Định lý giới hạn trung tâm trong AI là một nền tảng ít được nhắc tới. Tuy nhiên, nó lại đóng vai trò quan trọng trong cách các hệ thống học máy vận hành . Khi học máy và AI ngày càng đi vào đời sống, ta thường quan tâm đến mô hình nào thông minh hơn. Ta cũng chú ý đến thuật toán nào chính xác hơn. Nhưng có một câu hỏi nền tảng hơn. Đó là vì sao AI vẫn có thể hoạt động ổn định trong một thế giới đầy nhiễu, dữ liệu bẩn và con người thất thường.
Một phần quan trọng của câu trả lời nằm chính ở định lý giới hạn trung tâm trong AI. Định lý này không ồn ào. Nó cũng không xuất hiện trực tiếp trong code. Tuy vậy, nó đóng vai trò như một bộ khung. Nhờ đó, AI có thể “giữ thăng bằng” khi học, khi dự đoán và khi ra quyết định.
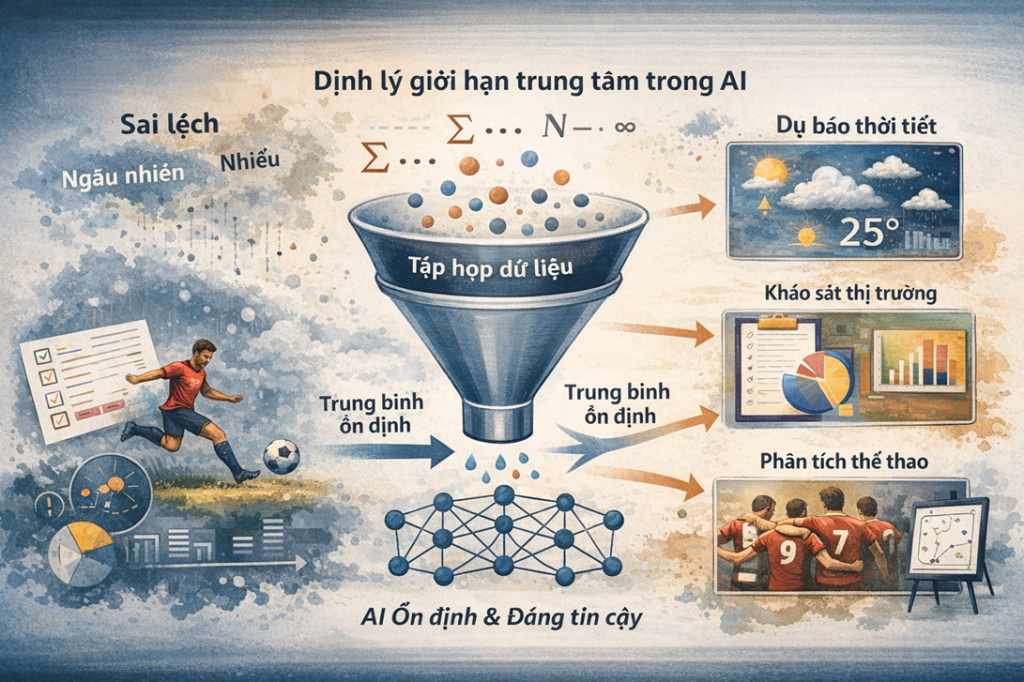
Định lý giới hạn trung tâm trong AI như bộ giảm nhiễu nền tảng
AI học từ những quan sát không hoàn hảo
AI không học trong một thế giới lý tưởng. Phần lớn dữ liệu mà nó gặp đều mang theo sai lệch: phép đo có thể không chính xác, nhãn có thể bị gán nhầm, còn hành vi con người thì thay đổi theo ngữ cảnh, cảm xúc và thời điểm. Vì vậy, một điểm dữ liệu riêng lẻ hiếm khi phản ánh đúng bản chất sự việc. Khi đó, mô hình có thể trông rất “nhạy”, nhưng thực ra lại thiếu độ tin cậy.
1.2 CLT khiến nhiễu trở nên dễ sống chung, và sự ổn định trở thành tiêu chuẩn
Định lý giới hạn trung tâm xuất hiện đúng ở điểm yếu đó. Khi số lượng quan sát tăng lên, các sai lệch nhỏ không còn tác động riêng rẽ mà dần triệt tiêu lẫn nhau. Trung bình của dữ liệu trở nên ổn định hơn và ít bị chi phối bởi những dao động ngẫu nhiên. Nhờ CLT, các ước lượng trong mô hình có xu hướng hội tụ, sai số trở nên “hiền” hơn, và kết quả không đổi quá mạnh chỉ vì dữ liệu xáo trộn nhẹ. AI không loại bỏ nhiễu; nó học cách sống chung với nhiễu bằng sức mạnh của số đông. Và trong nhiều hệ thống AI ngoài đời thật, chính sự ổn định này mới là thước đo quan trọng: một mô hình tốt không chỉ cần đúng, mà còn cần “bình tĩnh” và lặp lại được khi môi trường thay đổi.
Định lý giới hạn trung tâm trong AI ẩn trong các thuật toán và thư viện cốt lõi
Mini-batch Gradient Descent và định lý giới hạn trung tâm trong AI
Khi một hệ thống AI học từ dữ liệu, nó cần một cách để tự điều chỉnh mình sao cho dự đoán ngày càng tốt hơn. Mỗi lần nhìn vào một mẫu dữ liệu, mô hình nhận được một tín hiệu nhỏ cho biết: nếu thay đổi tham số theo hướng nào thì sai số sẽ giảm. Tín hiệu này được gọi là gradient.
Mini-batch gradient descent hoạt động theo một cách đơn giản hơn: thay vì cập nhật mô hình sau từng mẫu đơn lẻ, hệ thống gom nhóm các mẫu dữ liệu, tính gradient cho từng mẫu, rồi lấy trung bình trước khi điều chỉnh mô hình. Khi nhiều tín hiệu nhỏ được gộp lại, ảnh hưởng của những trường hợp bất thường giảm xuống, còn xu hướng chung của dữ liệu trở nên rõ hơn. Định lý giới hạn trung tâm trong AI đứng phía sau cơ chế này: khi số lượng mẫu trong mỗi mini-batch đủ lớn, gradient trung bình có xu hướng ổn định hơn và phản ánh tốt hơn cấu trúc tổng thể của bài toán.
Nhờ cơ chế đó, mini-batch gradient descent trở thành cách học mặc định trong hầu hết các hệ thống AI. Các mô hình học sâu trong nhận dạng hình ảnh, xử lý giọng nói hay ngôn ngữ đều được huấn luyện bằng việc lặp lại một quy trình quen thuộc: nhìn vào một nhóm dữ liệu nhỏ, điều chỉnh mô hình một chút, rồi tiếp tục. Cơ chế này giúp quá trình học diễn ra đều đặn, ít dao động và đủ ổn định để mô hình có thể vận hành trong một thế giới dữ liệu lớn, nhiễu và luôn thay đổi.
Đánh giá mô hình và cross-validation
Khi một hệ thống AI được huấn luyện xong, việc quan trọng tiếp theo là kiểm tra xem mô hình đó có thực sự đáng tin hay không. Nếu chỉ đánh giá trên một tập dữ liệu kiểm tra duy nhất, kết quả rất dễ bị ảnh hưởng bởi may rủi. Tập test có thể vô tình “dễ” hoặc “khó”. Điều này khiến các chỉ số có thể cao hoặc thấp một cách thiếu ổn định. Dựa vào một con số như vậy để kết luận mô hình tốt hay kém là rất rủi ro.
Cross-validation được dùng để giảm rủi ro đó. Thay vì đánh giá một lần, hệ thống chia dữ liệu thành nhiều phần khác nhau. Mô hình được huấn luyện và kiểm tra lặp đi lặp lại trên các cách chia này. Mỗi lần đánh giá cho ra một kết quả hơi khác nhau. Tuy nhiên, khi lấy trung bình các kết quả đó, sai số trở nên ổn định hơn. Định lý giới hạn trung tâm trong AI đứng phía sau cơ chế này. Khi số lần đánh giá đủ nhiều, trung bình sai số phản ánh khá chính xác chất lượng thật của mô hình.
Cách đánh giá này được sử dụng rộng rãi trong các hệ thống AI thực tế. Ví dụ như chấm điểm tín dụng, phát hiện gian lận, dự đoán rủi ro, hay các mô hình phân loại trong y tế và marketing. Trong các thư viện phổ biến như scikit-learn, cross-validation gần như là bước mặc định khi chọn mô hình hoặc điều chỉnh siêu tham số.
Ensemble và xấp xỉ phân phối chuẩn
Trong thực tế, rất hiếm khi một mô hình AI đơn lẻ được tin tưởng tuyệt đối. Mỗi mô hình đều có điểm mạnh yếu riêng. Chúng cũng có thể mắc sai lệch theo những cách khác nhau. Vì vậy, nhiều hệ thống AI chọn một chiến lược an toàn hơn. Đó là huấn luyện nhiều mô hình cho cùng một bài toán rồi kết hợp kết quả lại.
Cách kết hợp phổ biến nhất là lấy trung bình dự đoán của các mô hình. Khi nhìn vào từng mô hình riêng lẻ, kết quả có thể dao động khá mạnh. Điều này đặc biệt rõ trong những trường hợp dữ liệu khó và nhiều nhiễu. Nhưng khi nhiều dự đoán độc lập được gộp lại, các sai lệch riêng lẻ có xu hướng triệt tiêu. Khi đó, xu hướng chung trở nên rõ ràng hơn. Định lý giới hạn trung tâm trong AI giải thích vì sao cách làm này hiệu quả. Khi nhiều yếu tố ngẫu nhiên nhỏ cùng tác động, kết quả tổng hợp thường ổn định và dễ dự đoán hơn.
Chiến lược ensemble được sử dụng rộng rãi trong các hệ thống AI thực tế. Các hệ thống dự báo thời tiết thường kết hợp kết quả từ nhiều mô hình khác nhau. Trong tài chính và bảo hiểm, nhiều mô hình rủi ro được dùng song song để giảm khả năng đánh giá sai. Ngay cả trong các cuộc thi học máy và các hệ thống gợi ý lớn, ensemble thường là bước cuối cùng trước khi triển khai. Thay vì tin vào một mô hình duy nhất, AI tận dụng sức mạnh của số đông để đưa ra quyết định đáng tin hơn trong một thế giới luôn đầy nhiễu và bất định.
Khi CLT cho phép AI bước ra đời sống
Thể thao: phong độ và thực lực
Trong thể thao, mỗi trận đấu luôn chứa nhiều yếu tố ngẫu nhiên. Một bàn thắng có thể đến từ may mắn. Một sai lầm cá nhân cũng có thể làm đổi cục diện trận đấu. Điều kiện thi đấu như thời tiết hay sân bãi cũng tạo ra ảnh hưởng đáng kể. Vì vậy, việc đánh giá cầu thủ hay đội bóng chỉ trong vài trận đấu rất dễ dẫn đến kết luận sai lệch. Một chuỗi thắng chưa chắc cho thấy đội đang ở đỉnh cao. Trong nhiều trường hợp, đó chỉ là sự trùng hợp của các yếu tố thuận lợi.
Khi dữ liệu được mở rộng trên nhiều trận đấu, bức tranh bắt đầu thay đổi. Những dao động ngẫu nhiên dần bị làm mờ. Xu hướng chung trở nên rõ ràng hơn. Phong độ thật của cầu thủ dần lộ diện. Sự khác biệt giữa thực lực bền vững và những màn bùng nổ ngắn hạn cũng dễ nhận ra hơn. Định lý giới hạn trung tâm đứng phía sau quá trình này. Khi nhiều yếu tố ngẫu nhiên nhỏ được cộng lại, kết quả trung bình trở nên ổn định và đáng tin cậy hơn.
Các hệ thống phân tích thể thao hiện đại vận hành rất hiệu quả nhờ logic đó. Chúng được dùng để đánh giá cầu thủ và xếp hạng đội bóng. Nhiều hệ thống cũng áp dụng để dự đoán kết quả thi đấu. Dữ liệu từ nhiều trận được tổng hợp lại để làm mờ yếu tố may rủi. Nhờ CLT, các ước lượng trở nên ổn định hơn. Từ đó, hệ thống có thể phân biệt được thực lực thật với những chuỗi kết quả nhất thời.
Nghiên cứu thị trường và khảo sát
Trong nghiên cứu thị trường, mỗi người tham gia khảo sát đều mang theo quan điểm cá nhân và cảm xúc nhất thời. Các câu trả lời vì thế luôn chứa những sai lệch khó kiểm soát. Một phản hồi riêng lẻ hiếm khi phản ánh chính xác bức tranh chung của thị trường. Nếu chỉ dựa vào một nhóm nhỏ người trả lời, kết luận rất dễ bị méo mó. Khi đó, những ý kiến cực đoan hoặc ngẫu nhiên có thể chi phối toàn bộ kết quả.
Khi kích thước mẫu đủ lớn, tình hình bắt đầu thay đổi. Những sai lệch cá nhân không còn ảnh hưởng quyết định đến kết quả chung. Xu hướng của thị trường dần trở nên rõ ràng hơn. Trung bình của các phản hồi cũng trở nên ổn định và phản ánh khá sát thực tế. Nhờ định lý giới hạn trung tâm, các doanh nghiệp có thể so sánh hiệu quả chiến dịch marketing. Họ cũng có thể đánh giá mức độ yêu thích sản phẩm hoặc tiến hành A/B testing một cách đáng tin cậy. Chính CLT là nền tảng giúp các hệ thống phân tích hành vi người tiêu dùng đưa ra quyết định dựa trên dữ liệu, thay vì chỉ dựa vào cảm giác hoặc một vài phản hồi nổi bật.
Dự báo thời tiết và mô hình ensemble
Dự báo thời tiết là một trong những bài toán nhiều nhiễu nhất ngoài đời thật. Các mô hình vật lý khác nhau thường đưa ra những dự đoán khác nhau. Chỉ cần cách mô tả khí quyển hoặc điều kiện ban đầu hơi lệch đi một chút, kết quả đã có thể thay đổi đáng kể.
Vì vậy, các hệ thống dự báo hiện đại hiếm khi đặt niềm tin vào một mô hình duy nhất. Thay vào đó, chúng chạy nhiều mô hình song song. Sau đó, các kết quả được kết hợp lại với nhau.
Nếu nhìn vào từng dự báo riêng lẻ, sai số có thể khá lớn. Trong một số trường hợp, sai số còn trở nên rất cực đoan. Nhưng khi lấy trung bình kết quả của nhiều mô hình, những sai lệch riêng lẻ có xu hướng triệt tiêu. Khi đó, xu hướng chung trở nên rõ ràng hơn.
Định lý giới hạn trung tâm giải thích vì sao cách dự báo kiểu ensemble lại hiệu quả. Các kết quả tổng hợp thường ổn định hơn. Chúng cũng ít bị chi phối bởi những dự đoán “quá tay”.
Nhờ cơ chế này, các hệ thống dự báo thời tiết có thể cung cấp thông tin đáng tin cậy hơn. Những thông tin đó được dùng để phục vụ đời sống. Chúng cũng hỗ trợ sản xuất và phòng tránh thiên tai, dù thế giới tự nhiên luôn đầy bất định.
Kết luận
Nếu nhìn kỹ, định lý giới hạn trung tâm trong AI không phải là một kiến thức “đẹp để biết”, mà là nền tảng để hệ thống học từ dữ liệu không hoàn hảo. Nó giúp AI tận dụng sức mạnh của số đông: gom nhiều mảnh ngẫu nhiên nhỏ để tạo ra một kết quả ổn định, đủ đáng tin để dùng ngoài đời thật.


