khi xây dựng mô hình.
Scatter Plot – Quan sát mối quan hệ giữa hai biến
Scatter Plot giúp thể hiện mối quan hệ giữa hai biến số. Đây là một trong những cách trực quan nhất để kiểm tra: hai biến có liên hệ với nhau hay không, mối quan hệ đó là tuyến tính hay phi tuyến, dữ liệu có xuất hiện cụm, xu hướng, hay outlier hay không. Tùy mối quan hệ mà chúng ta sẽ chọn mô hình cho bước sau:
- nếu mối quan hệ gần tuyến tính, ta có thể nghĩ đến Linear Regression;
- nếu quan hệ phi tuyến, có thể cần các mô hình linh hoạt hơn như Decision Tree, Random Forest hoặc Neural Network;
- nếu hai biến gần như không có liên hệ rõ ràng, ta cần xem xét thêm trước khi quyết định có nên sử dụng đặc trưng đó hay không.
Ví dụ minh họa:
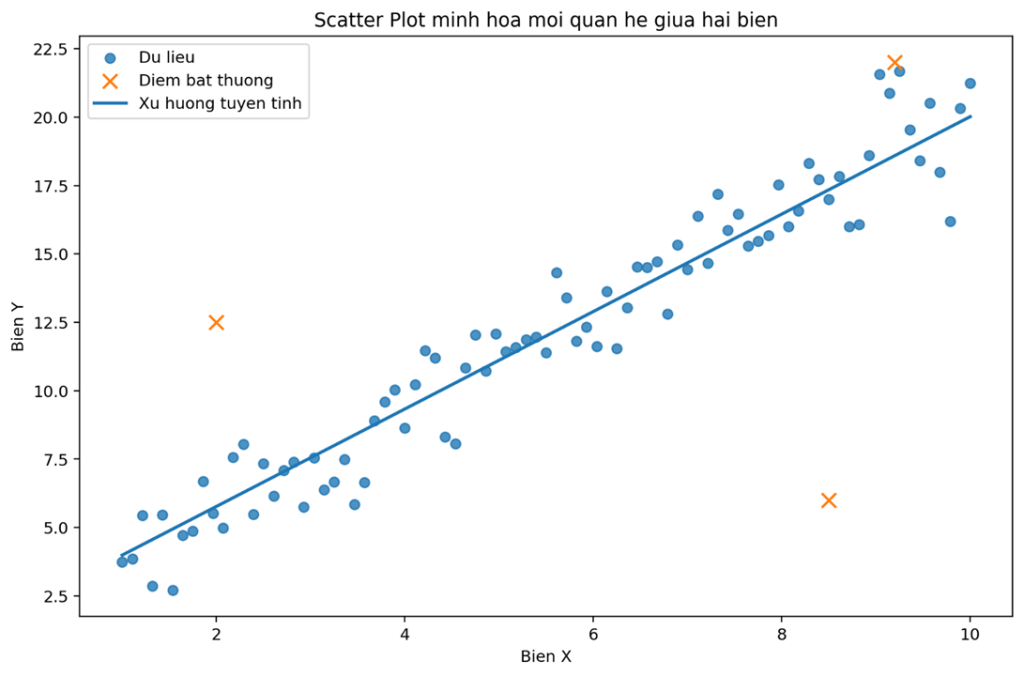
- Các điểm có xu hướng đi lên từ trái sang phải → cho thấy tương quan dương
- Đường thẳng minh họa cho thấy mối quan hệ gần tuyến tính
- Một vài điểm đánh dấu X là điểm bất thường (outlier), có thể ảnh hưởng đến phân tích và mô hình
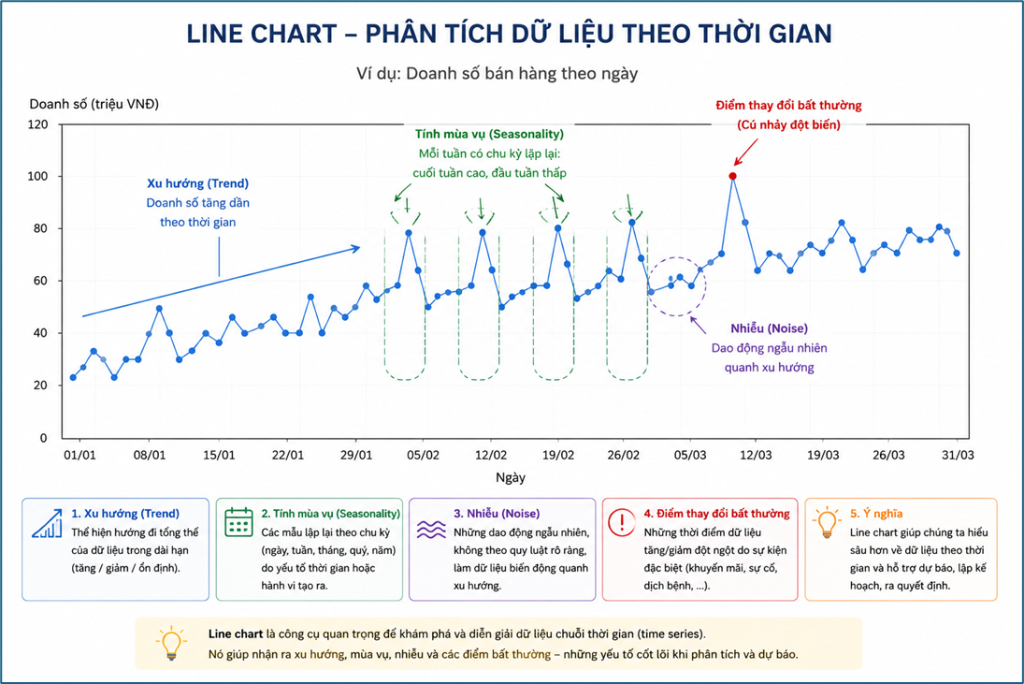
Line Chart – Phân tích dữ liệu theo thời gian
Line Chart thường được dùng với dữ liệu chuỗi thời gian để theo dõi sự thay đổi của một biến theo thời gian. Biểu đồ này giúp nhận ra:
- xu hướng dài hạn (trend): tăng dần, giảm dần hay ổn định.
- tính mùa vụ (seasonality): các mẫu dữ liệu lặp lại theo chu kỳ ngày, tuần, tháng, quý, năm.
- nhiễu (noise): những dao động ngẫu nhiên, nhỏ, không theo quy luật rõ ràng.
- các điểm thay đổi bất thường theo thời gian: là những thời điểm dữ liệu đột ngột tăng/giảm mạnh, hoặc thay đổi khác thường so với mức bình thường.
Đây là loại biểu đồ quan trọng trong các bài toán dự báo, giám sát hệ thống và phân tích hành vi theo thời gian.
Heatmap – Ma trận tương quan
Heatmap thường được dùng để biểu diễn ma trận tương quan giữa các biến. Nó giúp ta nhanh chóng phát hiện:
- các biến có tương quan mạnh hoặc yếu,
- mối quan hệ đồng biến hay nghịch biến,
- hiện tượng đa cộng tuyến giữa các đặc trưng.
Trong phân tích dữ liệu và xây dựng mô hình, heatmap rất hữu ích cho bước feature selection, đặc biệt khi cần loại bớt những biến trùng lặp thông tin.
Ví dụ:
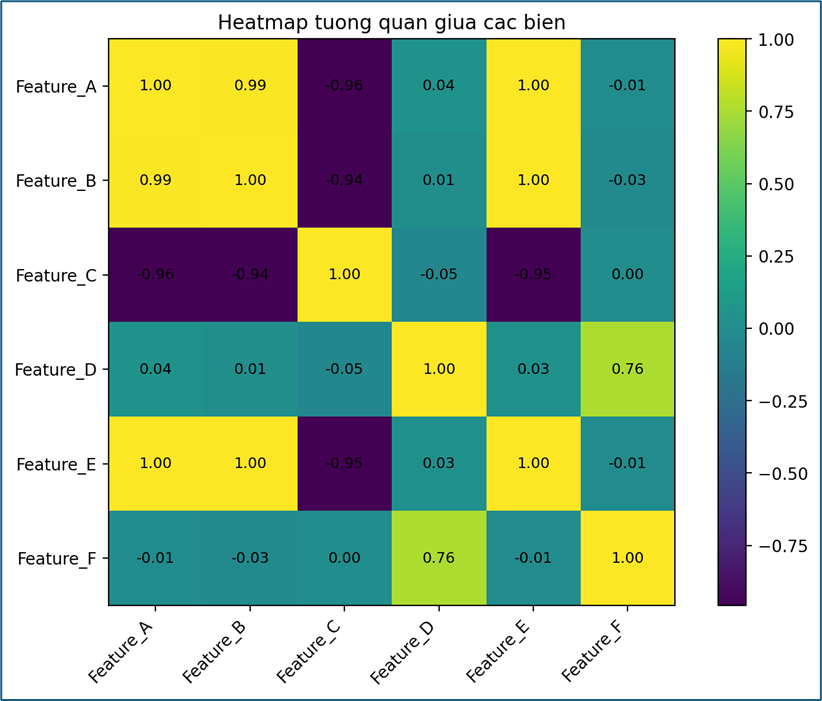
- Feature_A và Feature_B có tương quan rất mạnh: 0.99
- Feature_A và Feature_E, Feature_B và Feature_E gần như trùng nhau: 1.00 → đây là dấu hiệu đa cộng tuyến rất mạnh
- Feature_C tương quan âm mạnh với A/B/E
- Feature_D và Feature_F có tương quan mức khá: 0.76
Pair Plot – Cái nhìn toàn cảnh
Pair Plot hiển thị đồng thời:
- phân phối của từng biến,
- mối quan hệ giữa từng cặp biến.
Nhờ đó, ta có thể có cái nhìn tổng quát về toàn bộ bộ dữ liệu, phát hiện xu hướng, cụm, outlier, và trong một số trường hợp có thể quan sát sơ bộ khả năng tách lớp giữa các nhóm dữ liệu.
Đây là công cụ rất phù hợp khi làm việc với các bộ dữ liệu có số lượng biến không quá lớn.
Ví dụ:
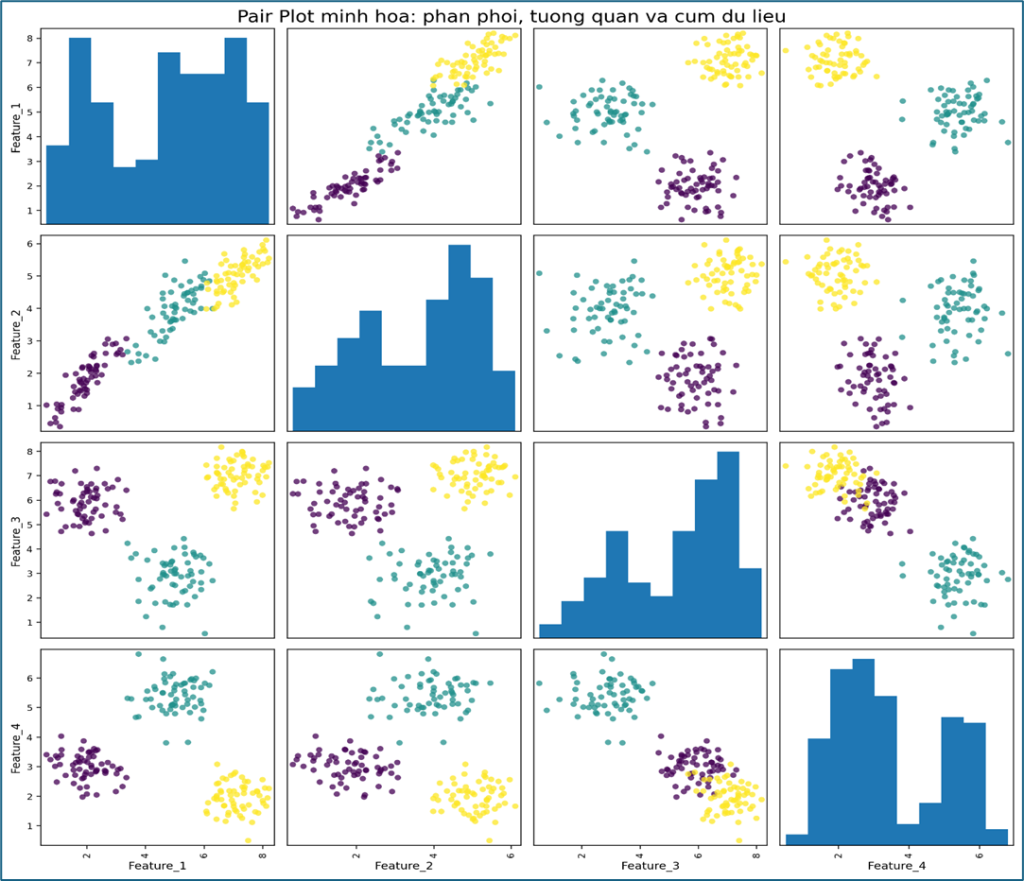
- Đường chéo cho thấy phân phối của từng biến
- Feature_1 và Feature_2 có xu hướng tuyến tính dương
- Nhiều cặp biến cho thấy dữ liệu tự tách thành các cụm
- Nhìn tổng thể, Pair Plot giúp quan sát phân phối, tương quan, cụm dữ liệu và khả năng tách lớp
Dendrogram – Phân cụm phân cấp
Dendrogram là biểu đồ thường dùng trong hierarchical clustering. Nó giúp ta quan sát mức độ gần nhau giữa các điểm dữ liệu hoặc các nhóm dữ liệu, từ đó hỗ trợ trả lời câu hỏi:
- dữ liệu có thể chia thành bao nhiêu cụm,
- các cụm được hình thành theo cấu trúc phân cấp như thế nào.
Ví dụ:
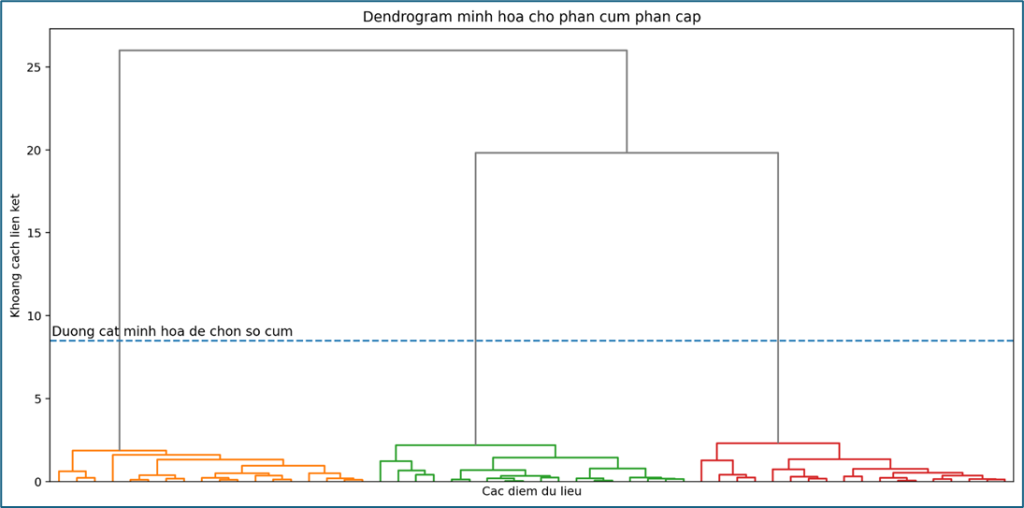
- Mỗi nhánh thể hiện quá trình gộp các điểm dữ liệu hoặc các nhóm dữ liệu
- Các nhánh gộp ở độ cao thấp nghĩa là chúng giống nhau hơn
- Khi kẻ một đường ngang để cắt cây, ta sẽ xác định được số cụm
- Trong hình này, nếu cắt ở mức đã đánh dấu, ta thu được 3 cụm chính
Word Cloud – NLP
Word Cloud thường được dùng trong các bài toán xử lý ngôn ngữ tự nhiên ở mức đơn giản. Trong biểu đồ này:
- từ xuất hiện càng nhiều thì kích thước càng lớn,
- bạn có thể nhanh chóng nhận ra những từ nổi bật trong tập văn bản.
Word Cloud hữu ích để tóm tắt sơ bộ nội dung văn bản, nhưng không đủ để thay thế các phương pháp phân tích ngôn ngữ chuyên sâu.
Ví dụ:

- Từ xuất hiện càng nhiều thì được hiển thị càng lớn
- Word Cloud giúp nhận ra những từ nổi bật trong tập văn bản
- Nó phù hợp để tóm tắt sơ bộ nội dung văn bản, nhưng không đủ để thay thế các phân tích NLP chuyên sâu
10. Trực quan hóa trong Machine Learning
Trong Machine Learning, trực quan hóa không chỉ cần thiết ở giai đoạn đầu của quá trình phân tích dữ liệu. Mà nó còn giữ vai trò rất quan trọng trong quá trình huấn luyện và đánh giá mô hình học máy. Một số ứng dụng tiêu biểu của trực quan hóa trong Machine Learning gồm:
- Feature Selection: hỗ trợ lựa chọn hoặc loại bỏ những biến không cần thiết, biến trùng lặp thông tin hoặc ít đóng góp cho mô hình.
- Model Evaluation: giúp phát hiện hiện tượng overfitting (học quá kỹ dữ liệu đến mức nhớ cả nhiễu và ngẫu nhiên) hoặc underfitting (học chưa đủ nên không nắm được quy luật dữ liệu) thông qua các biểu đồ như learning curve.
Vì trực quan hóa cho phép ta quan sát sự thay đổi của lỗi (loss/error) hoặc độ chính xác (accuracy) theo thời gian huấn luyện, từ đó nhìn ra vấn đề.
- Confusion Matrix: cho thấy mô hình đang dự đoán sai ở đâu, nhầm lẫn giữa những lớp nào, từ đó hiểu rõ hơn điểm mạnh và điểm yếu của mô hình.
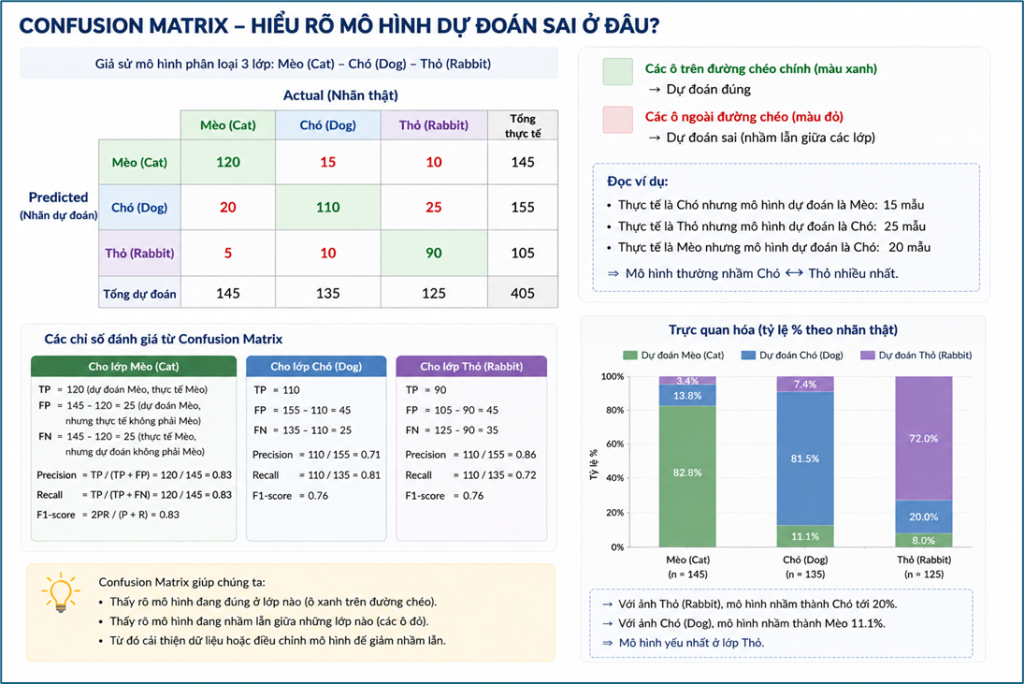
Nhờ trực quan hóa, các chỉ số đánh giá không còn chỉ là những con số khô khan, mà trở thành những thông tin trực quan và dễ diễn giải hơn. Điều này giúp người phân tích hiểu mô hình tốt hơn và đưa ra quyết định cải thiện phù hợp.
11. Công cụ trực quan hóa
Tùy vào mục đích sử dụng, chúng ta có thể lựa chọn những công cụ trực quan hóa khác nhau.
- BI Tools (Tableau, Power BI): phù hợp cho việc xây dựng báo cáo và dashboard, giao diện trực quan, dễ sử dụng, đặc biệt hữu ích khi cần trình bày kết quả cho nhà quản lý hoặc người dùng không chuyên về kỹ thuật.
- Python (Matplotlib, Seaborn): linh hoạt, mạnh mẽ, phù hợp cho phân tích dữ liệu, khám phá dữ liệu và tích hợp trực tiếp vào quy trình xử lý dữ liệu hoặc pipeline AI.
- Web (D3.js): phù hợp khi cần xây dựng các hệ thống trực quan hóa trên nền web với mức độ tùy biến cao, phục vụ cho các sản phẩm hoặc ứng dụng thực tế.
Không có công cụ nào là tốt nhất trong mọi trường hợp. Điều quan trọng là lựa chọn đúng công cụ phù hợp với mục tiêu, đối tượng người xem và bối cảnh sử dụng.
12. Kết luận
Trực quan hóa dữ liệu trong lập trình AI không chỉ là kỹ thuật vẽ biểu đồ mà còn là một phương pháp tư duy quan trọng giúp người học hiểu dữ liệu trước khi xây dựng mô hình. Nhờ trực quan hóa, chúng ta có thể phát hiện xu hướng, cụm dữ liệu, giá trị ngoại lai, dữ liệu bị thiếu và các mối quan hệ ẩn giữa các biến.
Trong AI và Machine Learning, trực quan hóa dữ liệu còn hỗ trợ lựa chọn đặc trưng, đánh giá mô hình, phát hiện overfitting, underfitting và diễn giải kết quả một cách rõ ràng hơn. Khi biết cách sử dụng các biểu đồ phù hợp như histogram, box plot, scatter plot, heatmap, line chart và confusion matrix, người học sẽ có nền tảng tốt hơn để phân tích dữ liệu và xây dựng mô hình AI hiệu quả.
Nói cách khác, hiểu đúng và vận dụng tốt trực quan hóa dữ liệu trong lập trình AI là một trong những nền tảng quan trọng để học tốt lập trình AI và ứng dụng AI vào thực tế.

