Các kỹ thuật hình học trong trực quan hóa dữ liệu giúp chúng ta thay đổi cách nhìn về dữ liệu. Nếu ở bài biểu đồ thống kê trong AI , dữ liệu chủ yếu được đọc thông qua các biểu đồ quen thuộc, thì ở bài này, dữ liệu không còn chỉ được xem như một bảng số nữa. Thay vào đó, ta bắt đầu nhìn dữ liệu như một không gian hình học, trong đó mỗi dòng dữ liệu là một điểm, còn mỗi thuộc tính là một trục trong không gian nhiều chiều.
Khi đó, trực quan hóa dữ liệu trở thành một bài toán quan trọng hơn: làm sao biểu diễn và quan sát được không gian nhiều chiều bằng khả năng nhìn của con người, vốn chỉ trực quan tốt trong 2D hoặc 3D. Đây cũng chính là lý do các kỹ thuật hình học ngày càng đóng vai trò quan trọng trong phân tích dữ liệu và AI.

1. Dữ liệu nhiều chiều và góc nhìn hình học
a. Dữ liệu nhiều chiều
Trong AI và Data Science, dữ liệu thường không chỉ có 2–3 thuộc tính mà có thể gồm nhiều. Như tuổi, thu nhập, mức chi tiêu hay tần suất mua hàng. Khi trực quan hóa dữ liệu, mỗi thuộc tính có thể được xem như một chiều của không gian dữ liệu. Vì vậy, dữ liệu có càng nhiều thuộc tính thì càng trở thành dữ liệu nhiều chiều.
Nếu dữ liệu có 2 thuộc tính, ta có thể biểu diễn trên mặt phẳng 2D; với 3 thuộc tính là không gian 3D. Tuy nhiên, khi số chiều tăng lên 4, 10 hoặc hàng trăm, con người không còn có thể quan sát trực tiếp toàn bộ không gian dữ liệu nữa.
Dữ liệu nhiều chiều không chỉ khó nhìn mà còn làm xuất hiện hiện tượng dữ liệu trở nên thưa thớt. Khi số chiều tăng, khoảng cách giữa các điểm cũng khó diễn giải hơn, khiến khái niệm “gần” và “xa” mất dần ý nghĩa trực quan. Điều này ảnh hưởng lớn đến các thuật toán AI như KNN, clustering hay các phương pháp dựa trên khoảng cách.
Vì vậy, các kỹ thuật hình học trong trực quan hóa dữ liệu trở nên quan trọng. Chúng giúp đưa dữ liệu từ không gian nhiều chiều về 2D hoặc 3D để con người dễ quan sát hơn nhưng vẫn giữ được cấu trúc quan trọng của dữ liệu.
b. Dataset minh họa
Trong bài này, ta sử dụng một dataset quen thuộc gồm các thuộc tính:
- Age (Tuổi)
- Income (Thu nhập)
- Spending Score (Chi tiêu)
- Frequency (Tần suất mua)
Với cách nhìn này, mỗi khách hàng là một điểm dữ liệu, còn mỗi thuộc tính là một chiều. Như vậy, toàn bộ dataset có thể được xem là một đám mây điểm trong không gian 4 chiều.
Mục tiêu của trực quan hóa lúc này là tìm ra một cách biểu diễn đơn giản hơn, nhưng vẫn giúp ta nhìn được cấu trúc chính của dữ liệu, chẳng hạn như xu hướng phân bố, mối liên hệ giữa các thuộc tính, sự hình thành các nhóm dữ liệu hoặc sự xuất hiện của những điểm bất thường.
2. Kỹ thuật Scatter Plot Matrix (SPLOM)
Với dữ liệu nhiều chiều, ta không thể quan sát trực tiếp toàn bộ không gian dữ liệu trên một hình duy nhất. Một cách đơn giản là tách dữ liệu thành từng cặp thuộc tính để xem lần lượt trên mặt phẳng 2D. SPLOM là kỹ thuật giúp ta làm điều này một cách có hệ thống.
SPLOM gồm nhiều biểu đồ tán xạ được sắp xếp thành ma trận. Mỗi hàng và mỗi cột tương ứng với một thuộc tính, còn mỗi ô trong ma trận là một scatter plot giữa hai thuộc tính đó. Nếu có d thuộc tính, ma trận sẽ có kích thước d x d
Nhờ đó, SPLOM không cho ta cái nhìn toàn cục của toàn bộ không gian nhiều chiều trong một lần, nhưng lại cho phép quan sát rất rõ quan hệ giữa từng cặp thuộc tính.
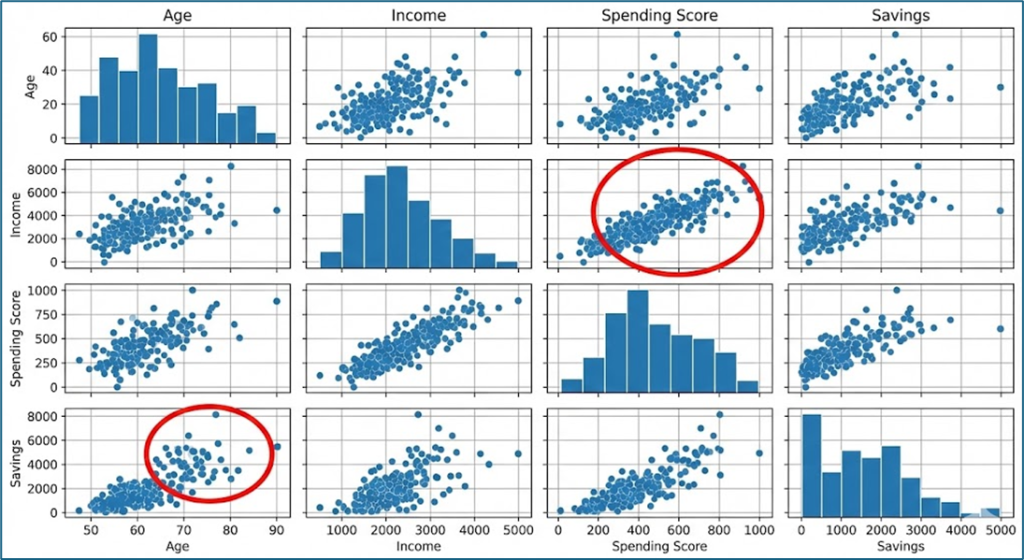
Giữa Income và Spending, ta có thể quan sát xu hướng phân bố của khách hàng theo thu nhập và mức chi tiêu. Trong khi đó, giữa Age và Spending, mối liên hệ có thể yếu hơn hoặc không rõ ràng.
SPLOM giúp gì?
- Quan sát mối quan hệ giữa từng cặp thuộc tính, từ đó nhận ra các xu hướng tương quan.
- Đường chéo hiển thị phân phối của từng thuộc tính, thường bằng histogram hoặc đường cong mật độ (KDE) để nhìn xu hướng phân bố mượt hơn.
- Phát hiện outlier: trong hình, ở các ô liên quan đến Savings có một số điểm nằm tách xa khỏi phần lớn dữ liệu, cho thấy các giá trị bất thường.
- Gợi ý cấu trúc dữ liệu: ví dụ giữa Income và Spending Score, các điểm tạo thành một dải nghiêng khá rõ, cho thấy hai thuộc tính này có xu hướng tương quan dương. Tuy nhiên, chưa thấy các cụm tách biệt rõ ràng.
Cách đọc SPLOM
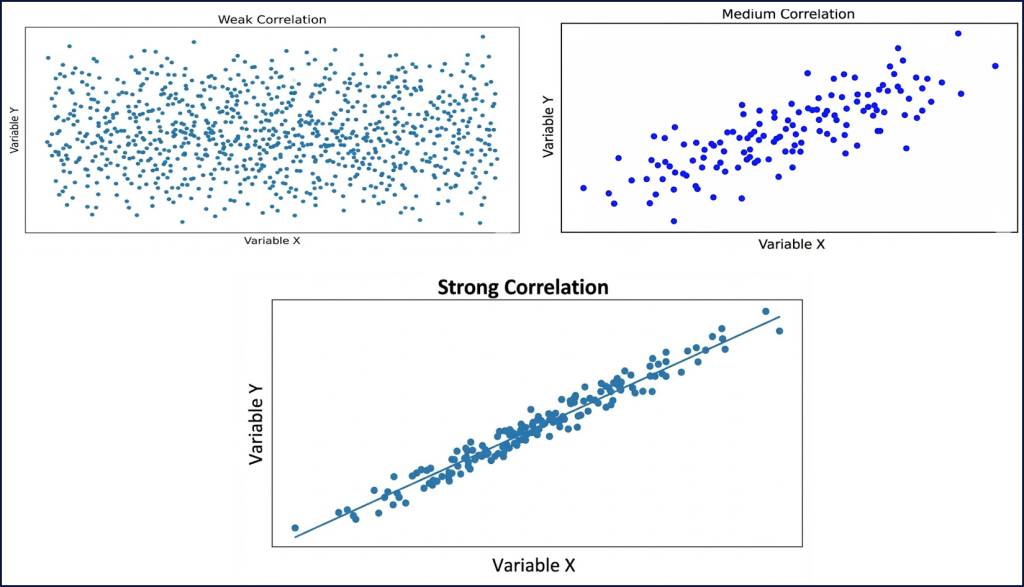
- Đám mây tròn → không liên quan (corr ≈ 0)
- Hình elip nghiêng → tương quan tuyến tính
- Dải hẹp → tương quan mạnh (|corr| ≈ 1)
Giới hạn của SPLOM
SPLOM rất mạnh, nhưng có yếu điểm như sau:
- Khi số thuộc tính tăng lên, chẳng hạn khoảng 10 thuộc tính hoặc hơn
- Dữ liệu lớn sẽ dễ thấy các điểm chồng lên nhau.
- PLOM chỉ cho thấy quan hệ giữa hai thuộc tính tại một thời điểm, nên chưa phản ánh được cấu trúc toàn cục của toàn bộ dữ liệu.
SPLOM chỉ là một trong các kỹ thuật hình học trong trực quan hóa, đặc biệt khi ta muốn khám phá quan hệ giữa từng cặp thuộc tính trước khi chuyển sang góc nhìn tổng thể hơn, như PCA, Parallel Coordinates…
3. Kỹ thuật Parallel Coordinates – Nhìn “hình dạng” của từng điểm dữ liệu
Nếu SPLOM giúp ta quan sát mối quan hệ giữa từng cặp thuộc tính, thì Parallel Coordinates lại cho ta một góc nhìn khác: nhìn một điểm dữ liệu trên toàn bộ các thuộc tính cùng lúc.
Đây là một trong các kỹ thuật hình học trong trực quan hóa rất hữu ích khi làm việc với dữ liệu nhiều chiều, vì nó không tách dữ liệu thành từng cặp thuộc tính như SPLOM, mà cố gắng giữ lại toàn bộ hồ sơ của từng dòng dữ liệu trong một hình duy nhất.
Ý tưởng của kỹ thuật này là “trải” các trục của không gian dữ liệu ra song song với nhau. Thay vì đặt điểm trong mặt phẳng hay không gian như scatter plot, ta biểu diễn:
- Mỗi thuộc tính bằng một trục dọc.
- Các trục được đặt song song từ trái sang phải.
- Mỗi dòng dữ liệu được biểu diễn bằng một đường gấp khúc đi qua tất cả các trục.
Với cách nhìn này, một khách hàng tương ứng với một đường. Đường đó đi qua các giá trị của Age, Income, Spending và Frequency, nên nó thể hiện toàn bộ thông tin của khách hàng đó trên tất cả các thuộc tính đang xét.
Cách đọc Parallel Coordinates
Parallel Coordinates không phù hợp để đọc từng điểm riêng lẻ như scatter plot. Thay vào đó, nó phù hợp hơn để nhìn “hình dạng” của dữ liệu, tức là nhìn cách các đường cùng đi lên, cùng đi xuống, cắt nhau hay tách biệt nhau.
Một số dấu hiệu cơ bản khi đọc hình:
- Nếu nhiều đường có xu hướng gần song song nhau, dữ liệu có thể đang có hành vi tương đối giống nhau.
- Nếu các đường cắt nhau nhiều, dữ liệu có mức độ đa dạng cao hơn.
- Nếu có một vài đường lệch hẳn khỏi phần lớn còn lại, đó có thể là dấu hiệu của outlier.
- Nếu xuất hiện những bó đường có hình dạng giống nhau, đó có thể là gợi ý ban đầu về các nhóm dữ liệu.
Minh họa trên dataset khách hàng
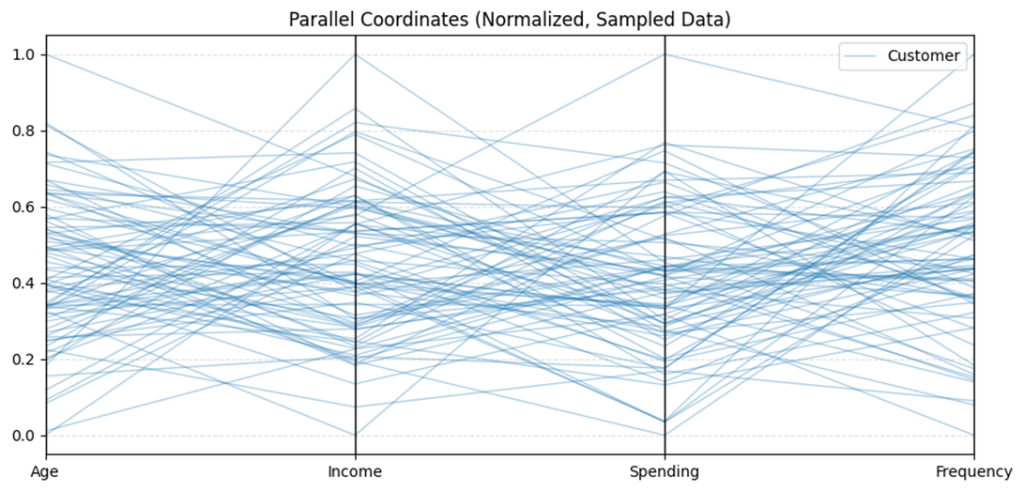
Giả sử bộ dữ liệu khách hàng có 4 thuộc tính: Age, Income, Spending, Frequency. Khi đó, hình Parallel Coordinates sẽ có 4 trục dọc đặt song song. Mỗi đường trong hình là một khách hàng, và đường đó đi qua cả 4 trục. Vì vậy, thay vì đọc từng điểm rời rạc, ta đang đọc toàn bộ hồ sơ của một khách hàng dưới dạng một đường liên tục.
- Trong hình này, các giá trị thường được chuẩn hóa về khoảng 0 đến 1. Điều đó có nghĩa là:
- 0 biểu diễn mức thấp trên một thuộc tính,
- 1 biểu diễn mức cao trên một thuộc tính.
- Việc chuẩn hóa là rất quan trọng, vì các thuộc tính ban đầu có thể dùng những đơn vị rất khác nhau, chẳng hạn tuổi, tiền và tần suất mua. Nếu không chuẩn hóa, hình dạng các đường sẽ bị méo và rất khó so sánh.
Cách quan sát dữ liệu trong hình
Nhìn tổng thể, nếu có rất nhiều đường chồng lên nhau, điều đó cho thấy dữ liệu khá đa dạng. Nếu chưa xuất hiện một bó đường rõ ràng hay một hình mẫu nổi bật, ta có thể tạm nói rằng chưa thấy cấu trúc cụm rõ ràng.
Khi quan sát từng đoạn giữa hai trục liên tiếp, ta có thể rút ra một số nhận xét:
- Age → Income: nếu các đường khá rối và không có xu hướng chung rõ ràng, điều đó cho thấy tuổi và thu nhập không có mối liên hệ mạnh.
- Income → Spending: nếu có nhiều đường cắt nhau, có thể hiểu rằng người có thu nhập cao chưa chắc chi tiêu cao; hành vi mua sắm giữa các khách hàng vẫn khá đa dạng.
- Spending → Frequency: nếu nhiều đường cùng đi lên, điều đó gợi ý rằng khách hàng chi tiêu cao có xu hướng mua thường xuyên hơn.
Điểm mạnh của Parallel Coordinates là nó giúp ta nhìn được hình dạng tổng thể của từng dòng dữ liệu, chứ không chỉ nhìn từng cặp thuộc tính riêng lẻ. Vì vậy, đây là một kỹ thuật rất phù hợp khi muốn bổ sung cho SPLOM trong mạch các kỹ thuật hình học trong trực quan hóa.
Giới hạn của Parallel Coordinates:
Dù hữu ích, Parallel Coordinates cũng có những giới hạn rõ ràng:
- Nếu số lượng dòng dữ liệu lớn, sẽ có quá nhiều đường chồng lên nhau và gây rối thị giác.
- Nếu dữ liệu chưa được chuẩn hóa, các trục có đơn vị khác nhau sẽ làm hình dạng trở nên khó đọc.
- Kỹ thuật này không nhấn mạnh khoảng cách hình học giữa các điểm như scatter plot hay PCA, mà chủ yếu cho thấy hình dạng và xu hướng của từng dòng dữ liệu.
Vì vậy, trong thực tế, Parallel Coordinates thường đi kèm với hai bước hỗ trợ:
- Chuẩn hóa dữ liệu để các trục có thể so sánh được.
- Giảm số chiều hoặc chọn lọc thuộc tính để hình bớt rối và dễ đọc hơn.
Minh họa 1: Tương quan dương
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
np.random.seed(42)
# Tạo dữ liệu có xu hướng dương + nhiễu
n = 10
income = np.linspace(30, 100, n)
spending = income + np.random.normal(0, 10, n) # thêm nhiễu
age = np.linspace(20, 60, n) + np.random.normal(0, 3, n)
frequency = spending / 10 + np.random.normal(0, 1, n)
df_pos_real = pd.DataFrame({
'Age': age, 'Income': income, 'Spending': spending, 'Frequency': frequency
})
# Chuẩn hóa
scaler = MinMaxScaler()
df_scaled = pd.DataFrame(scaler.fit_transform(df_pos_real), columns=df_pos_real.columns)
# Vẽ
plt.figure(figsize=(8,5))
for i in range(len(df_scaled)):
plt.plot(df_scaled.columns, df_scaled.iloc[i], alpha=0.7)
plt.title("Tương quan dương giữa các biến")
plt.ylim(0,1)
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()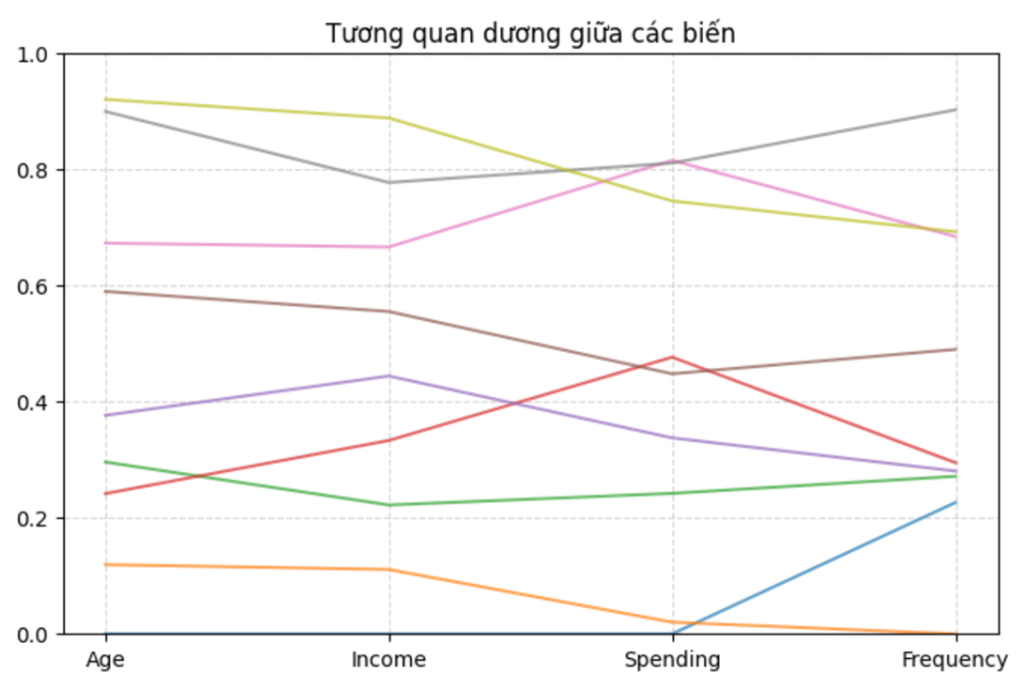
Nhìn tổng thể, phần lớn các đường giữa hai trục Income và Spending có xu hướng cùng đi lên. Tuy nhiên, chúng không hoàn toàn song song và vẫn có một vài đường lệch nhẹ. Điều này cho thấy giữa hai thuộc tính này có tương quan dương, nhưng không hoàn toàn lý tưởng.
Từ hình này, ta có thể kết luận:
- Có xu hướng tương quan dương giữa Income và Spending.
- Mối quan hệ này khá rõ nhưng không hoàn toàn tuyến tính.
- Dữ liệu vẫn có nhiễu, nên không phải mọi đường đều đi cùng một hướng.
Câu hỏi gợi: “Tương quan này khoảng bao nhiêu? 0.6 hay 0.7?”
Minh họa 2: Tương quan âm
# Dataset tương quan âm
df_neg = pd.DataFrame({
'Age': [20, 25, 30, 35, 40, 45, 50, 55],
'Income': [30, 40, 50, 60, 70, 80, 90, 100],
'Spending': [100, 90, 80, 70, 60, 50, 40, 30], # giảm khi Income tăng
'Frequency': [9, 8, 7, 6, 5, 4, 3, 2]
})
# Chuẩn hóa
df_neg_scaled = pd.DataFrame(scaler.fit_transform(df_neg), columns=df_neg.columns)
# Vẽ
plt.figure(figsize=(8,5))
for i in range(len(df_neg_scaled)):
plt.plot(df_neg_scaled.columns, df_neg_scaled.iloc[i], alpha=0.7)
plt.title("Tương quan âm (giao mạnh)")
plt.ylim(0,1)
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()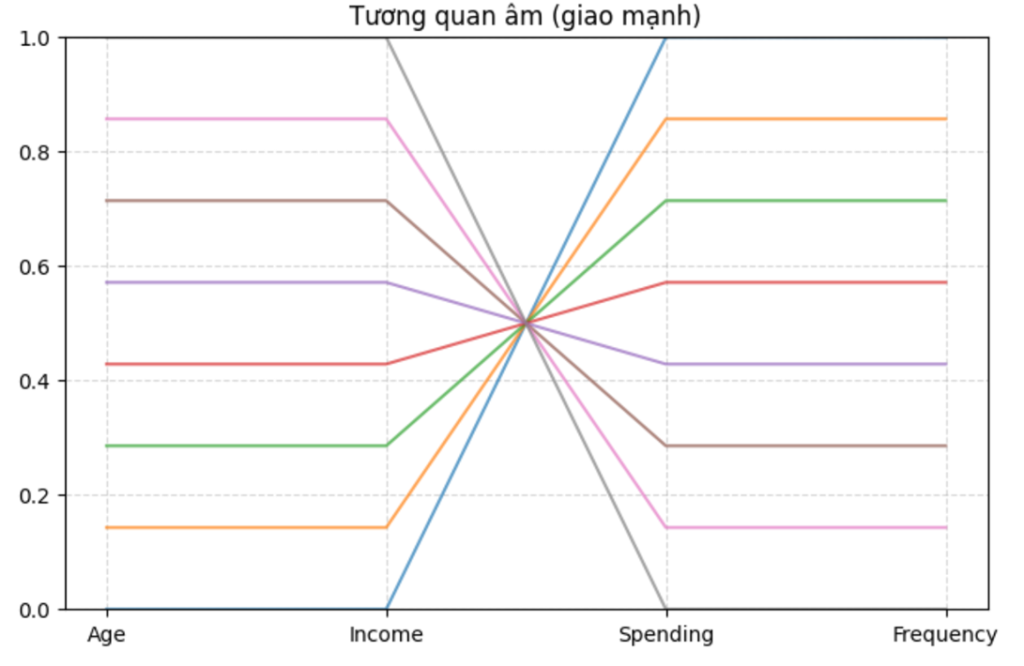
Nhìn tổng thể, các đường giữa hai trục Income và Spending cắt nhau rất rõ, tạo thành một hình giống như bó dây chữ X. Đây là dấu hiệu trực quan rất mạnh của tương quan âm. Cụ thể: Điểm có Income cao nối sang Spending thấp. Điểm có Income thấp nối sang Spending cao.
Nhìn vào thấy ngay mối quan hệ ngược chiều giữa hai thuộc tính:
- Đường cắt nhau có tổ chức thường là dấu hiệu của tương quan âm.
- Nếu giao cắt tập trung và rõ, quan hệ thường rất mạnh.
- Nếu các đường cắt lộn xộn, chưa thể kết luận có tương quan.
Từ hình này, ta có thể nói:
- Có tương quan âm rất mạnh giữa Income và Spending.
- Pattern rất rõ nên mô hình học thường sẽ dễ nhận ra quan hệ này.
- Hệ số tương quan trong trường hợp này được dự đoán là gần -1.
Minh họa 3: Không có tương quan
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
np.random.seed(42)
# Dataset ngẫu nhiên
df_rand = pd.DataFrame({
'Age': np.random.randint(20, 60, 10),
'Income': np.random.randint(30, 100, 10),
'Spending': np.random.randint(20, 100, 10),
'Frequency': np.random.randint(1, 10, 10)
})
# Chuẩn hóa
scaler = MinMaxScaler()
df_rand_scaled = pd.DataFrame(scaler.fit_transform(df_rand), columns=df_rand.columns)
# Vẽ
plt.figure(figsize=(8,5))
for i in range(len(df_rand_scaled)):
plt.plot(df_rand_scaled.columns, df_rand_scaled.iloc[i], alpha=0.7)
plt.title("Dữ liệu ngẫu nhiên (không tương quan)")
plt.ylim(0,1)
plt.grid(True, linestyle='--', alpha=0.5)
plt.show()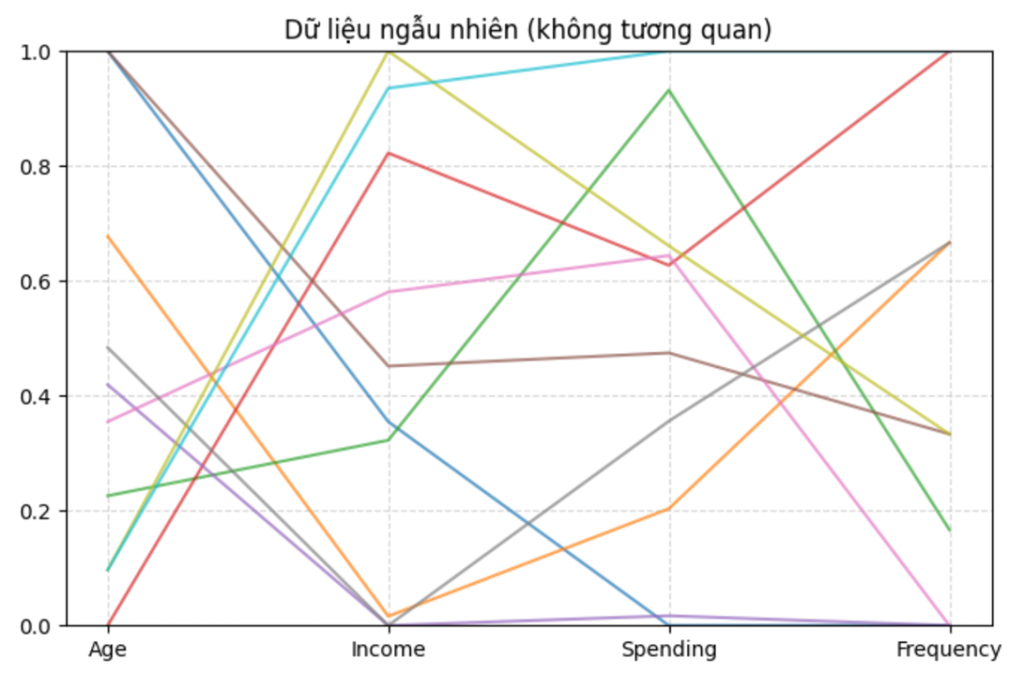
Nhìn tổng thể, các đường lên xuống khá lung tung và cắt nhau ở nhiều nơi. Không có hướng đi chung nổi bật, cũng không thấy một hình dạng lặp lại rõ ràng.
Khi quan sát từng đoạn:
- Age → Income: có đường đi lên, có đường đi xuống, nên chưa thấy xu hướng chung.
- Income → Spending: các đường cắt nhau liên tục và thiếu tổ chức.
- Spending → Frequency: tình hình tương tự, không xuất hiện quy luật rõ.
Điểm quan trọng ở đây là: giao nhau nhiều chưa chắc là có cấu trúc.
Trong hình này, các đường giao nhau theo kiểu hỗn loạn, nên đó là dấu hiệu của dữ liệu không có tương quan rõ ràng.
Ý nghĩa
- Nếu các đường giao nhau có tổ chức, có thể tồn tại tương quan.
- Nếu các đường giao nhau hỗn loạn, thường là dấu hiệu không có mối liên hệ đáng kể.
So sánh nhanh với hai trường hợp trước:
- Tương quan dương: nhiều đường cùng hướng, khá song song.
- Tương quan âm: các đường cắt nhau có cấu trúc.
- Không tương quan: các đường giao nhau hỗn loạn.
è Dữ liệu này nhìn như một đám dây điện rối, và đó chính là dấu hiệu cho thấy dữ liệu chưa có cấu trúc rõ để học.
è Nếu dữ liệu có hình dạng hỗn loạn như vậy, nhiều mô hình đơn giản sẽ gặp khó khăn:
- KNN khó phân biệt được vùng lân cận có ý nghĩa.
- Clustering khó hình thành cụm rõ ràng.
- Mô hình tuyến tính khó tìm được quan hệ ổn định để fit.
Insight quan trọng: Khi trực quan hóa chưa cho thấy pattern rõ, khả năng cao mô hình cũng sẽ khó học được cấu trúc mạnh từ dữ liệu.
4. Kỹ thuật PCA (Principal Component Analysis) – Nghệ thuật “nhìn đúng góc”
Khi dữ liệu có quá nhiều chiều, các kỹ thuật như SPLOM hay Parallel Coordinates bắt đầu bộc lộ hạn chế. SPLOM dễ bị quá tải nếu số thuộc tính lớn, còn Parallel Coordinates có thể trở nên rất rối khi số đường quá nhiều.
Lúc này, ta cần một cách tiếp cận khác trong nhóm các kỹ thuật hình học trong trực quan hóa: không cố nhìn toàn bộ không gian dữ liệu gốc, mà tìm cách chiếu dữ liệu xuống 2D nhưng vẫn giữ lại được phần thông tin quan trọng nhất. Đó chính là vai trò của PCA (Principal Component Analysis).
Bài toán đặt ra
Giả sử mỗi khách hàng được mô tả bởi 4 thuộc tính: Age, Income, Spending, Frequency. Khi đó, mỗi khách hàng là một điểm trong không gian 4 chiều.
Vấn đề là con người không thể quan sát trực tiếp không gian 4 chiều này. Trong khi đó, ta vẫn muốn trả lời những câu hỏi quen thuộc khi phân tích dữ liệu:
- Dữ liệu có tạo thành các nhóm khách hàng hay không?
- Có điểm nào bất thường không?
- Cấu trúc chung của dữ liệu trông như thế nào?
Muốn làm được điều đó, ta cần đưa dữ liệu từ không gian 4 chiều về một mặt phẳng 2D đủ tốt để quan sát.
Ý tưởng của PCA
Nếu phải chiếu dữ liệu từ 4D xuống 2D, ta không thể chiếu một cách ngẫu nhiên. Ta cần chọn cách chiếu sao cho:
- giữ lại được nhiều thông tin nhất có thể,
- tránh làm các điểm dồn chồng lên nhau quá nhiều,
- và hạn chế làm méo cấu trúc vốn có của dữ liệu.
Đó chính là ý tưởng cốt lõi của PCA. Trong các kỹ thuật hình học trong trực quan hóa, PCA có thể được hiểu là phương pháp tự động tìm ra góc nhìn tốt nhất để quan sát dữ liệu. Nói trực giác hơn:
- nếu dữ liệu khi chiếu ra bị dồn cục lại, ta sẽ khó nhìn thấy cấu trúc;
- nếu dữ liệu trải rộng ra, ta sẽ nhìn thấy rõ hơn các nhóm, xu hướng và điểm bất thường.
Vì vậy, PCA chọn ra hướng chiếu làm cho dữ liệu trải rộng nhất. Hướng trải rộng nhất này được gọi là thành phần chính thứ nhất hay PC1. Sau đó, PCA tìm tiếp một hướng thứ hai vuông góc với hướng đầu tiên và vẫn giữ được nhiều thông tin nhất có thể; đó là PC2.
Hiểu PCA bằng trực giác hình học
Hãy tưởng tượng bạn có một đám mây điểm trong không gian 3D. Nếu xoay đám mây đó và nhìn từ các góc khác nhau, bạn sẽ thấy:
- có góc nhìn làm lộ cấu trúc rất rõ,
- nhưng cũng có góc nhìn khiến các điểm chồng lên nhau và trở nên khó phân biệt.
PCA hoạt động theo đúng tinh thần đó: nó tự động tìm góc nhìn tốt nhất để dữ liệu “lộ hình” rõ nhất.
Minh họa PCA với dữ liệu khách hàng
1. Tạo dữ liệu mẫu
Ta tạo một bộ dữ liệu gồm 2 nhóm khách hàng để PCA có thể bộc lộ cấu trúc rõ ràng hơn:
- Nhóm 1: trẻ hơn, thu nhập thấp hơn, nhưng chi tiêu cao và mua thường xuyên.
- Nhóm 2: lớn tuổi hơn, thu nhập cao hơn, nhưng chi tiêu thấp hơn và mua ít thường xuyên hơn.
importpandasaspd
import numpy as np
np.random.seed(42)
# Nhóm 1: trẻ, thu nhập thấp, chi tiêu cao
group1 = pd.DataFrame({
'Age': np.random.normal(25, 3, 50),
'Income': np.random.normal(40, 5, 50),
'Spending': np.random.normal(70, 5, 50),
'Frequency': np.random.normal(8, 1, 50)
})
# Nhóm 2: lớn tuổi, thu nhập cao, chi tiêu thấp
group2 = pd.DataFrame({
'Age': np.random.normal(50, 3, 50),
'Income': np.random.normal(80, 5, 50),
'Spending': np.random.normal(40, 5, 50),
'Frequency': np.random.normal(4, 1, 50)
})
# Gộp lại
df = pd.concat([group1, group2], ignore_index=True)2. Chuẩn hóa dữ liệu
Trước khi áp dụng PCA, ta cần chuẩn hóa dữ liệu để các thuộc tính có cùng thang đo. Đây là bước quan trọng, vì nếu một thuộc tính có giá trị lớn hơn hẳn các thuộc tính khác, nó có thể chi phối kết quả PCA.
fromsklearn.preprocessingimportStandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(df)3. Áp dụng PCA
fromsklearn.decompositionimportPCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)Giải thích:
- pca = PCA(n_components=2) Tạo đối tượng pca, dùng nó để làm công cụ “chiếu” dữ liệu lên 1 mặt phẳng và trả về dữ liệu trên hệ trục mới của mặt phẳng đó.
- n_components = 2 là số chiều, tức “Tôi muốn giảm dữ liệu xuống 2 chiều”
- fit : PCA học từ dữ liệu để tìm ra các hướng quan trọng nhất.
- Hướng thứ nhất là nơi dữ liệu trải rộng nhất → PC1
- Hướng thứ hai vuông góc với hướng thứ nhất và vẫn giữ được nhiều thông tin → PC2
- transform: Sau khi tìm được hướng, chiếu tất cả điểm dữ liệu lên 2 trục mới.
Kết quả cuối cùng là X_pca, một ma trận 2 chiều, trong đó mỗi dòng là vị trí mới của một khách hàng trên mặt phẳng PCA.
4. Vẽ biểu đồ
importmatplotlib.pyplotasplt
plt.figure(figsize=(6,5))
plt.scatter(X_pca[:,0], X_pca[:,1])
plt.title("PCA - Nhìn dữ liệu 4D trên 2D")
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.grid(True)
plt.show()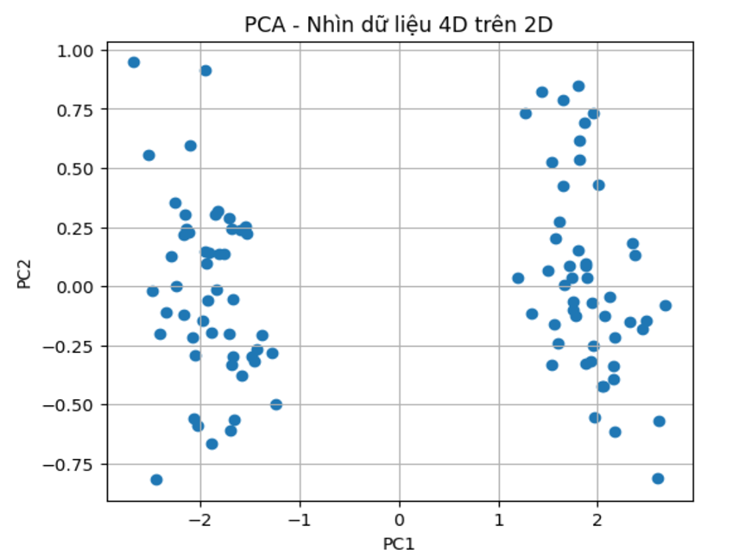
5. Khi chạy xong, sẽ thấy gì?
Dữ liệu không còn là một “đám mây loạn” khó hiểu nữa. Sau khi được chiếu về 2D bằng PCA, ta có thể thấy hai cụm tách nhau khá rõ.
Ý nghĩa của hai trục mới
- PC1 (trục ngang): đây là hướng quan trọng nhất, vì nó giữ lại lượng biến thiên lớn nhất của dữ liệu. Trong ví dụ này, PC1 thường là trục giúp tách hai nhóm khách hàng rõ nhất.
- PC2 (trục dọc): đây là hướng quan trọng thứ hai. Nó vẫn chứa thông tin, nhưng thường đóng vai trò bổ sung cho PC1.
Nếu khoảng cách giữa hai cụm theo PC1 lớn, điều đó cho thấy dữ liệu có cấu trúc tốt và việc phân loại trở nên dễ hơn. Nếu hầu như không có điểm nào nằm lẫn giữa hai cụm, ta có thể nói dữ liệu khá sạch và ít nhiễu.
6. So sánh
- Trước PCA: dữ liệu nằm trong không gian 4 chiều, con người không thể quan sát trực tiếp.
- Sau PCA: dữ liệu được chiếu xuống 2D, và cấu trúc của dữ liệu trở nên dễ nhìn hơn nhiều.
Từ đây, ta rút ra ba ý quan trọng sau:
- PCA giúp ta nhìn thấy thứ mà trước đó mắt người không thể nhìn trực tiếp.
- PCA không tự tạo ra cấu trúc mới; nó chỉ làm lộ rõ hơn cấu trúc vốn đã có trong dữ liệu.
- Nếu dữ liệu thực sự có cấu trúc, PCA sẽ giúp ta thấy rõ nó hơn. Ngược lại, nếu dữ liệu vốn không có cấu trúc rõ, PCA cũng không thể “cứu” được.
Trực giác cần nhớ về PCA
Về mặt sử dụng, PCA khá dễ: ta chỉ cần tạo đối tượng PCA, đưa dữ liệu vào, và yêu cầu giảm xuống số chiều mong muốn. Nhưng điều quan trọng hơn là phải hiểu PCA đang làm gì về mặt ý tưởng.
PCA đi tìm một mặt phẳng tốt nhất để biểu diễn dữ liệu. “Tốt nhất” ở đây không có nghĩa là đẹp nhất, mà là mặt phẳng giúp dữ liệu trải rộng ra nhiều nhất, nhờ đó cấu trúc trở nên dễ quan sát hơn.
Có thể hình dung như sau: dữ liệu ban đầu giống như một đám mây điểm trong không gian nhiều chiều. PCA sẽ xoay hệ trục và chọn ra một mặt phẳng nghiêng sao cho khi chiếu dữ liệu lên đó, các điểm không bị dính vào nhau quá nhiều mà “lộ hình” rõ hơn.
Đây chính là tinh thần rất điển hình trong các kỹ thuật hình học trong trực quan hóa: thay vì chỉ nhìn dữ liệu theo hệ trục gốc, ta chủ động tìm một góc nhìn mới giúp cấu trúc quan trọng lộ ra rõ hơn.
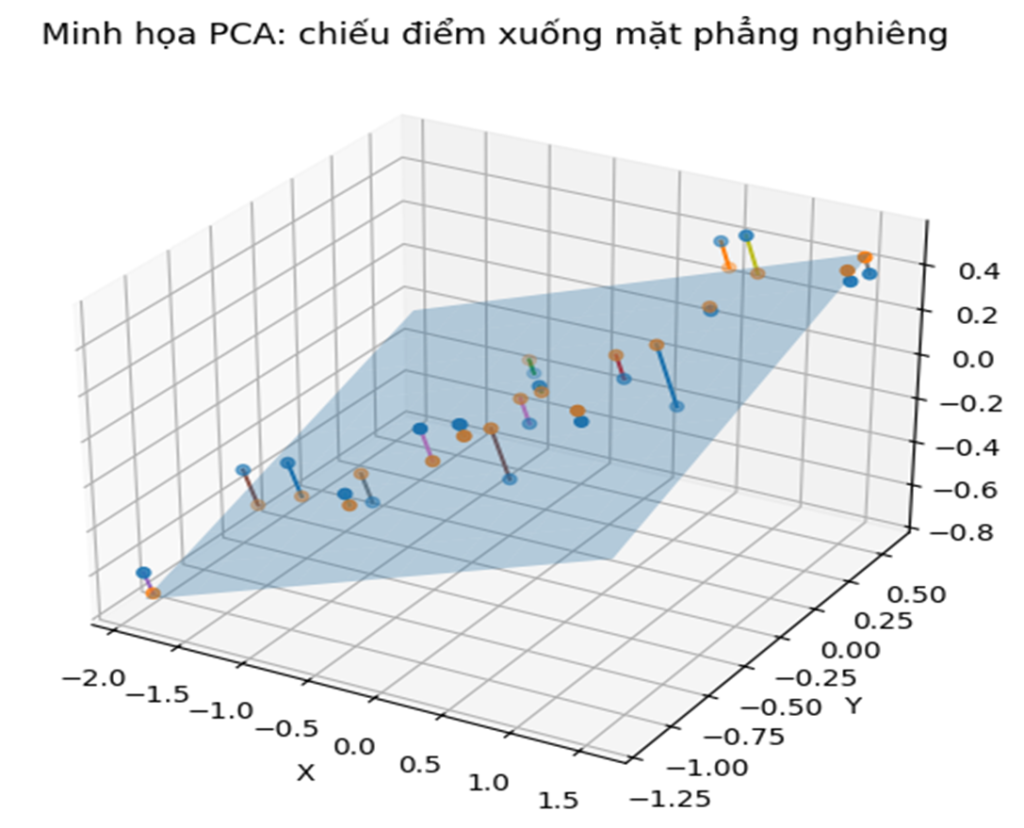
PCA không ném dữ liệu xuống 2D một cách ngẫu nhiên — mà nó chọn mặt phẳng mà dữ liệu ‘lộ hình’ rõ nhất.
Giới hạn của PCA
Dù rất mạnh, PCA không phải lúc nào cũng hoàn hảo. PCA chọn hướng có độ phân tán lớn nhất (variance lớn nhất), nhưng hướng có variance lớn nhất không phải lúc nào cũng là hướng quan trọng nhất cho bài toán. Ví dụ:
- một thuộc tính có rất nhiều nhiễu,
- nhiễu đó làm variance tăng mạnh,
- PCA vẫn có thể ưu tiên hướng này vì nó chỉ nhìn vào độ phân tán.
Do đó:
- PCA rất tốt để khám phá dữ liệu (EDA),
- nhưng khi dùng cho bài toán mô hình hóa, cần cẩn thận và không nên xem PCA như một giải pháp luôn luôn đúng.
Tóm lược các kỹ thuật hình học trong trực quan hóa
Ba kỹ thuật trong bài này không loại trừ nhau, mà bổ sung cho nhau:
- SPLOM: giúp nhìn quan hệ giữa từng cặp thuộc tính.
- Parallel Coordinates: giúp nhìn hình dạng của từng điểm dữ liệu trên toàn bộ các thuộc tính.
- PCA: giúp nhìn cấu trúc tổng thể của dữ liệu khi chiếu xuống không gian thấp chiều hơn.
Dù cách tiếp cận khác nhau, cả ba đều cùng giải quyết một vấn đề cốt lõi: Làm sao hiểu dữ liệu nhiều chiều bằng khả năng quan sát của mắt người.
5. Các kỹ thuật hình học trực quan khác
Ngoài ba kỹ thuật chính đã học (SPLOM, Parallel Coordinates, PCA), vẫn còn các kỹ thuật hình học trong trực quan hóa khác. Chúng giúp chúng ta quan sát dữ liệu dưới những góc nhìn khác nhau.
Để dễ so sánh, ta có thể tóm lược một số kỹ thuật trong bảng sau.
Bảng tổng hợp các kỹ thuật hình học trong trực quan hóa dữ liệu
| Kỹ thuật | Nhóm | Ý tưởng chính | Khi nào dùng | Đặc điểm nổi bật |
| SPLOM | Cặp thuộc tính | Vẽ scatter cho mọi cặp thuộc tính | Khám phá quan hệ 2 thuộc tính | Nhìn được tương quan, nhưng không thấy tổng thể |
| Parallel Coordinates | Theo điểm | Mỗi dòng dữ liệu = 1 đường | So sánh “profile” từng điểm | Thấy pattern, nhưng dễ rối |
| PCA | Chiếu tuyến tính | Tìm hướng variance lớn nhất | Giảm chiều, nhìn cấu trúc tổng thể | Nhanh, đơn giản, dễ giải thích |
| t-SNE | Chiếu phi tuyến | Giữ điểm gần nhau ở gần | Nhìn cluster rõ | Rất trực quan, nhưng mất cấu trúc toàn cục |
| UMAP | Chiếu phi tuyến | Giữ cả local + global | Dataset lớn, embedding | Nhanh hơn t-SNE, phổ biến trong AI |
| MDS | Khoảng cách | Giữ khoảng cách giữa các điểm | Khi khoảng cách là quan trọng | Trực quan, nhưng chậm |
| Isomap | Manifold | Giữ cấu trúc không gian cong | Dữ liệu phi tuyến (non-linear) | Hiểu “hình dạng ẩn” của dữ liệu |
| Heatmap (Correlation) | Quan hệ | Màu sắc biểu diễn tương quan | Phân tích thuộc tính | Dễ nhìn, nhưng không thấy hình học |
| Radar Chart | Theo điểm | Mỗi điểm = đa giác | So sánh ít thuộc tính | Trực quan nhưng không scale tốt |
Mỗi kỹ thuật là một “cách nhìn” dữ liệu khác nhau
- SPLOM → nhìn từng mối quan hệ
- Parallel → nhìn từng đối tượng
- PCA → nhìn toàn bộ cấu trúc
- t-SNE / UMAP → làm rõ cụm
- MDS / Isomap → giữ hình dạng không gian
Không có kỹ thuật nào là tốt nhất — chỉ có kỹ thuật phù hợp với cách bạn muốn nhìn dữ liệu.
Trong thực tế, người làm AI thường không dùng một kỹ thuật duy nhất.
Họ kết hợp nhiều cách nhìn để hiểu dữ liệu trước khi xây dựng mô hình.
6. Kết luận
Ở mức sâu hơn, trực quan hóa dữ liệu không đơn thuần là vẽ biểu đồ đẹp. Bản chất của nó là tìm cách biến dữ liệu thành hình ảnh để ta có thể nhìn thấy cấu trúc ẩn bên trong.
Nói cách khác, trực quan hóa dữ liệu là sự kết hợp của:
- Hình học: mỗi dòng dữ liệu là một điểm
- Không gian: dữ liệu tồn tại trong nhiều chiều
- Phép chiếu: đưa dữ liệu về 2D hoặc 3D để con người quan sát
Chính vì vậy, toàn bộ quá trình này có thể được hiểu là việc áp dụng các kỹ thuật hình học trong trực quan hóa để khám phá dữ liệu.
Tư duy cốt lõi cần ghi nhớ: Dữ liệu không chỉ là bảng số — nó là một không gian mà bạn cần quan sát và khám phá. Nếu bạn muốn tiến xa trong AI, đừng chỉ tập trung vào mô hình. Trước hết, hãy học cách nhìn dữ liệu, hiểu dữ liệu đang phân bố như thế nào, có cấu trúc gì, và có gì bất thường.
Khi đối diện với một dataset, hãy luôn tự hỏi:
- Dữ liệu đang nằm trong không gian bao nhiêu chiều?
- Có tồn tại các cụm dữ liệu hay không?
- Có điểm nào bất thường không?
- Có thể chiếu dữ liệu xuống 2D mà vẫn giữ được cấu trúc quan trọng không?
Nếu bạn nhìn thấy được cấu trúc của dữ liệu, bạn sẽ có cơ sở để chọn mô hình phù hợp. Ngược lại, nếu dữ liệu trông “hỗn loạn” ngay từ trực quan hóa, thì khả năng cao mô hình cũng sẽ gặp khó khăn.
Tham khảo thêm:https://www.scribd.com/document/941292546/25-Data-Visualization-Geometric-Visualization

