Hồi quy tuyến tính là phương pháp dùng để mô tả và phân tích mối quan hệ giữa một biến phụ thuộc và một hoặc nhiều biến độc lập. Thông qua mô hình hồi quy, ta có thể ước lượng hệ số, đánh giá mức độ giải thích của mô hình, phân tích phần dư, kiểm tra giả định của mô hình và thực hiện dự đoán.
I. Giới thiệu về hồi quy tuyến tính
Chúng ta đã học về hệ số tương quan để đánh giá mức độ liên hệ giữa hai biến ngẫu nhiên. Tuy nhiên, tương quan chỉ cho biết hai biến có cùng biến thiên hay không, mạnh hay nhẹ, và mối quan hệ đó mang tính đối xứng: không có biến nào quan trọng hơn.
Trong nhiều bài toán thực tế, ta cần một cách tiếp cận khác: mô tả sự phụ thuộc của một biến vào một (hay nhiều) biến khác. Chẳng hạn ta có thể hình dung trực giác đơn giản thế này:
- Y = 2X +3 ⇒ biến Y phụ thuộc vào X, vì từ giá trị X ta có thể biết giá trị của Y
- Y = 2X1 +3X2 – 1 ⇒ biến Y phụ thuộc vào X1 , X2 , vì từ giá trị X1 , X2 có thể biết giá trị của Y
Ở đây, ta muốn trả lời những câu hỏi như: khi một biến thay đổi một đơn vị, thì biến phụ thuộc sẽ thay đổi bao nhiêu; và ảnh hưởng đó còn giữ nguyên hay không khi các yếu tố khác được đồng thời xét đến.
Không giống tương quan, hồi quy thiết lập một mối quan hệ có hướng, trong đó một biến được chọn làm biến kết quả (biến phụ thuộc) , còn các biến khác đóng vai trò giải thích (biến độc lập).
Nhờ đó, hồi quy không chỉ phát hiện mối liên hệ, mà còn lượng hóa và mô hình hóa mối quan hệ đó dưới dạng một hàm toán học. ⇒ Hồi quy là công cụ để: giải thích, dự đoán, hỗ trợ ra quyết định.
II. Hồi quy tuyến tính đơn
1. Mô hình hồi quy tuyến tính đơn
Hồi quy tuyến tính đơn xem xét mối quan hệ giữa hai biến: biến phụ thuộc và biến độc lập . Mô hình được viết dưới dạng:
Y = β0 + β1X + ε
Trong đó :
- β0 (hệ số chặn): là giá trị dự đoán của khi X = 0. Về mặt hình học, đây là điểm mà đường thẳng cắt trục tung.
- β1(hệ số góc): cho biết khi X tăng thêm 1 đơn vị, thì Y thay đổi bao nhiêu đơn vị. Nó thể hiện độ dốc của đường thẳng. Dấu của cho biết chiều hướng β1 của mối liên hệ.
- ε (epsilon): Sai số ngẫu nhiên. Đại diện cho tất cả các yếu tố khác ảnh hưởng đến Y. Không có mô hình nào là hoàn hảo, và ε chính là sự không hoàn hảo đó.
2. Ví dụ về hồi quy tuyến tính đơn
Giả sử khi phân tích một tập dữ liệu về nhân trắc học, ta thu được phương trình hồi quy tuyến tính đơn như sau
Y = -40 + 0.6XTrong đó X là chiều cao (cm), Y là cân nặng (kg). Hệ số góc 0.6 cho biết: khi chiều cao tăng 1 cm thì cân nặng tăng trung bình 0.6 kg. Hệ số chặn −40 là giá trị kỹ thuật của mô hình, vì X = 0 không có ý nghĩa thực tế.
Phương trình hồi quy cho thấy tồn tại mối quan hệ tuyến tính dương giữa chiều cao và cân nặng.
3. Mối liên hệ giữa hồi quy đơn và hệ số tương quan
Hồi quy tuyến tính đơn và hệ số tương quan có mối liên hệ chặt chẽ, nhưng không đồng nhất.
- Nếu hệ số tương quan r>0 thì β1 >0
- Nếu r < 0 thì β1 <0
- Nếu r = 0 thì β1 = 0
Nói cách khác, dấu của hệ số hồi quy trùng với dấu của hệ số tương quan.
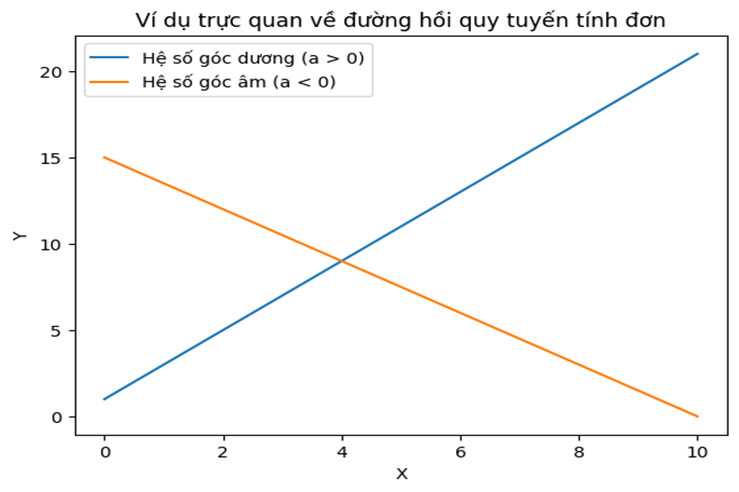
Tuy nhiên, tương quan chỉ đo mức độ liên hệ, còn hồi quy cho ta 1 mô hình cụ thể để mô tả và dự đoán. Có thể xem tương quan là “báo hiệu” mối liên hệ, còn hồi quy là để lượng hóa mối liên hệ đó.
III. Hồi quy tuyến tính bội
1. Mô hình hồi quy tuyến tính bội
Trong thực tế, hiếm khi một biến chỉ chịu ảnh hưởng bởi đúng một yếu tố. Hồi quy tuyến tính bội mở rộng hồi quy đơn bằng cách đưa nhiều biến độc lập vào cùng một mô hình:
Y = β0 + β1 X1 + β2 X2 + ⋯ + ε
Mỗi biến Xi đại diện cho một yếu tố có thể ảnh hưởng đến . Mô hình hồi quy bội cho phép ta xem xét tác động đồng thời của các yếu tố này, thay vì nhìn từng yếu tố một cách rời rạc.
Hệ số βi được diễn giải như sau: Khi tăng 1 đơn vị, thì thay đổi trung bình đơn vị, trong khi các biến độc lập khác được giữ không đổi. Nhờ đó, mỗi hệ số phản ánh ảnh hưởng riêng của từng biến, đã loại trừ tác động của các biến còn lại trong mô hình.
2. Ví dụ về hồi quy tuyến tính bội
Sau khi phân tích dữ liệu, ta được phương trình:
Y = 80 + 0.6X1 + 1.2X2
Trong đó :
- Y là huyết áp tâm thu , X1 là Tuổi , X2 là chỉ số BMI
- Khi tuổi tăng thêm 1 năm và BMI không đổi → huyết áp tâm thu tăng trung bình 0.6 mmHg
- Khi BMI tăng thêm 1 đơn vị và tuổi không đổi → huyết áp tâm thu tăng trung bình 1.2 mmHg
- Hồi quy bội cho phép ta xem xét ảnh hưởng đồng thời của nhiều yếu tố lên .
2. So sánh hồi quy đơn và hồi quy bội
- Hồi quy đơn: đơn giản, trực quan, dễ minh họa nhưng dễ bị ảnh hưởng bởi yếu tố gây nhiễu.
- Hồi quy bội: phản ánh thực tế tốt hơn, cho phép kiểm soát nhiều yếu tố nhưng đòi hỏi diễn giải cẩn trọng hơn.
IV. Ước lượng và kiểm định trong hồi quy
1. Nguyên lý bình phương tối thiểu
Về mặt ý tưởng, hồi quy tuyến tính tìm một đường thẳng sao cho tổng bình phương các sai lệch giữa giá trị quan sát và giá trị dự đoán là nhỏ nhất. Nguyên lý này được gọi là bình phương tối thiểu (Ordinary Least Squares – OLS).
Trong thực hành, chúng ta không tự tính toán các công thức OLS, mà sử dụng phần mềm (Python) để thực hiện việc ước lượng theo nguyên lý này.
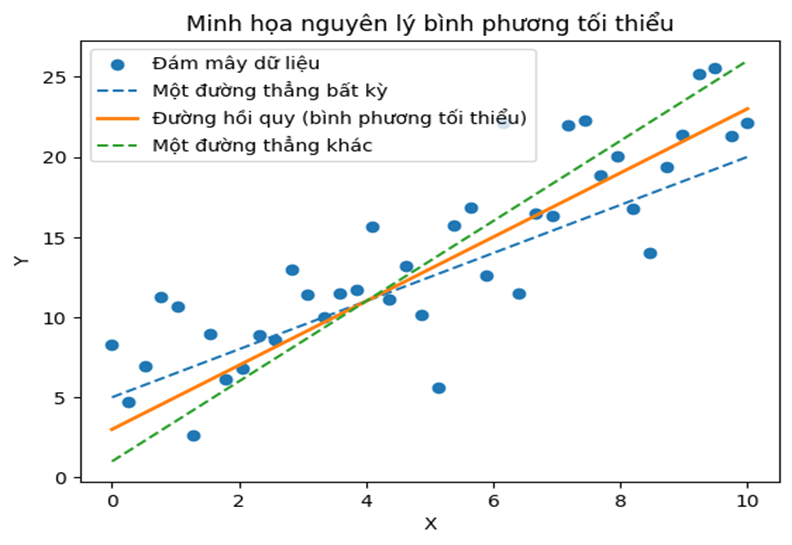
Việc lấy bình phương sẽ giúp: triệt tiêu sai số dương – âm và khuyết đại những sai lệch lớn.
Đường hồi quy thu được không nhất thiết phải đi qua mọi điểm dữ liệu, mà là đường “ở gần dữ liệu nhất” theo nghĩa thống kê.
2. Ước lượng các hệ số hồi quy
Giả sử mô hình hồi quy tuyến tính đơn có dạng: Y = β0 + β1X + ε
Trong Python, các hệ số hồi quy ước lượng nằm trong: model.params sau khi chạy mô hình. Ví dụ:
import statsmodels.api as sm
import numpy as np
X = np.array([150, 155, 160, 165, 170, 175])
y = np.array([50, 52, 55, 58, 62, 65])
X = sm.add_constant(X) # thêm hệ số chặn
model = sm.OLS(y, X).fit()
print("params=", model.params)Kết quả: ⇒ params = [-43.28571429 0.61714286]
Trong đó:
- model.params[0] = -43.2857 là ước lượng của β₀
- model.params[1] = 0.6171 là ước lượng của β₁
Các hệ số này được tính từ mẫu, nên chỉ là giá trị ước lượng, không phải giá trị chính xác của tổng thể.
3. Sai số chuẩn của ước lượng (Standard Error)
Sai số chuẩn là gì
Mỗi hệ số hồi quy đều đi kèm một sai số chuẩn, phản ánh mức độ không chắc chắn của ước lượng.
Trong Python, sai số chuẩn của các hệ số nằm trong: model.bse ( beta standard error). Ví dụ:
import statsmodels.api as sm
import numpy as np
X = np.array([150, 155, 160, 165, 170, 175])
y = np.array([50, 52, 55, 58, 62, 65])
X = sm.add_constant(X) # thêm hệ số chặn
model = sm.OLS(y, X).fit()
print("Sai số chuẩn của các tham số=", model.bse)Kết quả: ⇒ Sai số chuẩn của các tham số= [4.55532879 0.02799417]
Trong đó:
- model.bse[0] = 4.55532879 là sai số chuẩn của β₀
- model.bse[1] = 0.02799417 là sai số chuẩn của β₁
Trong bảng kết quả của hàm model.summary() có cột std err chính là sai số chuẩn của các hệ số hồi quy.
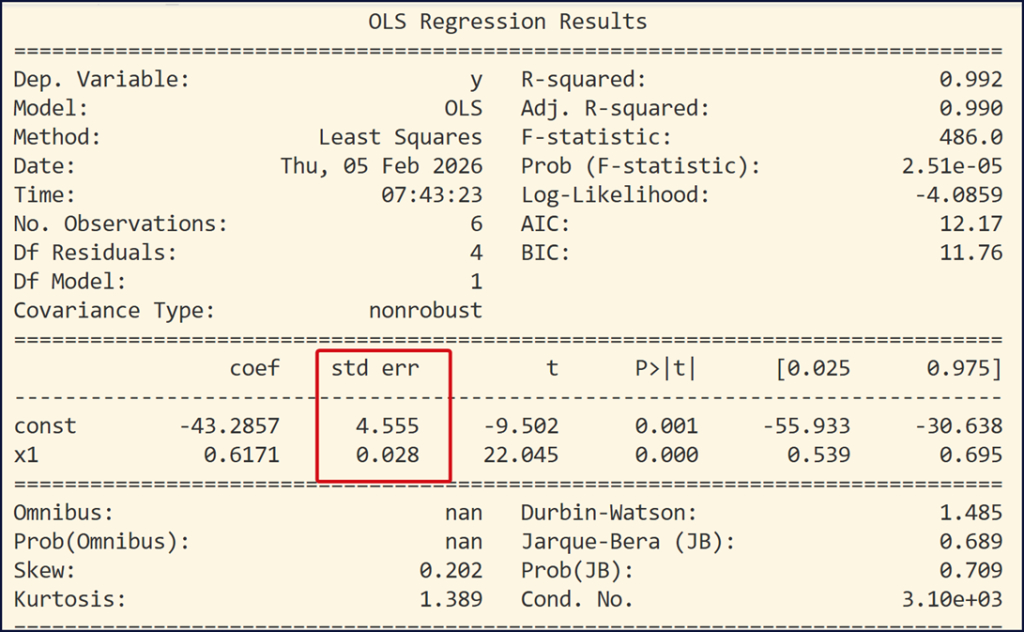
Giá trị lớn – nhỏ của sai số chuẩn là căn cứ vào đâu?
Sai số chuẩn nhỏ cho biết hệ số ước lượng ổn định hơn. Còn nếu sai số chuẩn lớn thì hệ số kém chắc chắn, có thể do mẫu nhỏ hoặc đa cộng tuyến.
Để biết sai số là lớn hay nhỏ, chúng ta căn cứ vào chính giá trị của tham số hồi quy βi . Ví dụ β1 ≈ 0.6 trong khi sai số của nó là 0.028 , đây là sai số nhỏ, cho thấy ước lượng là tương đối ổn định .
Giải thích rõ về sai số chuẩn:
- Về mặt toán học, sai số chuẩn chính là độ lệch chuẩn (là căn bậc hai phương sai). Nhưng ở đây chúng ta đang ước lượng. Cho nên gọi khác tên để phân biệt với độ lệch chuẩn của dữ liệu.
- Sai số chuẩn của một hệ số hồi quy tức là đo mức độ dao động của ước lượng đó nếu ta lấy mẫu khác. Nếu ta lấy nhiều mẫu khác nhau từ cùng một tổng thể và ước lượng β₁ nhiều lần, thì sai số chuẩn cho biết các giá trị đó dao động mạnh hay nhẹ. Nếu dao động ít thì sai số chuẩn nhỏ, nếu dao động nhiều thì sai số chuẩn lớn
4. Kiểm định ý nghĩa hệ số hồi quy
Câu hỏi quan trọng trong hồi quy là: biến X có thực sự ảnh hưởng đến Y hay không? Điều này được kiểm tra thông qua giả thuyết:
- H₀: β₁ = 0 (X không ảnh hưởng đến Y)
- H₁: β₁ ≠ 0
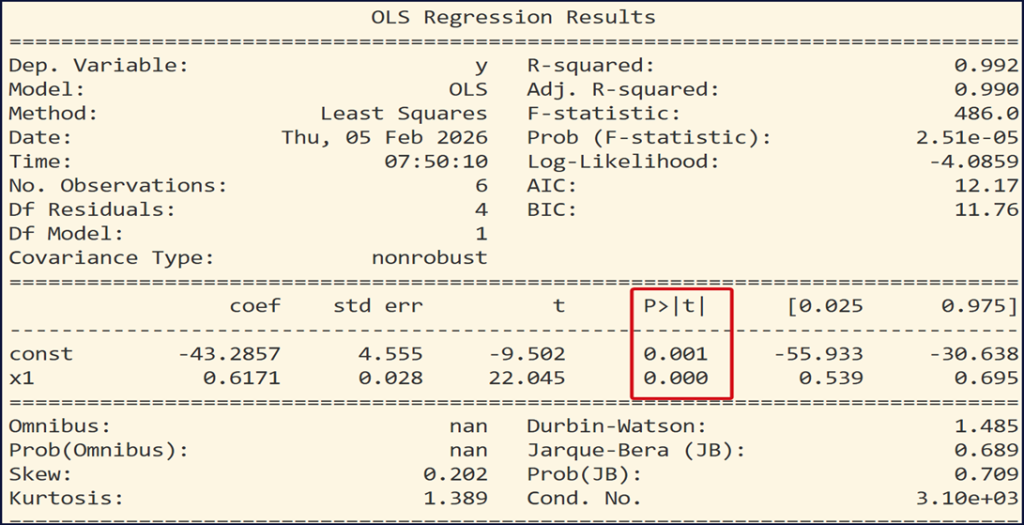
Trong Python, p-value của từng hệ số nằm trong: model.pvalues
import statsmodels.api as sm
import numpy as np
X = np.array([150, 155, 160, 165, 170, 175])
y = np.array([50, 52, 55, 58, 62, 65])
X = sm.add_constant(X) # thêm hệ số chặn
model = sm.OLS(y, X).fit()
print("Giá trị p-value của các tham số=", model.pvalues )
print(model.summary())Kết quả: ⇒ Giá trị p-value của các tham số = [0.0006846 0.0000251 ]
Tức là giá trị p-value của β₀ là 0.0006846 , p-value của tham số β₁ là 0.0000251
Cách ra quyết định:
- p-value < 0.05 → bác bỏ H₀ → biến X có ảnh hưởng đến Y
- p-value ≥ 0.05 → chưa đủ bằng chứng để kết luận X ảnh hưởng đến Y
Trong bảng kết quả của hàm model.summary(), cột P>|t| chính là p-value của từng hệ số hồi quy.
V. Đánh giá mô hình hồi quy
1. Hệ số xác định R2
Sau khi xây dựng mô hình hồi quy, câu hỏi đặt ra là: Mô hình giải thích được dữ liệu ở mức độ nào? Bao nhiêu phần trăm? Hệ số xác định R² được dùng để trả lời câu hỏi này.
R² đo lường tỷ lệ biến thiên của biến phụ thuộc Y được mô hình hồi quy giải thích thông qua các biến độc lập.
Về mặt giá trị:
- R² = 0: mô hình không giải thích được biến thiên của Y
- R² = 1: mô hình giải thích hoàn toàn biến thiên của Y
- 0 < R² < 1: mô hình giải thích được một phần dữ liệu
Do đó, R² càng lớn, khả năng giải thích của mô hình đối với Y càng cao, và đây là chỉ số đầu tiên thường được xem xét khi đánh giá mô hình hồi quy.
Code Python lấy và xem giá trị R²
import statsmodels.api as sm
import numpy as np
# Ví dụ dữ liệu
X = np.array([150, 155, 160, 165, 170, 175])
y = np.array([50, 52, 55, 58, 62, 65])
X = sm.add_constant(X) # thêm hệ số chặn
model = sm.OLS(y, X).fit()
print("R² =", model.rsquared)Kết quả: ⇒ R² = 0.9918367346938776
Tuy nhiên, dùng R² cũng có hạn chế: đó là khi thêm biến độc lập vào mô hình thì giá trị R² gần như luôn tăng, kể cả khi biến mới không thực sự có ý nghĩa. Vì vậy, R² không nên được dùng như tiêu chí duy nhất để đánh giá chất lượng mô hình, mà cần được kết hợp với các chỉ số và chẩn đoán khác.
2. Hệ số xác định R² hiệu chỉnh (Adjusted R²)
Như trên đã đề cập, R² hầu như luôn tăng khi thêm biến vào mô hình, ngay cả khi biến mới không thực sự có ích trong việc giải thích Y. Điều này khiến R² có thể đánh giá quá lạc quan mức độ phù hợp của mô hình.
Để khắc phục hạn chế đó, người ta sử dụng hệ số xác định hiệu chỉnh (Adjusted R²). Chỉ số này điều chỉnh giá trị R² bằng cách tính đến số biến độc lập trong mô hình và kích thước mẫu, do đó phản ánh tốt hơn mức độ giải thích thực chất của mô hình.
Một số điểm cần lưu ý:
- Adjusted R² có thể giảm khi thêm một biến mới không cần thiết
- Adjusted R² chỉ tăng khi biến mới giúp cải thiện mô hình đủ mức
- Adjusted R² phù hợp hơn để so sánh các mô hình có số biến khác nhau trên cùng một bộ dữ liệu
Vì vậy, trong thực hành hồi quy bội, Adjusted R² thường được ưu tiên hơn R² khi đánh giá và so sánh mô hình.
Code lấy và xem giá trị Asjusted R² như sau:
import statsmodels.api as sm
import numpy as np
# Ví dụ dữ liệu
X = np.array([150, 155, 160, 165, 170, 175])
y = np.array([50, 52, 55, 58, 62, 65])
X = sm.add_constant(X) # thêm hệ số chặn
model = sm.OLS(y, X).fit()
print("Adjusted R² =", model.rsquared_adj )=> Kết quả: Adjusted R² = 0.9897959183673469
3. Phân tích phần dư
Phần dư là gì
Sau khi ước lượng mô hình hồi quy, tại mỗi quan sát ta có thể tính phần dư theo công thức: ei = yi – ŷi trong đó yi là giá trị quan sát và ŷi là giá trị dự đoán từ mô hình.
Phần dư là phần lệch. Tập hợp các phần dư cho ta thông tin quan trọng về mức độ phù hợp của mô hình.
Vai trò của phân tích phần dư
Phân tích phần dư là nhằm kiểm tra xem mô hình hồi quy đã mô tả đúng mối quan hệ giữa X và Y hay chưa. Trong một mô hình hồi quy phù hợp, các phần dư thường có những đặc điểm sau:
- Có giá trị trung bình xấp xỉ 0
- Phân tán ngẫu nhiên quanh 0
Nếu phần dư có quy luật rõ ràng, mô hình có thể chưa phản ánh đúng dữ liệu. Ví dụ như xu hướng tăng, dạng cong hoặc độ phân tán thay đổi.
Ý nghĩa của phần dư
Nói một cách nôm na, ε không thể quan sát trực tiếp. Vì vậy, trong thực hành, người ta dùng phần dư để đánh giá các giả định về ε.
Y = β0 + β1X + ε
Y = β0 + β1X1 + β2X2 + ⋯ + ε
để xem phần dư (đại diện cho ε ) có dao động xấp xỉ quanh 0 hay không
Lấy các giá trị phần dư
Trong tính toán với Python, phần dư là mảng numpy resid sau khi chạy mô hình:
import statsmodels.api as sm
X = sm.add_constant(X) # thêm hằng số
model = sm.OLS(y, X).fit()
print(model.resid)⇒ [ 1.25 -0.43 0.87 -1.12 0.05 -0.76 0.34 1.01 -0.58 0.22 ]
Mỗi giá trị trong mảng tương ứng với phần dư của một quan sát
Quan sát phân phối của phần dư
Ta không chỉ xem phần dư dao động quanh 0. Phân phối của phần dư cũng giúp đánh giá mức độ phù hợp của mô hình.
Một cách trực quan là vẽ histogram . Nếu phần dư quanh 0 và gần hình chuông, giả định phân phối chuẩn của sai số được chấp nhận. Trong Python, histogram vẽ như sau:
import matplotlib.pyplot as plt
residuals = model.resid
plt.hist(residuals, bins=25, density=True)
plt.axvline(0)
plt.show()Nói nôm na, nếu phần dư vừa dao động ngẫu nhiên quanh 0, vừa phân phối gần chuẩn, thì mô hình hồi quy được xem là mô tả tốt dữ liệu .
Một công cụ trực quan khác thường được sử dụng là biểu đồ Q–Q plot (Quantile–Quantile plot). Biểu đồ này so sánh phân phối của phần dư với phân phối chuẩn. Trong Python, Q–Q plot của phần dư được vẽ bằng lệnh sau:
import scipy.stats as stats
import matplotlib.pyplot as plt
residuals = model.resid
stats.probplot(residuals, dist="norm", plot=plt)
plt.title("Q–Q plot của phần dư")
plt.show()Cách đọc Q–Q plot:
- Nếu các điểm nằm gần đường thẳng, có thể xem phần dư phân phối gần chuẩn. Vì vậy mô hình là chấp nhận được.
- Nếu các điểm lệch xa khỏi đường thẳng (cong, lệch hoặc có đuôi dài). Điều đó cho thấy phần dư không tuân theo phân phối chuẩn, mô hình có thể chưa phù hợp.
Code đầy đủ demo cả 2 công cụ
import statsmodels.api as sm
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
# Tạo dữ liệu đủ lớn để histogram mượt
np.random.seed(0)
X = np.random.normal(160, 10, 1000)
y = 0.6*X - 40 + np.random.normal(0, 2, 1000)
# Ước lượng mô hình hồi quy
X = sm.add_constant(X)
model = sm.OLS(y, X).fit()
# Lấy phần dư
residuals = model.resid
# Vẽ histogram phần dư (chuẩn hoá mật độ)
plt.figure()
plt.hist(residuals, bins=25, density=True)
plt.axvline(0)
plt.xlabel("Phần dư")
plt.ylabel("Mật độ")
plt.title("Histogram của phần dư (dạng hình chuông rõ)")
# Vẽ đường phân phối chuẩn để so sánh
x = np.linspace(residuals.min(), residuals.max(), 300)
plt.plot(x, stats.norm.pdf(x, np.mean(residuals), np.std(residuals)))
plt.show()
# Vẽ Q–Q plot của phần dư
stats.probplot(residuals, dist="norm", plot=plt)
plt.title("Q–Q plot của phần dư")
plt.show()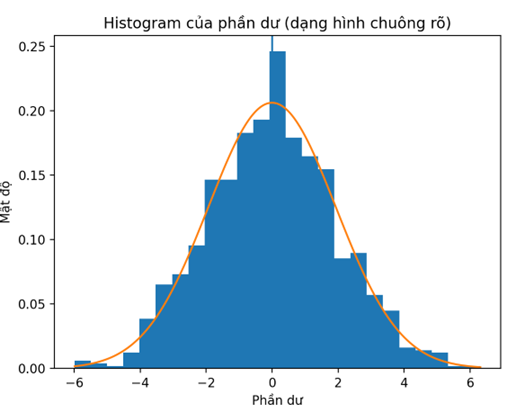
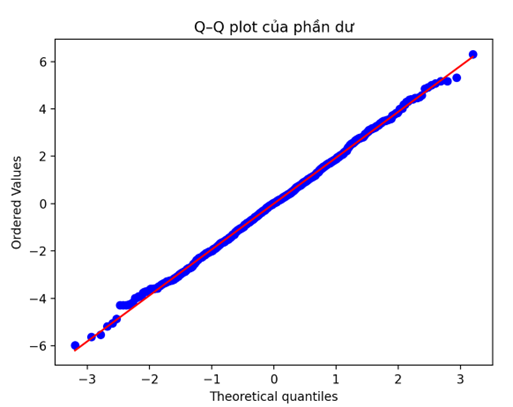
Tại sao cần vẽ Histogram và Q–Q plot?
- Vì mỗi cái có vai trò khác nhau: Histogram trả lời câu hỏi: Phân phối có giống hình chuông không? Q–Q plot cho biết Phân phối có thực sự gần chuẩn không?
- Trong thực tế: Histogram nhìn tổng quan. Q-Q plot kiểm tra chính xác hơn Q–Q plot cho kết luận đáng tin cậy hơn histogram
- Chỉ cần vẽ Q–Q plot là đủ để đánh giá phần dư có phân phối chuẩn hay không. Không cần histogram. Q–Q plot kiểm tra mạnh hơn histogram.
- Histogram có hạn chế là phụ thuộc vào: số bins. Số này ảnh hưởng đến độ rộng bins, dễ đánh lừa thị giác
4. Đa cộng tuyến trong hồi quy bội: khái niệm và hệ quả
Trong hồi quy bội, có thể xuất hiện tình huống là tồn tại vài biến độc lập có liên hệ chặt chẽ với nhau. Hiện tượng này được gọi là đa cộng tuyến.
Đa cộng tuyến không làm giảm khả năng dự đoán của mô hình, nhưng làm cho việc ước lượng và diễn giải các hệ số hồi quy trở nên khó khăn. Vì các biến không còn độc lập, dẫn đến sai số chuẩn của các hệ số tăng lên.
Vì vậy, khi làm hồi quy bội, cần cảnh giác với đa cộng tuyến (quan sát ma trận tương quan).
VI. Dự đoán bằng hồi quy
1. Giá trị dự đoán từ mô hình hồi quy tuyến tính
Sau khi xây dựng mô hình hồi quy, một ứng dụng quan trọng là dự đoán.
Với một giá trị cụ thể của biến độc lập X = x0, ta có thể thay vào phương trình hồi quy để thu được giá trị dự đoán của Y.
Giá trị này là giá trị dự đoán trung bình, phản ánh xu hướng chung của dữ liệu theo mô hình hồi quy. Tuy nhiên, do mô hình được ước lượng từ mẫu và dữ liệu luôn có nhiễu ngẫu nhiên, nên giá trị dự đoán này không chắc chắn tuyệt đối.
Vì vậy, khi dự đoán trong thực tế, ta không chỉ quan tâm đến một con số duy nhất, mà cần quan tâm đến một khoảng giá trị hợp lý mà Y có thể rơi vào.
2. Khoảng dự đoán cho quan sát mới
Có một thức được gọi là khoảng dự đoán. Mục tiêu là dự đoán giá trị của một quan sát cụ thể tại X = x0 . Khoảng dự đoán trả lời câu hỏi: “Nếu quan sát mới có X = x0 , thì giá trị Y của tương ứng có thể nằm trong khoảng nào, với một mức tin cậy cho trước?”
Do đó, khoảng dự đoán phản ánh đúng rủi ro khi đưa ra dự báo cho một quan sát cụ thể.
3. Lấy giá trị dự đoán và khoảng dự đoán bằng OLS (Python)
Giả sử ta đã ước lượng mô hình hồi quy bằng OLS và muốn dự đoán tại X = x0. Ví dụ với statsmodels:
import statsmodels.api as sm
import numpy as np
# Dữ liệu ban đầu
X = np.array([150, 155, 160, 165, 170, 175]) # biến độc lập
y = np.array([50, 52, 55, 58, 62, 65]) # biến phụ thuộc
# Thêm cột hằng số để ước lượng hệ số chặn
X = sm.add_constant(X)
# Ước lượng mô hình hồi quy tuyến tính bằng OLS
model = sm.OLS(y, X).fit()
# Giá trị X cụ thể cần dự đoán
x0 = 168
# Chuẩn bị giá trị X = x0 để thay vào phương trình hồi quy Y = β0 + β1 X
X_new = np.array([[1, x0]])
# Lấy kết quả dự đoán tại X = x0
pred = model.get_prediction(X_new)
# Bảng kết quả dự đoán
print(pred.summary_frame())Bảng kết quả trả về bao gồm:

- mean = 60.39: là giá trị Y mà mô hình dự đoán khi X = x0.
- mean_se =0.2843 là sai số chuẩn của giá trị dự đoán. Hiểu đơn giản: đây là độ dao động của giá trị dự đoán nếu ta lấy mẫu nhiều lần.
- mean_ci_lower, mean_ci_upper: [59.60 ; 61.18] là khoảng tin cậy . Khoảng tin cậy trả lời câu hỏi: “Giá trị trung bình mà mô hình dự đoán tại X = x₀ có thể nằm trong khoảng nào?”
- obs_ci_lower, obs_ci_upper: [58.587022 ; 62.201549] khoảng dự đoán. Mỗi khoảng dự đoán tương ứng với một quan sát mới tại giá trị X = x0. Nếu quan sát có X = x₀, thì giá trị Y của có thể rơi vào khoảng từ 58.59 đến 62.20.
VII. Tổng kết
Hồi quy tuyến tính là công cụ trung tâm của thống kê ứng dụng, cho phép mô tả, suy luận và dự đoán mối quan hệ giữa các biến trong điều kiện có ngẫu nhiên.
Hồi quy tuyến tính đơn giúp làm rõ bản chất mối quan hệ giữa hai biến, trong khi hồi quy tuyến tính bội cho phép phân tích đồng thời nhiều yếu tố và phản ánh thực tế tốt hơn.
Quan trọng hơn, hồi quy không chỉ là một tập hợp công thức, mà là một cách tư duy thống kê: xem dữ liệu như kết quả của cả yếu tố xác định và yếu tố ngẫu nhiên, và luôn diễn giải kết quả trong bối cảnh bất định.
Các em có thể đọc thêm tài liệu: Linear regression – Wikipedia , Linear regression | Definition, Formula, & Facts | Britannica


