Kỹ thuật biểu tượng và pixel trong trực quan hóa là nhóm phương pháp giúp mở rộng khả năng quan sát dữ liệu khi biểu đồ truyền thống không còn đáp ứng tốt nhu cầu phân tích. Trong những bài toán thực tế, dữ liệu thường không chỉ nhiều bản ghi mà còn gồm nhiều thuộc tính cần xem đồng thời. Khi đó, việc chỉ dựa vào histogram, line chart hay scatter plot dễ khiến người phân tích bỏ lỡ cấu trúc quan trọng, khác biệt giữa các nhóm đối tượng hoặc những tín hiệu bất thường trong dữ liệu.
1. Các kỹ thuật biểu tượng và pixel trong trực quan hóa
Thay vì biểu diễn dữ liệu theo các biểu đồ quen thuộc, các kỹ thuật biểu tượng và pixel trong trực quan hóa giúp mở ra một hướng tiếp cận khác: chuyển dữ liệu thành hình dạng, bố cục và màu sắc để người xem có thể nhận ra đặc điểm tổng thể nhanh hơn. Đây cũng là nền tảng để tìm hiểu các kỹ thuật như Chernoff Faces, Star Glyphs, Pixel-based Visualization và Circle Segment.
Khi dữ liệu vượt quá khả năng nhận thức
Con người có khả năng nhận diện hình ảnh rất mạnh, nhưng lại có một giới hạn rõ ràng:
- Chúng ta khó xử lý dữ liệu có quá 3–4 thuộc tính cùng lúc
- Các bảng số liệu lớn nhanh chóng gây quá tải
- Những cấu trúc ẩn và outlier dễ bị “chìm” trong dữ liệu
Trong khi đó, dữ liệu hiện đại lại:
- Đa chiều (multi-dimensional): dữ liệu có nhiều thuộc tính khác nhau.
- Khối lượng lớn (big data): số lượng bản ghi dữ liệu rất lớn
Điều này tạo ra một khoảng cách giữa:
- Độ lớn của dữ liệu
- Khả năng nhận thức của con người
Ý tưởng cốt lõi: Tận dụng thị giác
Thay vì buộc người xem phải lần lượt đọc từng con số, trực quan hóa nâng cao khai thác thế mạnh tự nhiên của hệ thị giác: nhận ra hình dạng, độ tương phản, sự lặp lại và khác biệt chỉ trong thời gian rất ngắn. Nói cách khác, dữ liệu không chỉ được “vẽ ra” mà còn được “mã hóa” thành các tín hiệu thị giác để người xem có thể cảm nhận và so sánh nhanh hơn.
Từ ý tưởng đó, có hai hướng tiếp cận nổi bật.
Hướng thứ nhất là biểu tượng (iconic visualization), trong đó dữ liệu được ánh xạ vào các đặc điểm của một hình quen thuộc như khuôn mặt hay hình sao.
Hướng thứ hai là pixel-based visualization, trong đó mỗi giá trị hoặc mỗi quan sát được biểu diễn bằng một pixel và dùng màu sắc để thể hiện mức độ lớn nhỏ.
Một bên mạnh ở việc giúp người xem cảm nhận đặc trưng của từng đối tượng, bên còn lại phù hợp để quan sát pattern trên quy mô dữ liệu rất lớn. Chính nhờ tận dụng tốt thị giác, các kỹ thuật này giúp dữ liệu trở nên dễ đọc hơn theo cách mà bảng số liệu thô khó làm được.
Đây là bước chuyển từ: “Biểu đồ” → “ngôn ngữ hình ảnh”
2. Chernoff Faces – Khi dữ liệu có “cảm xúc”
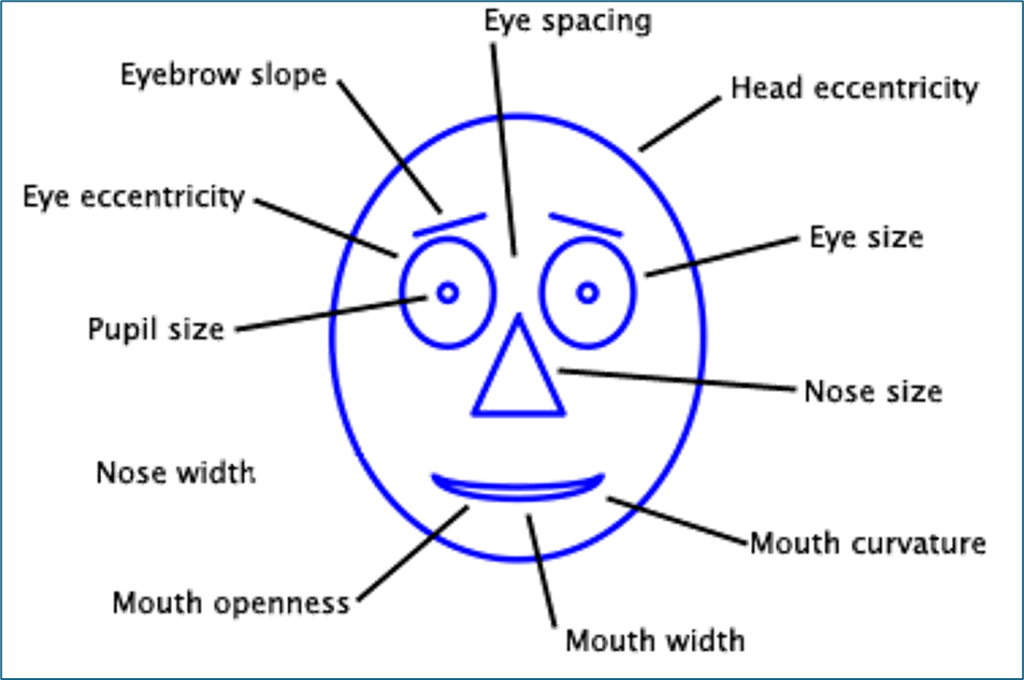
Kỹ thuật Chernoff Faces là một kỹ thuật biểu diễn rất thú vị vì tận dụng khả năng nhận diện khuôn mặt cực mạnh của con người. Chỉ cần thay đổi nhẹ ở mắt, miệng, lông mày hay hình dáng khuôn mặt, chúng ta đã có thể cảm nhận được sự khác biệt giữa các đối tượng. Dựa trên đặc điểm đó, Herman Chernoff đã đề xuất cách ánh xạ nhiều thuộc tính dữ liệu vào các bộ phận của khuôn mặt để biến mỗi bản ghi thành một “gương mặt dữ liệu” dễ quan sát và dễ ghi nhớ hơn.

Cách hoạt động
Nguyên tắc của Chernoff Faces là gán mỗi thuộc tính dữ liệu cho một đặc điểm trên khuôn mặt. Chẳng hạn, miệng thể hiện trạng thái tích cực hay tiêu cực thông qua độ cong. Mắt biểu diễn mức độ lớn nhỏ. Lông mày thể hiện xu hướng thay đổi. Hình dạng khuôn mặt biểu diễn mức độ rộng hoặc hẹp của đối tượng. Khi nhiều thuộc tính được ánh xạ cùng lúc, mỗi đối tượng sẽ hiện ra như một khuôn mặt mang đặc trưng riêng.
Ví dụ, trong bài toán doanh nghiệp:
- Lợi nhuận có thể biểu diễn bằng độ cong của miệng.
- Nợ có thể biểu diễn bằng kích thước mắt.
- Tăng trưởng có thể biểu diễn bằng độ rộng khuôn mặt.
Khi đó, thay vì đọc từng cột số liệu, người xem có thể quan sát hình dạng và nhanh chóng cảm nhận được trạng thái của từng doanh nghiệp.
Giá trị của Chernoff Faces
Điểm mạnh của Chernoff Faces nằm ở khả năng tạo cảm nhận trực quan rất nhanh. Người xem không cần đọc tuần tự từng giá trị mà vẫn có thể:
- nhận ra sự khác biệt giữa các đối tượng,
- so sánh nhanh các nhóm,
- phát hiện những trường hợp có xu hướng tích cực hoặc tiêu cực.
Nói cách khác, kỹ thuật này tận dụng bản năng sinh học của con người để hỗ trợ việc hiểu dữ liệu đa thuộc tính theo cách trực quan hơn.
Cách triển khai
Để xây dựng Chernoff Faces, thường thực hiện theo ba bước cơ bản:
- Chuẩn hóa dữ liệu về một khoảng giá trị phù hợp, chẳng hạn từ 0 đến 1.
- Ánh xạ từng thuộc tính vào các tham số hình học như độ cong, kích thước, độ nghiêng hoặc bán kính.
- Dùng các thành phần hình học cơ bản trong Python để vẽ khuôn mặt hoàn chỉnh.
Cách làm này giúp kiểm soát tốt hình dạng và đảm bảo mỗi dòng dữ liệu đều được thể hiện nhất quán.
Ví dụ 1: Theo dõi sức khỏe tài chính doanh nghiệp
Giả sử có 10 công ty cần theo dõi theo ba tiêu chí: lợi nhuận, nợ và tăng trưởng. Quy ước ánh xạ:
- Profit → độ cong miệng: lãi thì cười, lỗ thì mếu.
- Debt → kích thước mắt: nợ cao thì mắt to, nợ thấp thì mắt nhỏ.
- Growth → độ rộng khuôn mặt: tăng trưởng cao thì mặt rộng, thấp thì mặt hẹp.
Với cách ánh xạ này, mỗi công ty sẽ được biểu diễn bằng một khuôn mặt riêng. Khi đặt nhiều khuôn mặt cạnh nhau, người xem có thể nhận ra khá nhanh công ty nào đang có trạng thái tích cực, công ty nào trung tính và công ty nào tiềm ẩn rủi ro.
a. Tạo dữ liệu 10 công ty
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.patches import Circle, Arc
np.random.seed(2)
data = pd.DataFrame({
"Profit": np.random.uniform(-1, 1, 10), #có thể âm(lỗ) hoặc dương (lãi)
"Debt": np.random.rand(10), # 0 -> 1
"Growth": np.random.rand(10) # 0 -> 1
})
data.head()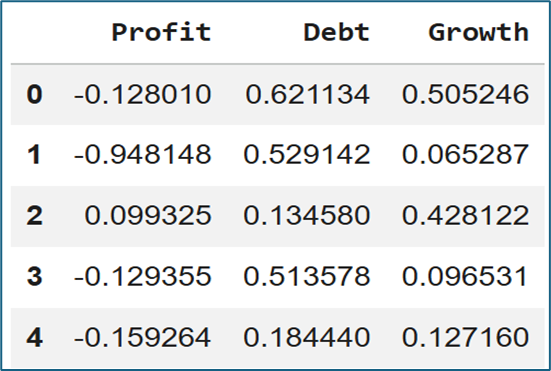
b. Hàm vẽ khuôn mặt
def draw_company_face(values, ax):
profit = values["Profit"]
debt = values["Debt"]
growth = values["Growth"]
# Mapping Growth -> độ rộng mặt
face_width = 1 + growth * 0.6
# Mapping Debt -> kích thước mắt
eye_size = 0.05 + debt * 0.15
# Mapping Profit -> độ cong miệng, profit từ -1 → 1, âm: mếu, dương: cười
mouth_height = 0.1 + profit * 0.4
# Vẽ
ax.set_aspect("equal")
# Mặt
face = Circle((0, 0), 1, fill=False)
ax.add_patch(face)
# scale theo growth (chiều ngang)
ax.set_xlim(-face_width, face_width)
ax.set_ylim(-1.2, 1.2)
# Mắt
ax.add_patch(Circle((-0.3, 0.3), eye_size, fill=True))
ax.add_patch(Circle((0.3, 0.3), eye_size, fill=True))
# Miệng
if profit >= 0:
mouth = Arc((0, -0.2), 1, mouth_height, theta1 = 200, theta2 = 340)
else:
# mếu thì lật ngược arc
mouth = Arc((0, -0.2), 1, abs(mouth_height), theta1 = 20, theta2 = 160)
ax.add_patch(mouth)
# Mũi (cho đẹp)
ax.plot([0, -0.05, 0.05, 0], [0.1, -0.05, -0.05, 0.1])
ax.axis("off")d. Vẽ 10 công ty
fig, axes = plt.subplots(2, 5, figsize=(12, 5))
for i, ax in enumerate(axes.flat):
draw_company_face(data.iloc[i], ax)
ax.set_title(f"Company {i+1}", fontsize=10)
plt.suptitle("Financial Health - Chernoff Faces", fontsize=16)
plt.tight_layout()
plt.show()Kết quả

Nhận xét
- 10 công ty → 10 khuôn mặt . Mỗi khuôn mặt thể hiện: Profit , Debt, Growth.
- Nhóm ổn / đáng đầu tư: Company 8 , Company 4 (tạm ổn). Đặc điểm: Miệng hơi cười → có lợi nhuận, Mắt không quá to → nợ vừa phải , Mặt không hẹp → có tăng trưởng. Đây là nhóm có thể đầu tư, nhưng vẫn cần theo dõi.
- Nhóm trung tính: Company 1, 3, 5, 10 . Đặc điểm: Miệng gần như phẳng , Mắt nhỏ → nợ thấp , Nhưng cũng không thấy tăng trưởng rõ . Nhóm này : không xấu, nhưng không hấp dẫn.
- Nhóm rủi ro: Company 2 , 6 , 7 , 9
Đặc điểm: Mắt rất to → nợ cao. Miệng không cười / hơi mếu → lợi nhuận kém. Đây là nhóm “đòn bẩy cao + hiệu quả thấp = nguy hiểm”
Ví dụ này cho thấy Chernoff Faces phù hợp khi cần nhìn nhanh trạng thái “tốt – xấu” của một tập đối tượng có nhiều thuộc tính.
Ví dụ 2: Phân tích khách hàng
Một công ty có 20 khách hàng cao cấp, mỗi khách có 5 chỉ số hành vi: Spending (Mức chi tiêu), Visits (Tần suất ghé), Loyalty (Điểm trung thành), Complaints (Số khiếu nại), Engagement (Tương tác marketing).
Quy ước ánh xạ:
- Spending (Mức chi tiêu) → độ cong miệng. Chi tiêu cao thì miệng cười hơn, thấp thì miệng phẳng hoặc hơi buồn.
- Visits (Tần suất ghé) → kích thước khuôn mặt. Ghé thường xuyên thì mặt lớn hơn.
- Loyalty (Điểm trung thành) → kích thước mắt. Trung thành cao thì mắt to hơn.
- Complaints (Số khiếu nại) → độ nghiêng lông mày. Khiếu nại cao thì lông mày cau xuống, nhìn “khó ở” hơn.
- Engagement (Tương tác marketing) → độ mở của miệng / độ rộng nụ cười. Tương tác cao thì miệng rộng hơn.
Nhờ vậy, mỗi khuôn mặt mang đồng thời đầy đủ thông tin về hành vi của một khách hàng.
a. Tạo dữ liệu
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.patches import Circle, Arc
# 1. Tạo dữ liệu mẫu
np.random.seed(1)
data_small = pd.DataFrame(
np.random.rand(20, 5),
columns=["Spending", "Visits", "Loyalty", "Complaints", "Engagement"]
)
data_small.head()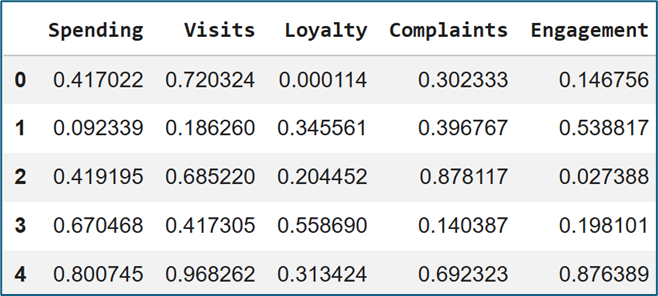
b. Hàm vẽ 1 khuôn mặt
def draw_face(values, ax):
"""
values là 1 dòng dữ liệu gồm 5 thuộc tính:
Spending, Visits, Loyalty, Complaints, Engagement
"""
# Lấy từng thuộc tính ra cho dễ đọc
spending = values["Spending"]
visits = values["Visits"]
loyalty = values["Loyalty"]
complaints = values["Complaints"]
engagement = values["Engagement"]
# 1) Visits -> kích thước khuôn mặt, visits cao => mặt lớn hơn
face_radius = 0.85 + visits * 0.25
# 2) Loyalty -> kích thước mắt , loyalty cao => mắt to hơn
eye_radius = 0.05 + loyalty * 0.12
# 3) Complaints -> độ nghiêng lông mày, thấp=> mày hơi nâng, cao => mày cau xuống
brow_tilt = -0.25 + complaints * 0.5
# 4) Spending -> độ cong miệng, thấp=>miệng ít cười, cao => cười rõ hơn
mouth_height = 0.15 + spending * 0.35
# 5) Engagement -> độ rộng miệng, cao => miệng rộng hơn
mouth_width = 0.5 + engagement * 0.5
# VẼ KHUÔN MẶT
ax.set_aspect("equal")
# Viền mặt
face = Circle((0, 0), face_radius, fill=False, linewidth=1.5)
ax.add_patch(face)
# Mắt trái, mắt phải
left_eye = Circle((-0.3, 0.25), eye_radius, fill=True)
right_eye = Circle((0.3, 0.25), eye_radius, fill=True)
ax.add_patch(left_eye)
ax.add_patch(right_eye)
# Lông mày, complaints cao=> lông mày dốc xuống phía trong, tạo cảm giác cau có
ax.plot(
[-0.45, -0.15],
[0.48 + brow_tilt, 0.42 - brow_tilt],
linewidth=2
)
ax.plot(
[0.15, 0.45],
[0.42 - brow_tilt, 0.48 + brow_tilt],
linewidth=2
)
# Miệng , spending điều khiển độ cong, engagement điều khiển độ rộng
mouth = Arc(
(0, -0.2),
mouth_width, mouth_height,
theta1 = 200, theta2 = 340,
linewidth=2
)
ax.add_patch(mouth)
# Mũi vẽ cố định cho dễ nhìn
ax.plot([0, -0.05, 0.05, 0], [0.1, -0.05, -0.05, 0.1], linewidth=1)
# Tắt trục
ax.set_xlim(-1.4, 1.4)
ax.set_ylim(-1.4, 1.4)
ax.axis("off")c. Vẽ 20 khuôn mặt
fig, axes = plt.subplots(4, 5, figsize=(12, 9))
for i, ax in enumerate(axes.flat):
draw_face(data_small.iloc[i], ax)
ax.set_title(f"KH {i+1}", fontsize=10)
plt.suptitle("Chernoff Faces - Full Mapping 5 Variables", fontsize=16)
plt.tight_layout()
plt.show()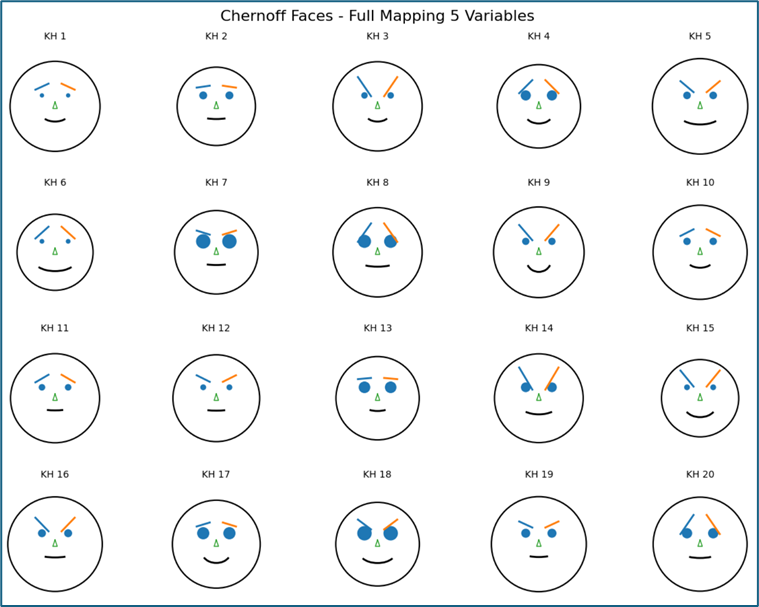
d. Nhận xét
- Mỗi khuôn mặt mang đầy đủ thông tin khách hàng. Có thể bắt đầu so sánh & phân loại bằng mắt
- Mặt to → Visits cao (ghé nhiều)
- Mắt to → Loyalty cao (trung thành)
- Lông mày cau → Complaints cao (hay phàn nàn)
- Miệng cong nhiều → Spending cao (chi nhiều)
- Miệng rộng → Engagement cao (tương tác tốt)
- Nhóm khách tốt: KH 7, KH 8, KH 18 . Đặc điểm: Mắt to → trung thành cao , Miệng cười rõ → chi tiêu tốt , Lông mày không cau → ít khiếu nại . Đây là nhóm giữ chân + upsell
- Nhóm “trung bình”: KH 1, KH 10, KH 12 . Đặc điểm: Mọi thứ đều vừa phải , Không nổi bật . Nhóm này cần kích thích thêm engagement
- Nhóm “có vấn đề”: KH 3, KH 16, KH 20 . Đặc điểm: Lông mày dốc mạnh → complaints cao. Dù có thể chi tiêu nhưng “khó chịu”. Nhóm này: cần chăm sóc riêng hoặc xem lại trải nghiệm dịch vụ
Từ biểu đồ có thể nhận diện sơ bộ các nhóm khách hàng như nhóm trung thành cao, nhóm có nhiều khiếu nại hoặc nhóm trung bình.
Tuy nhiên, phương pháp này mang tính trực quan, phụ thuộc vào cảm nhận và không phù hợp để đưa ra kết luận định lượng chính xác.
Hạn chế của Chernoff Faces
Dù trực quan và thú vị, Chernoff Faces vẫn có những giới hạn rõ ràng.
- Kỹ thuật này khó hỗ trợ so sánh chính xác giữa nhiều đối tượng nếu số lượng khuôn mặt quá lớn.
- Việc diễn giải phụ thuộc khá nhiều vào cảm nhận của người xem.
- Biểu đồ không cho biết giá trị số cụ thể, nên khó dùng để kết luận định lượng.
- Cuối cùng, đây không phải công cụ thay thế cho các phương pháp phân tích như clustering hay PCA.
Vì vậy, Chernoff Faces phù hợp như một công cụ trực quan hỗ trợ khám phá ban đầu, chứ không nên là căn cứ duy nhất để phân nhóm hay ra quyết định.
Lưu ý khi ánh xạ dữ liệu vào khuôn mặt
Khi thiết kế Chernoff Faces, cần chú ý rằng con người nhạy hơn với một số bộ phận trên khuôn mặt, đặc biệt là mắt và miệng. Vì thế:
- Thuộc tính quan trọng nên được gán vào mắt hoặc miệng.
- Thuộc tính phụ có thể gán vào mũi, tai hoặc lông mày.
Ví dụ:
- Profit → miệng, vì lãi gợi cảm giác “cười”.
- Debt → mắt, vì mức nợ cao dễ được diễn đạt bằng mắt mở to.
- Complaints → lông mày, vì khiếu nại nhiều tạo cảm giác cau có.
Cách ánh xạ hợp lý sẽ giúp khuôn mặt truyền tải thông tin rõ ràng hơn và giảm nguy cơ người xem hiểu sai.
3. Star Glyphs – “Dấu vân tay” của dữ liệu
Trong nhóm kỹ thuật biểu tượng và pixel trong trực quan hóa, Star Glyphs là kỹ thuật phù hợp khi cần so sánh cấu trúc của nhiều thuộc tính trên cùng một đối tượng. Nếu Chernoff Faces thiên về cảm nhận trực giác qua hình ảnh quen thuộc, thì Star Glyphs nhấn mạnh vào hình dạng hình học. Mỗi đối tượng được biểu diễn như một đa giác tạo thành từ nhiều trục tỏa ra từ tâm, nhờ đó người xem có thể nhận ra nhanh sự cân bằng, lệch pha hay nổi trội của từng thuộc tính.
Ý tưởng của Star Glyphs
Nguyên tắc hoạt động của Star Glyphs khá đơn giản. Mỗi thuộc tính được gán vào một trục xuất phát từ tâm, còn giá trị được thể hiện bằng khoảng cách từ tâm ra ngoài. Khi nối các điểm trên các trục lại với nhau, ta thu được một hình đa giác đại diện cho đối tượng.
Điểm đáng chú ý là chính hình dạng của đa giác này mang ý nghĩa phân tích. Một hình nở đều cho thấy các thuộc tính khá cân bằng. Một hình nhô mạnh về một hướng cho thấy đối tượng nổi bật ở một vài đặc điểm cụ thể. Ngược lại, hình bị méo hoặc khuyết ở một phía thường phản ánh sự thiếu hụt hay mất cân đối trong cấu trúc dữ liệu.
Vì vậy, Star Glyphs thường được xem như “dấu vân tay” của dữ liệu: chỉ cần nhìn nhẹ hình dạng, người xem đã có thể hình dung sơ bộ đặc điểm của đối tượng mà không cần đọc riêng từng giá trị.
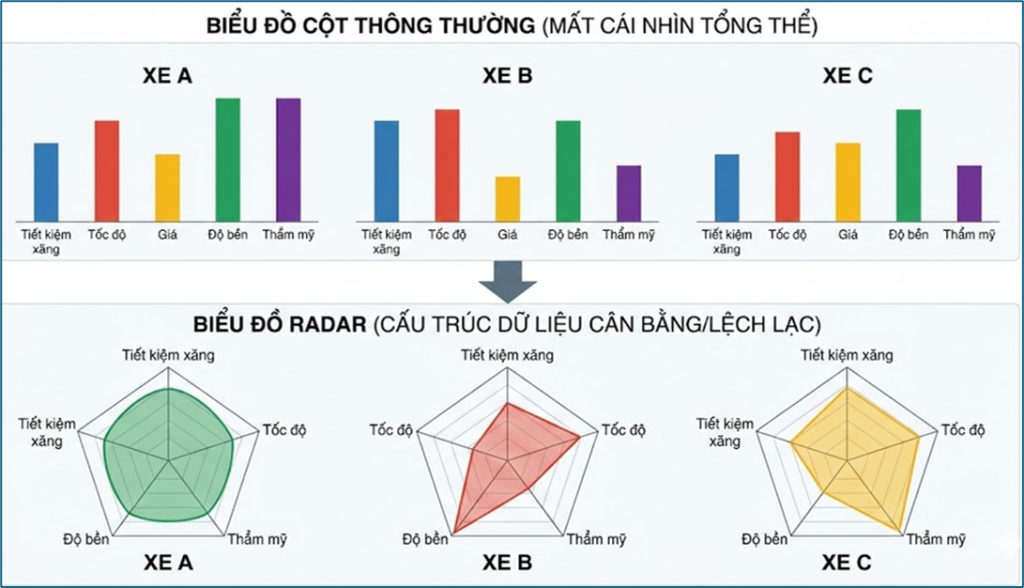
Ví dụ 1: So sánh đặc điểm các xe
Giả sử cần so sánh ba mẫu xe theo năm tiêu chí: tiết kiệm xăng, tốc độ, giá, độ bền và thẩm mỹ. Nếu dùng biểu đồ cột thông thường, người xem có thể đọc được từng tiêu chí riêng lẻ, nhưng rất khó nhìn ra ngay cấu trúc tổng quát của từng xe. Trong trường hợp này, radar chart giúp thể hiện rõ hơn hình dáng đặc trưng của mỗi đối tượng.
Mỗi xe được biểu diễn trên cùng một hệ trục tỏa ra từ tâm, với thang đo từ 0 đến 10. Khi các điểm dữ liệu được nối lại, hình đa giác tạo thành cho phép người xem đánh giá mức độ cân bằng hoặc lệch mạnh giữa các thuộc tính.
Tạo dữ liệu cho 3 xe
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
data_cars = pd.DataFrame({
"Tiết kiệm xăng": [7, 8, 6],
"Tốc độ": [8, 9, 7],
"Giá": [6, 4, 7],
"Độ bền": [9, 8, 9],
"Thẩm mỹ": [9, 5, 5]
}, index=["Xe A", "Xe B", "Xe C"])
print(data_cars)
Vẽ radar chart cho các xe
Radar chart là cách biểu diễn dữ liệu theo dạng các trục tỏa ra từ tâm.
# Chuẩn bị góc cho radar chart
categories = list(data_cars.columns)
N = len(categories)
angles = np.linspace(0, 2 * np.pi, N, endpoint=False).tolist()
angles += angles[:1] # lặp lại góc đầu để khép kín hình
# Vẽ radar chart cho từng xe
fig, axes = plt.subplots(1, 3, figsize=(15, 5), subplot_kw=dict(polar=True))
colors = ["green", "red", "gold"]
for ax, (car_name, row), color in zip(axes, data_cars.iterrows(), colors):
values = row.tolist()
values += values[:1] # lặp lại giá trị đầu để khép kín hình
ax.plot(angles, values, linewidth=2, color=color)
ax.fill(angles, values, alpha=0.25, color=color)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(categories, fontsize=10)
ax.set_yticks([2, 4, 6, 8, 10])
ax.set_ylim(0, 10)
ax.set_title(car_name, size=14, fontweight="bold", pad=20)
plt.suptitle("Biểu đồ Radar so sánh đặc điểm 3 xe", fontsize=16, fontweight="bold")
plt.tight_layout()
plt.show()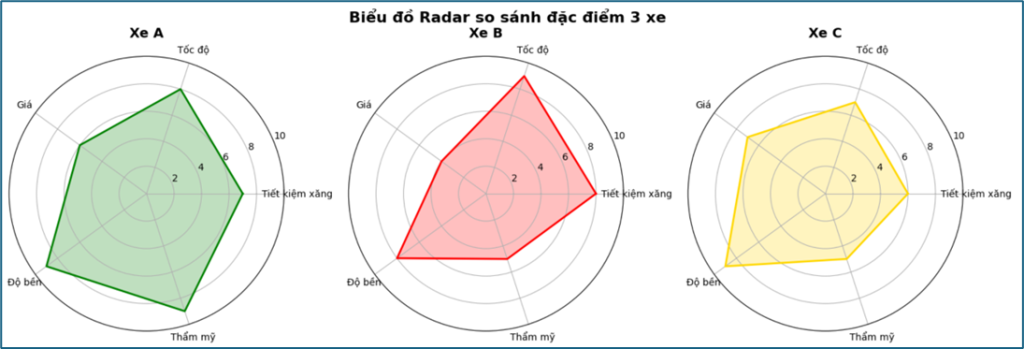
Nhận xét
- 3 radar riêng → rất dễ so sánh cấu trúc
- Thang đo 0–10 → trực quan, dễ đọc
- XE A – Cân bằng & mạnh toàn diện: Tiết kiệm xăng: ~7 , Tốc độ: ~8 , Giá: ~6 , Độ bền: ~9 , Thẩm mỹ: ~9. Hình Xe A gần đều . Không có điểm yếu lớn → Nhận định: Xe A vừa bền, vừa đẹp, vừa nhanh.
- XE B – Lệch mạnh: Tốc độ: ~9 rất cao, Độ bền: ~8, Giá: ~4 thấp, Thẩm mỹ: ~5 thấp. Hình xe B: Nhọn về phía tốc độ . Bị “khuyết” ở giá & thẩm mỹ → Nhận định:Xe B thiên về hiệu năng, hy sinh trải nghiệm/ngoại hình.
- XE C – Cân bằng , trung bình: Tiết kiệm xăng: ~6 , Tốc độ: ~7, Giá: ~7, Độ bền: ~9 , Thẩm mỹ: ~5 . Hình xe C khá đều nhưng không “nở to” như A . Nhận định: Xe C ổn định, nhưng không có điểm vượt trội rõ.
Điều radar chart làm được mà bar chart không làm được
Radar chart cho phép quan sát đồng thời nhiều thuộc tính dưới dạng cấu trúc hình học, giúp dễ dàng nhận diện sự cân bằng hoặc lệch lạc của từng đối tượng.
Ví dụ 2: So sánh sinh viên
Xét một tập dữ liệu gồm 200 sinh viên, mỗi người có 6 kỹ năng: Math, Programming, English, Soft Skills, Research và Teamwork. Với loại dữ liệu này, Star Glyphs đặc biệt hữu ích vì nó cho phép quan sát xu hướng phát triển kỹ năng theo dạng hình học.
Nếu một sinh viên có các kỹ năng phân bố tương đối đồng đều, hình đa giác sẽ nở khá đều quanh tâm. Nếu chỉ mạnh ở một vài trục, hình sẽ bị kéo về một hướng nhất định. Từ đó, người xem có thể nhận ra ai là người toàn diện, ai thiên về lý thuyết, ai mạnh thực hành, và ai chưa có điểm mạnh rõ ràng.
Tạo dữ liệu
np.random.seed(2)
data_medium = pd.DataFrame(
np.random.rand(200, 6),
columns=["Math", "Programming", "English", "SoftSkills", "Research", "Teamwork"]
)
data_medium.head()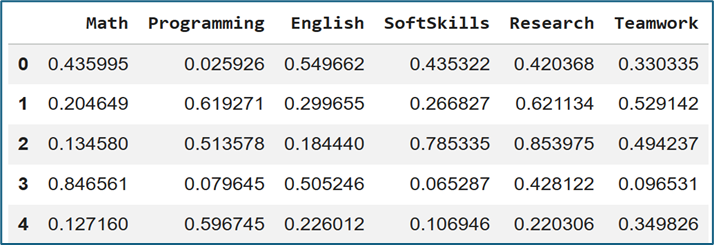
Vẽ hình
import matplotlib.pyplot as plt
import numpy as np
sample = data_medium.iloc[:5] # vẽ 5 sinh viên
#sample = data_medium # vẽ toàn bộ 200 sinh viên
categories = list(sample.columns)
angles = np.linspace(0, 2*np.pi, len(categories), endpoint=False)
angles = np.concatenate((angles, [angles[0]]))
plt.figure(figsize=(6,6))
for i in range(len(sample)):
values = sample.iloc[i].values
values = np.concatenate((values, [values[0]]))
plt.polar(angles, values, alpha=0.3)
plt.xticks(angles[:-1], categories)
plt.title("Star Glyph – Skill Comparison (5 students)")
plt.show()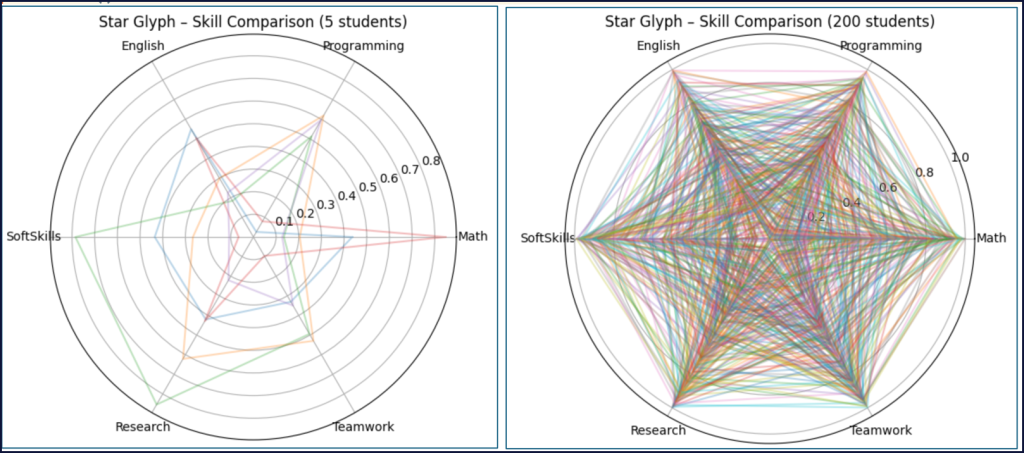
Nhận xét từ biểu đồ
- Mỗi màu = 1 sinh viên . 6 trục = 6 kỹ năng . Hình càng “nở đều” → càng toàn diện . Hình “lệch” → có xu hướng chuyên sâu
- Quan sát nhanh: Không có sinh viên nào thực sự toàn diện
- Sinh viên chuyên Toán (Math cao) Đường màu đỏ (Math ~0.85) Math rất cao. Các kỹ năng khác thấp (Programming, SoftSkills rất thấp) è Nhận xét: “Giỏi chuyên môn cứng nhưng thiếu kỹ năng hỗ trợ”
- Sinh viên cân bằng tương đối: Đường màu xanh dương (SV 1). Các kỹ năng khá đều (~0.3–0.5) . Không có điểm quá cao. Nhận xét: “Ổn định, dễ thích nghi nhưng chưa nổi bật”
- Sinh viên nghiên cứu mạnh: Đường màu xanh lá (SV 3). Research rất cao (~0.85) . SoftSkills cũng cao (~0.78) Nhưng Math, English thấp è Nhận xét: “Thiên về nghiên cứu, không phải kiểu developer thuần”
- Sinh viên lập trình tốt: Đường màu cam (SV 2 & 5 gần giống)Programming cao (~0.6) .Research, Teamwork khá. Nhưng Math không cao. è Nhận xét: “Thực hành tốt, phù hợp làm dev hơn là lý thuyết”
- Sinh viên yếu đồng đều: Đường tím, tất cả kỹ năng thấp (~0.1–0.3) . Nhận xét: “Chưa có điểm mạnh rõ ràng”
=>
- Các sinh viên có xu hướng phát triển lệch về một số kỹ năng nhất định hơn là phát triển đồng đều, thể hiện qua các hình đa giác bị lệch thay vì cân đối.
- Không có sinh viên nào đạt mức cao đồng thời ở tất cả các kỹ năng, cho thấy sự đánh đổi giữa các nhóm kỹ năng.
Giá trị của Star Glyphs
Điểm mạnh lớn nhất của Star Glyphs là khả năng chuyển nhiều thuộc tính thành một hình dạng dễ so sánh. Người xem không chỉ thấy từng thuộc tính riêng lẻ mà còn nhìn được mối quan hệ giữa các thuộc tính trong cùng một đối tượng.
Kỹ thuật này đặc biệt hữu ích trong các tình huống như:
- so sánh năng lực giữa các cá nhân,
- đối chiếu đặc điểm giữa các sản phẩm,
- nhận diện mức độ cân bằng trong hồ sơ dữ liệu đa thuộc tính.
Thay vì hỏi từng thuộc tính cao hay thấp, Star Glyphs giúp trả lời một câu hỏi lớn hơn: đối tượng này có “cấu hình” như thế nào.
Lưu ý và giới hạn của Star Glyphs
Dù trực quan, Star Glyphs vẫn có một số hạn chế cần chú ý.
Trước hết, thứ tự các trục ảnh hưởng trực tiếp đến hình dạng. Nếu các thuộc tính được sắp xếp không hợp lý, hình đa giác có thể bị méo theo cách gây hiểu nhầm. Vì vậy, các thuộc tính liên quan nên được đặt gần nhau để hình dạng phản ánh đúng hơn cấu trúc dữ liệu.
Ngoài ra, kỹ thuật này chỉ phù hợp khi số đối tượng không quá nhiều. Nếu chồng quá nhiều đa giác trên cùng một biểu đồ, hình sẽ trở nên rối và rất khó đọc. Trong trường hợp đó, biểu đồ mất đi ưu thế trực quan ban đầu và thậm chí còn gây nhiễu hơn các cách biểu diễn khác.
Nói cách khác, Star Glyphs mạnh ở khả năng so sánh cấu hình của một số ít đối tượng, nhưng không phải lựa chọn tối ưu khi số lượng quan sát quá lớn.
Star Glyphs cho phép người xem nhìn dữ liệu theo dạng hình học thay vì chỉ đọc từng con số. Mỗi đa giác giống như một “dấu vân tay”, phản ánh cấu trúc riêng của đối tượng thông qua mức độ cân bằng, lệch hay nổi trội giữa các thuộc tính. Đây là một kỹ thuật rất phù hợp khi cần so sánh hồ sơ đa thuộc tính của số lượng đối tượng vừa phải và muốn nhanh chóng nhận ra những khác biệt.
3. Pixel-based Visualization – Khi dữ liệu quá lớn
Pixel-based Visualization là hướng tiếp cận đặc biệt phù hợp với các tập dữ liệu có quy mô lớn. Khi số lượng điểm dữ liệu tăng lên quá nhiều, những biểu đồ quen thuộc như scatter plot hay line chart thường gặp vấn đề chồng lấp điểm, khiến hình trở nên rối và khó đọc. Lúc này, thay vì tiếp tục biểu diễn mỗi quan sát bằng một dấu tròn hay một đoạn đường, kỹ thuật pixel-based thu nhỏ mỗi giá trị xuống chỉ còn một pixel. Cách làm này giúp tận dụng tối đa diện tích màn hình và cho phép hiển thị một lượng dữ liệu rất lớn trong cùng một không gian trực quan.
Ý tưởng của Pixel-based Visualization
Nguyên tắc cốt lõi của kỹ thuật này là chuyển dữ liệu thành một ma trận hình ảnh, trong đó mỗi điểm dữ liệu được biểu diễn bằng một pixel. Giá trị của dữ liệu được mã hóa bằng màu sắc. Thông thường, màu đậm biểu thị giá trị cao, còn màu nhạt biểu thị giá trị thấp.
Điểm mạnh của cách biểu diễn này nằm ở chỗ mắt người rất nhạy với sự thay đổi màu sắc và các vùng màu lặp lại. Nhờ đó, người xem có thể nhanh chóng nhận ra các pattern, các chu kỳ lặp, vùng dữ liệu bất thường hoặc những điểm khác biệt nổi bật mà nếu nhìn bằng bảng số liệu hoặc line chart sẽ rất khó phát hiện.
Ví dụ: Tìm giai đoạn doanh thu bất thường
Giả sử một công ty thương mại điện tử có dữ liệu doanh thu theo ngày trong 3 năm liên tiếp, từ năm 2024 đến 2026. Mỗi bản ghi gồm hai trường cơ bản là ngày và doanh thu. Nếu biểu diễn toàn bộ chuỗi dữ liệu này bằng biểu đồ đường, số lượng điểm đủ lớn để khiến người xem khó nhận ra cấu trúc tổng thể, nhất là khi mục tiêu không phải là đọc từng ngày riêng lẻ mà là phát hiện xu hướng dài hạn và các giai đoạn bất thường.
Để xử lý bài toán này, dữ liệu được tổ chức lại theo dạng ma trận:
- Hàng đại diện cho từng năm,
- Cột đại diện cho ngày trong năm,
- Màu sắc biểu diễn mức doanh thu.
Khi đó, toàn bộ dữ liệu được nén thành một heatmap, nơi người xem có thể quan sát đồng thời cả ba năm chỉ trong một hình duy nhất.
Phát sinh dữ liệu
import numpy as np
import pandas as pd
np.random.seed(42)
# 1. Tạo 3 năm dữ liệu (2024–2026)
dates = pd.date_range(start="2024-01-01", end="2026-12-31", freq="D")
data_list = []
for date in dates:
year = date.year
day_of_year = date.timetuple().tm_yday
# Base revenue
base = 100
# Seasonality (chu kỳ năm)
seasonal = 30 * np.sin(2 * np.pi * day_of_year / 365)
# Noise
noise = np.random.normal(0, 10)
# Event bất thường (sale lớn)
spike = 0
if 330 <= day_of_year <= 350: # Black Friday / Noel
spike = 100
if 180 <= day_of_year <= 190: # mid-year sale
spike += 50
# Revenue cuối
revenue = base + seasonal + noise + spike
data_list.append([date, revenue])
# Tạo DataFrame
data_large = pd.DataFrame(data_list, columns=["Date", "Revenue"])
data_large.head()
Áp dụng code Pixel-based (heatmap)
import seaborn as sns
import matplotlib.pyplot as plt
data_large["Year"] = data_large["Date"].dt.year
data_large["DayOfYear"] = data_large["Date"].dt.dayofyear
pivot = data_large.pivot(index="Year", columns="DayOfYear", values="Revenue")
plt.figure(figsize=(14, 4))
sns.heatmap(pivot, cmap="coolwarm")
plt.title("Pixel Visualization - Revenue by Day (3 Years)")
plt.xlabel("Day of Year")
plt.ylabel("Year")
plt.show()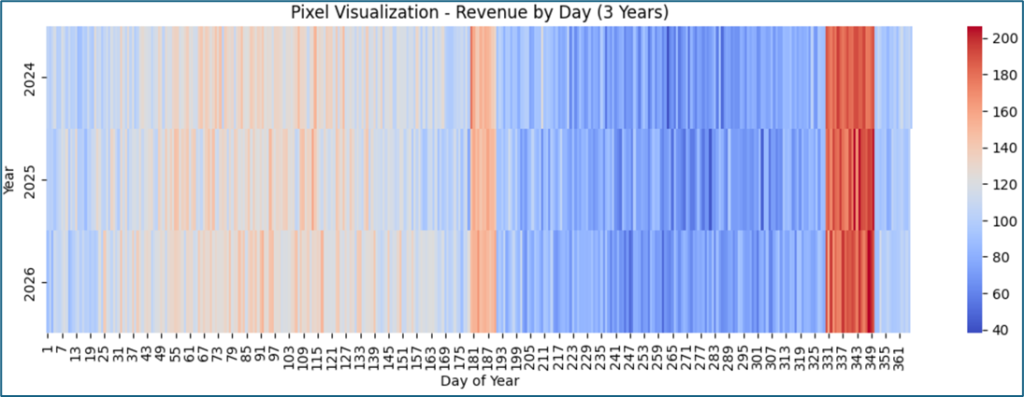
- Có ba hàng dữ liệu = 3 năm (2024–2026)
- Trục X = ngày trong năm (1 → 365)
- Màu: 🔵 Xanh → doanh thu thấp, 🔴 Đỏ → doanh thu cao
Nhìn chung, có pattern lặp lại rất rõ theo năm.
Nhận xét
Peak lớn cuối năm: khoảng day 330–350, cả 3 năm đều đỏ đậm. Đây là giai đoạn doanh thu tăng đột biến → Black Friday / Noel. Đồng thời là các đỉnh doanh thu lặp lại theo mùa vụ (seasonal peaks)
Peak giữa năm (nhỏ hơn): Khoảng day ~180–190. Màu đỏ nhạt hơn nhưng vẫn rõ. → Nhận định: đợt khuyến mãi giữa năm
Seasonality (mùa vụ): Ta thấy Đầu năm: trung bình, Giữa năm: tăng nhẹ . Sau đó giảm (xanh nhiều). Cuối năm → bùng nổ . Và pattern này: Lặp lại ở cả 3 năm. Nhận định: Doanh thu có tính chu kỳ theo năm, với đỉnh vào giữa và cuối năm.
Giai đoạn thấp: Khoảng day ~200–300. Màu xanh chiếm ưu thế. Nhận định: Đây là giai đoạn “low season”
Các giai đoạn doanh thu cao không xuất hiện ngẫu nhiên mà lặp lại theo chu kỳ, cho thấy ảnh hưởng của các chiến dịch marketing định kỳ hoặc hành vi mua sắm theo mùa.
Vì sao heatmap “ăn đứt” line chart?
Nếu dùng line chart để vẽ hơn một nghìn điểm dữ liệu liên tiếp, biểu đồ sẽ nhanh chóng trở nên dày đặc và khó đọc. Người xem có thể thấy doanh thu lên xuống, nhưng lại khó nhận ra đâu là pattern lặp lại theo năm, đâu là giai đoạn cao điểm mang tính chu kỳ, và đâu là mùa thấp điểm kéo dài.
Heatmap khắc phục điều đó bằng cách nén dữ liệu thành một ma trận màu. Khi dữ liệu được tổ chức theo hàng và cột hợp lý, pattern vốn ẩn trong chuỗi thời gian sẽ hiện ra rõ hơn rất nhiều. Đây chính là ưu thế quan trọng nhất của pixel-based visualization: không tập trung vào từng điểm riêng lẻ, mà giúp người xem nhìn ra cấu trúc tổng thể của dữ liệu lớn.
Pixel-based Visualization là lựa chọn rất mạnh khi dữ liệu quá dày đặc để biểu diễn hiệu quả bằng các biểu đồ thông thường. Bằng cách thu mỗi quan sát về một pixel và dùng màu sắc để mã hóa giá trị, kỹ thuật này giúp người xem phát hiện nhanh các vùng bất thường, chu kỳ lặp và xu hướng dài hạn. Trong các bài toán dữ liệu lớn, đặc biệt là dữ liệu theo thời gian, đây là một cách biểu diễn ngắn gọn nhưng rất giàu khả năng gợi mở nhận định.
4. Circle Segment – Trực quan hóa chu kỳ
Trong nhóm kỹ thuật biểu tượng và pixel trong trực quan hóa, Circle Segment là cách biểu diễn phù hợp với những dữ liệu có tính lặp theo chu kỳ. Thay vì trải dữ liệu trên trục thẳng như thông thường, kỹ thuật này sắp xếp các giá trị quanh một vòng tròn để người xem dễ nhận ra nhịp điệu lặp lại theo thời gian. Trong ví dụ dưới đây, Circle Segment được triển khai dưới dạng polar bar chart, trong đó mỗi giờ tương ứng với một đoạn trên vòng tròn và độ dài của đoạn thể hiện mức giá trị trung bình ở thời điểm đó.
Ý tưởng của Circle Segment
Điểm cốt lõi của Circle Segment là dùng hình tròn để biểu diễn những dữ liệu thời gian mang tính chu kỳ, chẳng hạn như giờ trong ngày, ngày trong tuần hoặc tháng trong năm. Khác với trục thời gian dạng thẳng, vòng tròn phản ánh đúng bản chất lặp lại của dữ liệu: sau thời điểm cuối cùng, chu kỳ lại quay về điểm bắt đầu.
Nhờ vậy, người xem không chỉ thấy dữ liệu tăng hay giảm, mà còn cảm nhận được nhịp điệu lặp lại của nó. Những giai đoạn cao điểm, thấp điểm hay sự chuyển tiếp giữa các khoảng thời gian trở nên rõ ràng hơn khi được đặt trên một vòng tròn hoàn chỉnh.
Vì sao dùng hình tròn?
Hình tròn đặc biệt phù hợp khi dữ liệu có tính tuần hoàn. Với các thuộc tính như 24 giờ trong ngày, 7 ngày trong tuần hay 12 tháng trong năm, điểm kết thúc không thực sự là điểm cuối, mà nối tiếp tự nhiên với điểm bắt đầu. Nếu biểu diễn các giá trị này trên trục thẳng, người xem có thể bỏ lỡ cảm giác liên tục của chu kỳ. Nhưng khi đặt chúng quanh một vòng tròn, mối liên hệ giữa các thời điểm trở nên trực quan hơn rất nhiều.
Trong ví dụ này, dữ liệu không hiển thị từng ngày riêng lẻ mà được gom lại theo giờ trong ngày, sau đó tính mức tiêu thụ trung bình cho từng giờ. Kết quả là một biểu đồ tròn gồm 24 đoạn, cho phép quan sát nhanh thời điểm nào tiêu thụ điện cao nhất và thời điểm nào thấp nhất.
Bài toán: Phát hiện chu kỳ theo giờ trong ngày
Giả sử có một hệ thống cảm biến IoT ghi nhận mức tiêu thụ điện theo từng giờ trong suốt 2 năm. Với quy mô khoảng 17520 bản ghi, mục tiêu không còn là đọc từng thời điểm cụ thể mà là tìm ra quy luật lặp lại theo giờ: khi nào hệ thống thường tiêu thụ mạnh, khi nào tiêu thụ thấp, và chu kỳ đó có ổn định hay không.
Để minh họa, dữ liệu được tạo ra với một mô hình dao động theo dạng sin trong chu kỳ 24 giờ. Điều này có nghĩa là mức tiêu thụ được “cài” sẵn một nhịp điệu tăng giảm theo ngày, sau đó được thêm nhiễu ngẫu nhiên để dữ liệu gần với thực tế hơn. Cách tạo dữ liệu như vậy giúp làm nổi bật khả năng của kỹ thuật trực quan hóa trong việc phát hiện pattern mà dữ liệu ngẫu nhiên đơn thuần khó thể hiện.
Tạo dữ liệu
np.random.seed(123)
hours = 24 * 365 * 2
dates = pd.date_range(start="2025-01-01", periods=hours, freq="h") #Tạo thời gian theo giờ
# Chu kỳ tiêu thụ điện theo giờ
hour_pattern = 5 + 3*np.sin(2*np.pi*dates.hour/24)
# Thêm nhiễu để dữ liệu giống thực tế hơn.
usage = hour_pattern + np.random.normal(0, 0.5, hours)
data_very_large = pd.DataFrame({"Datetime": dates, "Usage": usage})
data_very_large.head()
hour_pattern phát sinh bằng hàm là ta đang cố tình cài vào dữ liệu một quy luật: 24 giờ → 1 vòng tròn sin → dao động lên xuống . Kết quả là có giờ cao điểm , có giờ thấp điểm, có pattern lặp lại.
Việc tạo dữ liệu có chu kỳ giúp minh họa rõ ràng khả năng của kỹ thuật visualization trong việc phát hiện pattern, điều mà dữ liệu ngẫu nhiên không thể hiện được.
Cách xử lý và vẽ biểu đồ
Sau khi có dữ liệu theo từng giờ, bước tiếp theo là trích xuất Hour từ cột thời gian và tính mức tiêu thụ điện trung bình cho mỗi giờ trong ngày. Kết quả thu được là một chuỗi gồm 24 giá trị, tương ứng với 24 mốc thời gian từ 0 đến 23 giờ.
Các giá trị này sau đó được đặt lên hệ trục cực bằng polar bar chart. Trong dạng biểu diễn này:
- góc trên vòng tròn xác định giờ trong ngày,
- chiều dài cột biểu diễn mức tiêu thụ trung bình,
- toàn bộ vòng tròn cho thấy đầy đủ một chu kỳ 24 giờ.
Điểm đáng chú ý là subplot_kw=dict(polar=True) trong Python giúp chuyển hệ trục thông thường sang hệ trục tròn, nơi dữ liệu được mô tả bằng góc và bán kính thay vì trục x và y. Chính cơ chế này tạo nên khả năng biểu diễn dữ liệu chu kỳ theo cấu trúc vòng tròn.
import matplotlib.pyplot as plt
import numpy as np
data_very_large["Hour"] = data_very_large["Datetime"].dt.hour
hourly_avg = data_very_large.groupby("Hour")["Usage"].mean()
hourly_avg.head()
values = hourly_avg.values
angles = np.linspace(0, 2*np.pi, len(values), endpoint=False)
fig, ax = plt.subplots(figsize=(6,6),
subplot_kw=dict(polar=True))
bars = ax.bar(angles, values, width=0.25)
ax.set_xticks(angles)
ax.set_xticklabels(hourly_avg.index)
plt.title("Circle Segment - Avg Electricity Usage by Hour")
plt.show()Lưu ý: plt.subplots(subplot_kw=dict(polar=True)) → subplot_kw là biến đổi trục tọa độ, dict(polar=True) là để tạo trục tọa độ dạng tròn với góc (angle) và bán kính (radius), không dùng trục tọa độ x, y. Chính vì vậy mới vẽ được biểu đồ dạng vòng tròn
Nhận xét
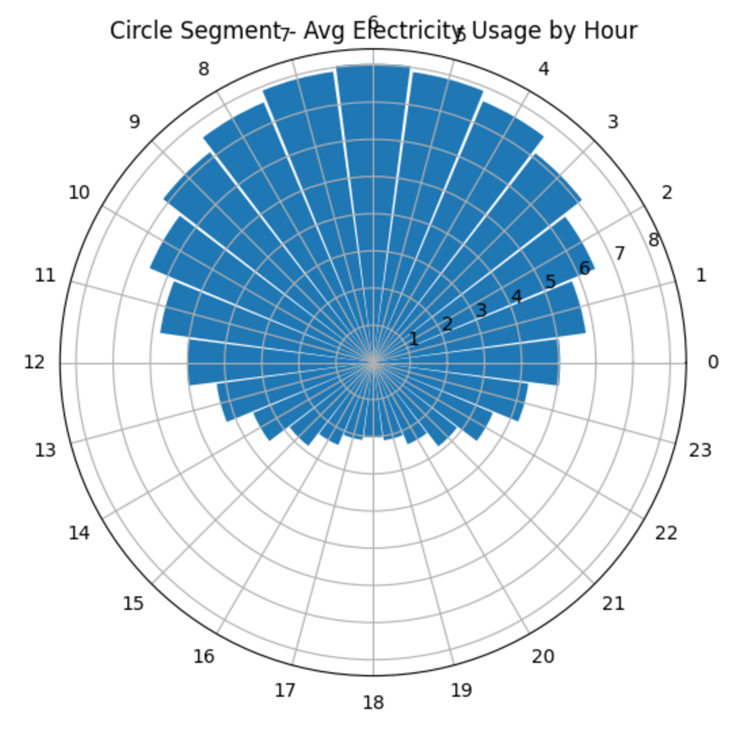
- Mỗi cột = 1 giờ (0 → 23) . Độ dài cột = mức tiêu thụ điện trung bình
- Giờ cao điểm: khoảng 5h–7h, đỉnh rõ nhất ở 6h . Sau đỉnh 6h, mức tiêu thụ giảm dần về trưa và chiều
- Giờ thấp điểm: khoảng 17h–19h, thấp nhất gần 18h. Từ tối đến đêm, mức tiêu thụ ở mức thấp rồi tăng lại về rạng sáng
- Có chu kỳ ngày rõ ràng . Peak: buổi sáng . Low: buổi chiều/tối . Có thể dùng để: dự báo , tối ưu hệ thống
Lựa chọn kỹ thuật trực quan hóa phù hợp
| Quy mô dữ liệu | Kỹ thuật khuyên dùng | Mục tiêu chính |
| Ít (10-50 bản ghi) | Chernoff Faces | Cảm nhận trực giác, cụm |
| Trung bình (50-500 bản ghi) | Star Glyphs | So sánh cấu hình đối tượng |
| Lớn (trên 10.000 bản ghi) | Pixel Visualization | Phát hiện xu hướng dài hạn |
| Dữ liệu chu kỳ lớn | Circle Segment | Phát hiện chu kỳ theo thời gian |
Kết luận
Kỹ thuật biểu tượng và pixel trong trực quan hóa giúp dữ liệu đa chiều và dữ liệu lớn trở nên dễ quan sát hơn thông qua hình dạng, màu sắc, nhịp điệu và mẫu lặp. Các phương pháp như Chernoff Faces, Star Glyphs, Pixel-based Visualization và Circle Segment không chỉ hỗ trợ trình bày dữ liệu, mà còn giúp phát hiện cấu trúc, xu hướng và điểm bất thường.
Mỗi kỹ thuật phù hợp với một mục tiêu riêng: Chernoff Faces giúp cảm nhận nhanh đặc điểm đối tượng, Star Glyphs hỗ trợ so sánh cấu hình đa thuộc tính, Pixel-based Visualization phù hợp với dữ liệu lớn, còn Circle Segment hiệu quả với dữ liệu có tính chu kỳ. Tuy nhiên, không có phương pháp nào tối ưu cho mọi trường hợp. Giá trị của trực quan hóa nằm ở việc chọn đúng kỹ thuật cho đúng dữ liệu và đúng câu hỏi phân tích.
Tham khảo thêm : https://www.sdml.cs.kent.edu/library/Keim00.pdf


