Phân phối log-normal trong thống kê là một trong những phân phối xuất hiện nhiều nhất trong dữ liệu thực tế, đặc biệt là trong hệ thống, kinh tế và AI. Phân phối này thường bị bỏ qua hoặc bị nhầm lẫn với phân phối lệch phải nói chung, nhưng thực chất nó phản ánh một cơ chế sinh dữ liệu rất đặc trưng.
Khác với các phân phối chỉ mô tả hình dạng, phân phối log-normal cho ta một manh mối quan trọng về cách dữ liệu được tạo ra: dữ liệu tăng trưởng theo tỉ lệ, chứ không phải bằng cách cộng dồn đơn giản.
Phân phối log-normal là gì
Phân phối log-normal là dạng phân phối trong đó log tự nhiên của dữ liệu tuân theo phân phối chuẩn. Hệ quả là dữ liệu gốc có hình dạng lệch phải rõ rệt, với đa số giá trị nằm ở mức nhỏ đến trung bình, và một số ít giá trị lớn kéo dài về phía bên phải.
Không giống phân phối mũ, phân phối log-normal không giảm đều ngay từ đầu. Thay vào đó, nó có một vùng tập trung khá rõ ràng, sau đó mới kéo dài dần về phía các giá trị lớn. Chính vì vậy, log-normal thường được xem là một dạng lệch phải “có trật tự”.
Trong phân phối log-normal, những giá trị lớn hiếm gặp không phải là ngoại lệ ngẫu nhiên. Chúng là hệ quả tự nhiên của quá trình sinh dữ liệu dựa trên tăng trưởng theo tỉ lệ.
Có thể gặp phân phối log-normal ở đâu?
Phân phối log-normal xuất hiện rất thường xuyên trong những hiện tượng mà giá trị được hình thành qua nhiều bước nhân tỉ lệ, thay vì cộng dồn.
Một ví dụ quen thuộc là thu nhập cá nhân. Thu nhập thường tăng theo phần trăm, theo thưởng, theo đầu tư, chứ không tăng đều từng khoản cố định. Qua thời gian, cơ chế nhân này tạo ra một phân phối lệch phải với hình dạng log-normal.
Trong hệ thống và AI, bạn có thể gặp phân phối log-normal trong:
- thời gian phản hồi của hệ thống
- độ trễ trong mạng
- thời gian huấn luyện mô hình
- kích thước file và dung lượng log
Ngoài ra, phân phối log-normal còn xuất hiện trong:
- độ lớn của lỗi (error magnitude)
- thời gian hoàn thành công việc
- quy mô tác vụ
Nói ngắn gọn, khi bạn thấy dữ liệu lệch phải nhưng không quá hỗn loạn, rất có thể bạn đang nhìn vào một phân phối log-normal.
Dùng phân phối log-normal khi nào?
Bạn nên nghĩ đến phân phối log-normal trong thống kê khi dữ liệu có các đặc điểm sau:
- giá trị luôn lớn hơn 0
- lệch phải rõ rệt
- giá trị lớn xuất hiện ít nhưng không quá hiếm
- sai khác theo tỉ lệ quan trọng hơn sai khác theo độ lệch tuyệt đối
Một dấu hiệu rất mạnh là: lấy log dữ liệu xong thì hình dạng trở nên gần chuẩn.
Trong những trường hợp này, nếu bạn cố gắng mô hình hóa dữ liệu bằng phân phối chuẩn trên thang gốc, bạn sẽ đánh giá sai xác suất của các giá trị lớn. Điều này thường dẫn đến những nhận định quá lạc quan về rủi ro.
Ví dụ dữ liệu
Hãy tưởng tượng bạn đo thời gian phản hồi của một hệ thống trực tuyến. Phần lớn request được xử lý trong thời gian ngắn. Một số ít request chậm hơn do tải cao. Và rất hiếm khi có những request cực kỳ chậm vì sự cố bất thường.
Nếu bạn vẽ histogram trên thang gốc, dữ liệu sẽ lệch phải rất rõ. Tuy nhiên, khi bạn lấy log thời gian phản hồi và vẽ lại, hình dạng phân phối trở nên cân đối hơn nhiều.
Đây là dấu hiệu kinh điển của phân phối log-normal trong thống kê.
Code Python và đồ thị phân phối log-normal
import numpy as np
import matplotlib.pyplot as plt
# Ví dụ: dữ liệu lệch phải theo phân phối log-normal
samples = np.random.lognormal(mean=1.0, sigma=0.6, size=20000)
plt.hist(samples, bins=50, density=True)
plt.title("Phân phối log-normal")
plt.xlabel("Giá trị")
plt.ylabel("Mật độ")
plt.show()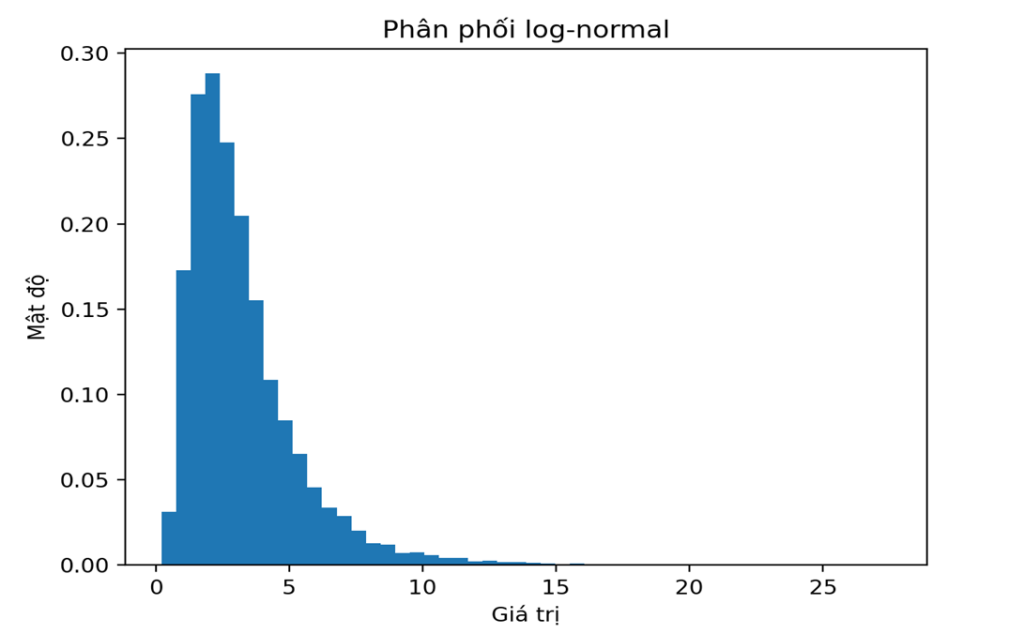
Đặc điểm thấy rõ trên biểu đồ:
- Lệch phải rõ rệt
- Có vùng tập trung ở giữa
- Đuôi phải kéo dài nhưng không quá cực đoan
- Giá trị luôn dương
Kết luận
Phân phối log-normal trong thống kê giúp ta hiểu rõ nhiều dạng dữ liệu lệch phải thường gặp trong thực tế. Nó không chỉ cho biết hình dạng dữ liệu, mà còn phản ánh cơ chế tăng trưởng theo tỉ lệ đứng sau quá trình sinh dữ liệu.
Nhận ra phân phối log-normal giúp bạn tránh việc ép dữ liệu về phân phối chuẩn một cách máy móc, đồng thời đưa ra các mô hình và đánh giá rủi ro sát với thực tế hơn.
Đọc các bài về phân phối trong thống kê
Nếu bạn quan tâm đến hình dạng phân phối, bạn có thể đọc lại bài về phân phối đều và phân phối đa đỉnh, cũng như bài về phân phối lệch trái và lệch phải trong thống kê.
Nếu dữ liệu của bạn gắn liền với thời gian chờ và quá trình vận hành, bài viết về phân phối mũ và phân phối Gamma trong thống kê sẽ giúp bạn hiểu rõ hơn cách các phân phối này mô hình hóa dữ liệu theo thời gian.


